

Abstract
Recent genetic data can offer important insights into the roles of lipoprotein subfractions and particle sizes in preventing coronary artery disease (CAD), as previous observational studies have often reported conflicting results. In this study, we first used the LD score regression to estimate the genetic correlation of 77 subfraction traits with traditional lipid profile and identified 27 traits that may involve distinct genetic mechanisms. We then used Mendelian randomization (MR) to estimate the causal effect of these traits on the risk of CAD. In univariable MR, the concentration and content of medium high-density lipoprotein (HDL) particles showed a protective effect against coronary artery disease. The effect was not attenuated in multivariable MR that adjusted for traditional lipid profile. The multivariable MR analyses also found that small HDL particles and smaller mean HDL particle diameter may have a protective effect. We identified four genetic markers for HDL particle size and CAD.
1 Introduction
Lipoprotein subfractions have been increasingly studied in epidemiological research and used in clinical practice to predict the risk of cardiovascular diseases (CVD) [1–3]. Several studies have identified potentially novel subfraction predictors for CVD [2, 4–8] and demonstrated that the addition of subfraction measurements can significantly improve the risk prediction for CVD [1, 9–11]. However, these observational studies often provide conflicting evidence on the precise roles of the lipoprotein subfractions. For example, while some studies suggested that small, dense low-density lipoprotein (LDL) particles may be more atherogenic [4, 12], others found that larger LDL size is associated with higher CVD risk [13, 14]. Some recent observational studies found that the inverse association of CVD outcomes with smaller high-density lipoprotein (HDL) particles is stronger than the association with larger HDL particles [6, 11, 15, 16], but other studies reached the opposite conclusion in different cohorts [17, 18]. Currently, the utility of lipoprotein subfractions or particle sizes in routine clinical practice remains controversial [14, 19–21], as there is still a great uncertainty about their causal roles in CVD, largely due to a lack of intervention data [21].
Mendelian randomization (MR) is an useful causal inference method that avoids many common pitfalls of observational cohort studies [22]. By using genetic variation as instrumental variables, MR asks if the genetic predisposition to a higher level of the exposure (in this case, lipoprotein subfractions) is associated with higher occurrences of the disease outcome [23]. A positive association suggests a causally protective effect of the exposure if the genetic variants satisfy the instrumental variable assumptions [23, 24]. Since Mendelian randomization can provide unbiased causal estimate even when there are unmeasured confounders, it is generally considered more credible than other non-randomized designs and is quickly gaining popularity in epidemiological research [25, 26]. MR has been used to estimate the effect of several metabolites on CVD, but most prior studies are limited to just one or a few risk exposures at a time [27, 28].
In this study, we will use recent genetic data to investigate the roles of lipid and lipoprotein traits in the occurrence of coronary artery disease (CAD) and myocardial infarction (MI). In particular, we are interested in discovering lipoprotein subfractions that may be causal risk factors for CAD and MI in addition to the traditional lipid profile (LDL cholesterol, HDL cholesterol, and triglycerides levels). To this end, we will first estimate the genetic correlation of the lipoprotein subfractions and particle sizes with the tradition risk factors and remove the traits that have a high genetic correlation. We will then use MR to estimate the causal effects of the selected lipoprotein subfractions and particle sizes on CAD and MI. Finally, we will explore potential genetic markers for the identified lipoprotein and subfraction traits.
2 Materials and Methods
GWAS summary datasets and lipoprotein particle measurements
Table 1 describes all GWAS summary datasets used in this study, including two GWAS of the traditional lipid risk factors [29, 30], two recent GWAS of the human lipidome [31, 32], and three GWAS of CAD or MI [33–35]. In the two GWAS of the lipidome [31, 32], high-throughput nuclear magnetic resonance (NMR) spectroscopy was used to measure the circulating lipid and lipoprotein traits [36]. We investigated the 82 lipid and lipoprotein traits measured in these studies that are related to very-low-density lipoprotein (VLDL), LDL, intermediatedensity lipoprotein (IDL) and HDL subfractions and particle sizes. All the subfraction traits are named with three components that are separated by hyphens: the first component indicates the size (XS, S, M, L, XL, XXL); the second component indicates the fraction according to the lipoprotein density (VLDL, LDL, IDL, HDL); the third component indicates the measurement (C for total cholesterol, CE for cholesterol esters, FC for free cholesterol, L for total lipids, P for particle concentration, PL for phospholipids, TG for triglycerides). For example, M-HDL-P refers to the concentration of medium HDL particles.
Information about the GWAS summary datasets used in this article. The columns are the phenotypes reported by the GWAS studies, the consortium or name of the first author of the publication, PubMed ID, population, sample size, other GWAS datasets with other lapping sample, and URLs we used to download the datasets.
Aside from the concentration and content of lipoprotein subfractions, the two lipidome GWAS also measured the traditional lipid traits (TG, LDL-C, HDL-C), the average diameter of the fractions (VLDL-D, LDL-D, HDL-D) and the concentration of apolipoprotein A1 (ApoA1) and apolipoprotein B (ApoB). A full list of the lipoprotein measurements investigated in this article can be found in Appendix 1.
Genetic correlation and phenotypic screening
Genetic correlation is a measure of association between the genetic determinants of two phenotypes. It is generally different from epidemiological correlation that is estimated from cross-sectional data. In this study, we applied the LD-score regression [37] to the lipidome GWAS [31, 32] to estimate the genetic correlations between the lipoprotein subfractions, particle sizes, and traditional risk factors. We then removed lipoprotein subfractions and particle sizes that are strongly correlated with the traditional risk factors, defined as an estimated genetic correlation ¿ 0.8 with TG, LDL-C, HDL-C, ApoB, or ApoA1 in the GWAS published by Davis et al. [31]. Because these traits are largely co-determined with the traditional risk factors, they do not represent independent biological mechanisms and may lead to multicollinearity issues in multivariate MR analyses. Finally, we obtained an independent estimate of the genetic correlations between the selected traits by applying the LD score regression to the GWAS published by Kettunen et al. [32]. We used Bonferroni’s procedure to correct for multiple testing (familywise error rate at 0.05).
Three-sample Mendelian randomization design
For Mendelian randomization, we employed a three-sample design [38] in which one GWAS was used to select independent genetic instruments that are associated with one or several lipoprotein measures. The other two GWAS were then used to obtain summary associations of the selected SNPs with the exposure and the outcome, as in a typical two-sample MR design [39, 40]. More specifically, the selection GWAS was used to create a set of SNPs that are in linkage equilibrium with each other in a reference panel (distance > 10 megabase pairs, r2 < 0.001). This was done by ordering the SNPs by the p-values of their association with the trait(s) under investigation and then selecting them greedily using the linkage-disequilibrium (LD) clumping function in the PLINK software package [41]. To avoid winner’s curse, we require the other two GWAS to have no overlapping sample with the selection GWAS.
As the GWAS published by Davis et al. [31] has a smaller sample size, we used it to select the genetic instruments so the larger dataset can be used for statistical estimation. In univariable MR, associations of the selected SNPs with the exposure trait (a lipoprotein subfraction or a particle size trait) were obtained from the GWAS published by Kettunen et al. [32] and the associations with MI were obtained using summary data from an interim release of UK BioBank [35]. To maximize the statistical power, we used the so-called “genome-wide MR” design and do not truncate the list of SNPs according to their p-values. More details about this design can be found in a previous methodological article [38].
To control for potential pleiotropic effects via the traditional risk factors, we performed two multivariable MR analyses for each lipoprotein subfraction or particle size under investigation. The first multivariable MR analysis considers four exposures: TG, LDL-C, HDL-C, and the lipoprotein measurement under investigation. The second multivariable MR analysis replaces LDL-C and HDL-C with ApoB and ApoA1, in accordance with some recent studies [42]. SNPs were ranked by their minimum p-values with the four exposures and are selected as instruments only if they were associated with at least one of the four exposures (p-value ≤ 10−4). Both multivariable MR analyses used the Davis [31] and GERA [29] datasets for instrument selection, the Kettunen [32] and GLGC [30] datasets for the associations of the instruments with the exposures, and the CARDIoGRAMplusC4D + UK Biobank [34] dataset for the associations with CAD.
Statistical estimation
For univariable MR, we used the robust adjusted profile score (RAPS) because it is more efficient and robust than many conventional methods [38, 43]. RAPS can consistently estimate the causal effect even when some of the genetic variants violate instrumental variables assumptions. For multivariable MR, we used an extension to RAPS called GRAPPLE to obtain the causal effect estimates of multiple exposures [44]. GRAPPLE also allows the exposure GWAS to have overlapping sample with the outcome GWAS, while the original RAPS does not. We assessed the strength of the instruments using the modified Cochran’s Q statistic [45]. Because many lipoprotein subfraction traits were analyzed simultaneously, we used the Benjamini-Hochberg procedure to correct for multiple testing [46] and the false discovery rate was set to be 0.05. More detail about the statistical methods can be found in Appendix 3.
Genetic markers
To obtain genetic markers, we selected SNPs that are associated with the lipoprotein measurements identified in the MR (p-value ≤ 5 x 10−8) and CAD (p-value ≤ 0.05) but are not associated with LDL-C or ApoB (p-value ≥ 10−3). To maximize the power of this exploratory analysis, we meta-analyzed the results of the two lipidome GWAS [31, 32] by inverse-variance weighting. For the associations with LDL-C and CAD, we used the GWAS summary data reported by the GLGC [30] and CARDIoGRAMplusC4D [34] consortia. We used LD clumping to obtain independent markers [41] and then validate the markers using tissue-specific gene expression data from the GTEx project.
Sensitivity analysis and replicability
Because we had multiple GWAS summary datasets for the lipoprotein subfractions and CAD/MI (Table 1), we swapped the roles of the GWAS datasets in the three-sample MR design whenever permitted by the statistical methods to obtain multiple statistical estimates. These estimates are not completely independent of the primary results, but they can nonetheless be used to assess replicability. As a sensitivity analysis, We further analyzed univariable MR using inverse-variance weighting (IVW) [47] and weighted median [48] and compared with the primary results obtained by RAPS. We also assessed the assumptions made by RAPS using some diagnostic plots suggested in previous methodological articles [38].
3 Results
Genetic correlations and phenotypic screening
We obtained the genetic correlations of the lipoprotein subfractions and particle sizes with the traditional lipid risk factors: TG, LDL-C, HDL-C, ApoB, and ApoA1 (Table 1). We found that almost all VLDL subfractions traits (besides those related to very small VLDL subfraction) and the mean VLDL particle diameter have an estimated genetic correlation with TG very close to 1. Most traits related to the large and very large HDL subfractions also have a high genetic correlation with HDL-C and ApoA1.
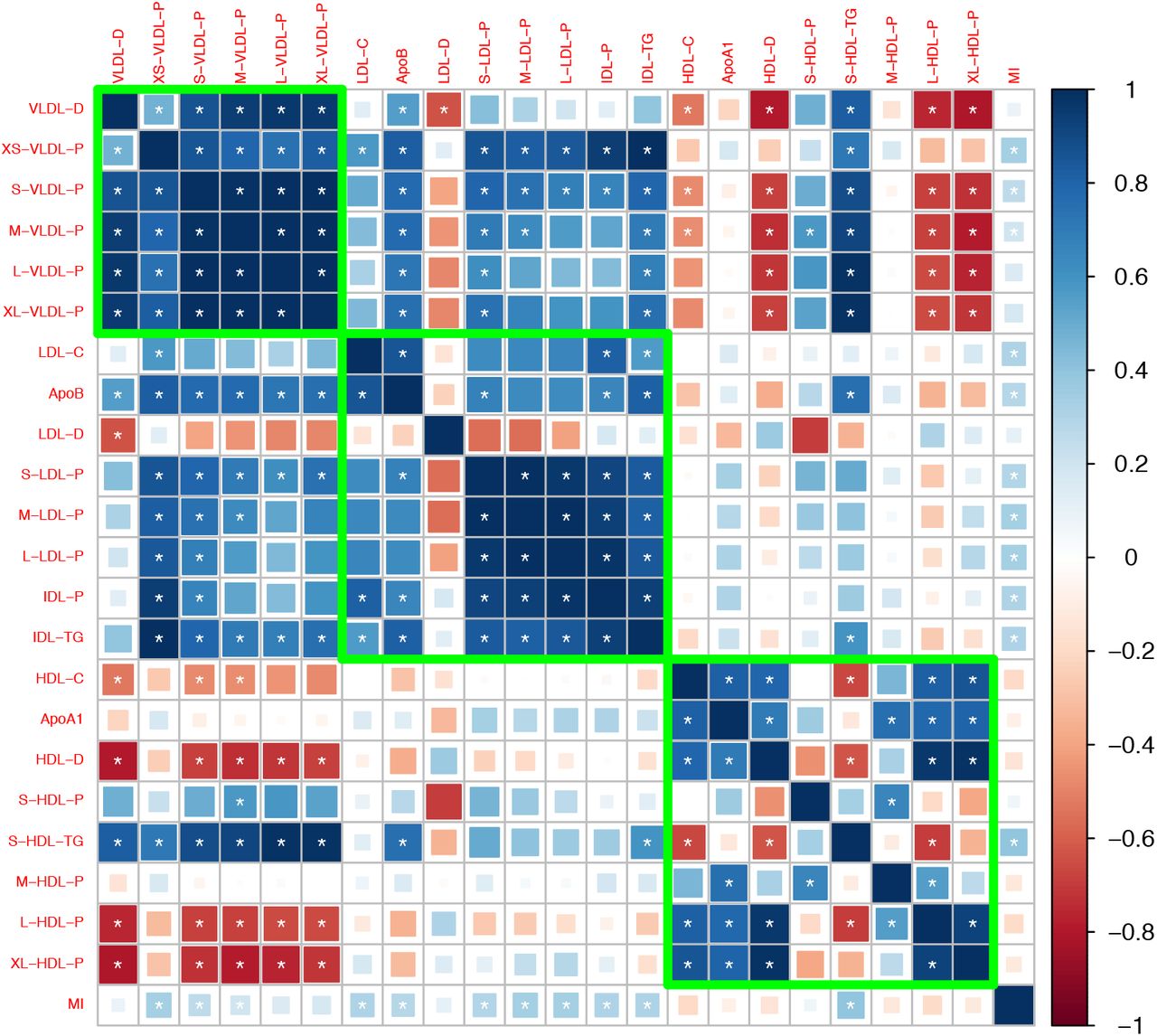
After removing traits that are strongly correlated with the traditional risk factors, we obtained 27 traits that may involve independent genetic mechanisms. Figure 1 shows the genetic correlation matrix for these traits and the traditional lipid factors. The selected traits can be divided into two groups based on whether they are related to VLDL/LDL/IDL particles or HDL particles. Within each group, most traits were strongly correlated with the others. In the first group, most traits had a positive genetic correlation with LDL-C and ApoB, while in the second group, most traits had a positive genetic correlation with HDL-C and ApoA1. Exceptions include LDL-D, which had a negative but statistically non-significant genetic correlation with LDL-C and ApoB, and S-HDL-P and S-HDL-L, which showed no or weak genetic correlation with HDL-C and ApoA1.

Genetic correlation matrix of the 27 lipoprotein subfraction traits selected in phenotypic screening and 5 traditional lipid traits. White asterisk indicates the correlation is statistically significant after Bonferroni correction for multiple comparisons at level 0.05.
Mendelian randomization
Figure 2 shows the estimated causal effect of the selected lipoprotein measurements on MI or CAD that are statistically significant (false discovery rate = 0.05). The unfiltered results can be found in Appendix 3, which also contains results of the sensitivity and replicability analyses.

Results of the Mendelian randomization analyses (false discover rate = 0.05): Estimated odds ratio [95% confidence interval] per standard deviation increase of the selected lipoprotein measurements on MI or CAD.
The concentration and lipid content of VLDL, LDL, and IDL subfractions showed harmful and nearly uniform effects on MI in univariable MR. However, after adjusting for the traditional lipid risk factors, the effects of these ApoB-related subfractions become close to zero (besides IDL-FC in one multivariable analysis). The mean diameter of LDL particles (LDL-D) showed a harmful effect on MI in univariable MR, though the effect was smaller than those of the LDL subfractions in univariable MR. The estimated effect of LDL-D was attenuated in the multivariable MR analyses.
The concentration and content of medium HDL particles showed protective effects in univariable and multivariable MR analyses. In particular, adjusting for the traditional lipid risk factors did not attenuate the effect of traits related to medium HDL. The concentration of and total lipid in small HDL particles showed protective effects in multivariable MR analyses, though the effect sizes were smaller than those of the medium HDL traits. The mean diameter of HDL particles (HDL-D) had almost no effect on MI in the univariable MR analysis, but after adjusting for the traditional lipid risk factors, it showed a harmful effect.
Table 2 reports the estimated effects of M-HDL-P, S-HDL-P, HDL-D, and traditional lipid traits (TG, LDL-C, HDL-C, ApoB, ApoA1) in the multivariable MR analyses. To better understand the role of HDL subfractions and particle sizes, we also included in the table the results of the multivariate MR analyses for the traditional lipid risk factors only. Those baseline analyses suggested that HDL-C/ApoA1 had a weak, non-significant protective effect on CAD, which is consistent with prior studies [44, 49]. Adding S-HDL-P to the MR analysis did not substantially alter the estimated effects of the traditional lipid traits. However, when M-HDL-P or HDL-D was included in the model, the estimated effects of M-HDL-P and HDL-D changed substantially. In particular, when M-HDL-P was included in the multivariable MR analyses, HDL-C/ApoA1 showed a harmful effect on CAD. When HDL-D was included, HDL-C/ApoA1 showed a protective effect.
Results of some multivariable Mendelian randomization analyses. Each row in the table corresponds to a multivariable MR analysis with traditional lipid profile and the specified lipoprotein subfraction or particle size trait. Reported numbers are the point estimates (standard error) of the exposure effect.
Genetic markers associated with HDL and CAD
We identified four genetic variants that are associated with S-HDL-P, M-HDL-P, or HDL-D, not associated with LDL-C or ApoB, and associated with CAD: rs838880 (SCARB1), rs737337 (DOCK6), rs2943641 (IRS1), and rs6065904 (PLTP) (Figure 3). These SNP-cis gene pairs are also supported by examining expression quantitative trait loci (eQTL) in the tissue-specific GTEx data (Appendix 4). The first three variants were not associated with S-HDL-P. However, they had uniformly positive associations with M-HDL-P, L-HDL-P, XL-HDL-P, HDL-D, ApoA1, and HDL-C, and a negative association with CAD. The last variant rs6065904 had positive associations with S-HDL-P and M-HDL-P, negative associations with L-HDL-P, XL-HDL-P, HDL-D, negative but smaller associations with ApoA1 and HDL-C, and a negative association with CAD.

Genetic markers for HDL size (with risk alleles) and their associations with various lipid traits.
Sensitivity and replicability analysis
We also investigated the effects of lipoprotein subfractions and particle sizes on MI/CAD using multiple GWAS datasets, MR designs and statistical methods. The results are provided in Appendix 3 and are generally in agreement with the primary results reported above. The diagnostic plots for S-HDL-P and M-HDL-P did not suggest evidence of violations of the instrument strength independent of direct effect (InSIDE) assumption [50] made by RAPS and GRAPPLE (Appendix 4).
4 Discussion
By using recent genetic data and Mendelian randomization, this study examines whether some lipoprotein subfractions and particle sizes, beyond the traditional lipid risk factors, may play a role in coronary artery disease. We find that VLDL subfractions have extremely high genetic correlations with blood triglyceride level and thus offer little extra value. We find some weak evidence that larger LDL particle size may have a small harmful effect on myocardial infarction and coronary artery disease.
Our main finding is that the size of HDL particles may play an important and previously undiscovered role. Although the concentration and lipid content of small and medium HDL particles appear to be positively correlated with HDL cholesterol and ApoA1, their genetic correlations are much smaller than 1, indicating the existence of independent biological pathways. Moreover, the Mendelian randomization analyses suggested that the small and medium HDL particles may have protective effects on CAD. We also find that larger HDL mean particle diameter may have a harmful effect on CAD. Finally, we identified four potential genetic markers for HDL particle size that are independent of LDL cholesterol and ApoB.
There has been a heated debate on the role of HDL particles in CAD in recent years following the failure of several trials for CETP inhibitors [51–53] and recombinant ApoA1 [54] targeting HDL cholesterol. Observational epidemiology studies have long demonstrated strong inverse association between HDL cholesterol and the risk of CAD or MI [55–57], but conflicting evidence has been found in MR studies. In an influential study, Voight and collaborators found that the genetic variants associated with HDL cholesterol had varied associations with CAD and that almost all variants suggesting a protective effect of HDL cholesterol were also associated with LDL cholesterol or triglycerides [58]. Other MR studies also found that the effect of HDL cholesterol on CAD is heterogeneous [38] or attenuated after adjusting for LDL cholesterol and triglycerides [59, 60].
Notice that the harmful effect of larger HDL particle diameter found in this study relies on including HDL-C or ApoA1 in the multivariable MR analysis. Thus, the role of HDL particles in preventing CAD may be more complicated than, for example, that of LDL cholesterol or ApoB. It is possible that HDL cholesterol, HDL subfractions, and HDL particle size are all phenotypic markers for some underlying causal mechanism. A related theory is the HDL function hypothesis [61]. Cholesterol efflux capacity, a measure of HDL function, has been documented as superior to HDL-C in predicting CVD risk [62, 63]. Recent epidemiologic studies found that HDL particle size is positively associated with cholesterol efflux capacity in post-menopausal women [64] and in an asymptomatic older cohort [65]. However, mechanistic efflux studies showed that small HDL particles actually mediate more cholesterol efflux [66, 67]. A likely explanation of this seeming contradiction is that a high concentration of small HDL particles in the serum may mark a block in maturation of small HDL particles [65]. This can also partly explain our finding that small HDL traits have a smaller effect than medium HDL traits, as increased medium HDL might indicate successful maturation of small HDL particles.
Among the reported genetic markers, SCARB1 and PLTP have established relations to HDL metabolism and CAD. SCARB1 encodes a plasma membrane receptor for HDL and is involved in hepatic uptake of cholesterol from peripheral tissues. Recently, a rare mutation (P376L) of SCARB1 was reported to raise HDL-C level and increase CAD risk [68, 69]. This is opposite direction to the conventional belief that HDL-C is protective and could be explained by HDL dysfunction. PLTP encodes the phospholipid transfer protein and mediates the transfer of phospholipid and cholesterol from LDL and VLDL to HDL. As a result, PLTP plays a complex but pivotal role in HDL particle size and composition. Several studies have suggested that high PLTP activity is a risk factor for CAD [70–72].
Our study should be viewed in the context of its limitations, in particular, the inherent limitations of the summary-data Mendelian randomization design. Any causal inference from non-experimental data makes un-verifiable assumptions, so does our study. Conventional MR studies assume that the genetic variants are valid instrumental variables. The statistical methods used by us make less stringent assumptions about the instrumental variables, but those assumptions could still be violated even though our model diagnosis does not suggest evidence against the InSIDE assumption. Our study did not adjust for other risk factors for CAD such as body mass index, blood pressure, and smoking. All the GWAS datasets used in this study are from the European population, so the same conclusions might not generalize to other populations. Furthermore, our study used GWAS datasets from heterogeneous subpopulations, which may also introduce bias [73]. We also did not use more than one subfraction traits as exposures in multivariable MR because of their high genetic correlations. Alternative statistical methods could be used to select the best causal risk factor from high-throughput experiments [74].
Recently, a NMR spectroscopy method has been developed to estimate HDL cholesterol efflux capacity from serum [75]. That method can form the basis of a genetic analysis of HDL cholesterol efflux capacity and may complement the results here. We believe more laboratorial and epidemiological research is needed to clarify the roles of HDL subfractions and particle size in cardiovascular diseases.
Appendix 1 Lipid and lipoprotein traits
Two published GWAS of the human lipidome [31, 32] measured lipoprotein subfractions and particle sizes using NMR spectroscopy. We investigated the 82 lipid and lipoprotein traits measured in these studies that are related to very-low-density lipoprotein (VLDL), LDL, and HDL subfractions and particle sizes. All the subfraction traits are named using three components separated by hyphen: the first indicates the size (XS, S, M, L, XL, XXL); the second indicates the category according to the lipoprotein density (VLDL, LDL, IDL, HDL); the third indicates the measurement (C for total cholesterol, CE for cholesterol esters, FC for free cholesterol, L for total lipids, P for particle concentration, PL for phospholipids, TG for triglycerides). A full list of lipid and lipoprotein traits used in our study can be found in Appendix 1-Table 1 below.
All 82 traits included in this study and whether they are measured in the Kettunen and Davis GWAS (NA means not available).
Appendix 2 Genetic Correlations
We estimated the genetic correlation between lipoprotein subfractions, particle sizes, and traditional lipid risk factors using the LD score regression [37]. Appendix 2-Figure 1 to 131 show the estimated genetic correlation matrix between selected traits using different datasets. Below the figures, Appendix 2-Table 1 shows the estimated genetic correlations of the lipoprotein subbfractions with the traditional lipid risk factors using the Davis GWAS. The results in Appendix 2-Table 1 were then used to screen the traits as described in Materials and Methods.

Genetic correlations computed using the Davis et al. (2017) GWAS summary dataset.

Genetic correlations computed using the Kettunen et al. (2016) GWAS summary dataset.

Genetic correlations computed by meta-analyzing the results in Appendix 2-Figure 1 and 2.
Estimated genetic correlation (standard error) of the lipoprotein subfractions with the traditional lipid risk factors using the Davis GWAS. Bolded estimates are above 0.8 and the corresponding traits were removed in phenotypic screening.
Appendix 3 Mendelian randomization
We implemented several Mendelian randomization (MR) designs and statistical methods to estimate the causal effect of lipoprotein subfractions and particles sizes on coronary artery disease. In general, we adopted the three-sample summary data MR design described in Zhao et al. [38], Wang et al. [44] and we swapped the roles of the GWAS datasets whenever permitted by the statistical methods. More specifically, the statistical methods we used for univariable MR (RAPS, IVW, weighted median) require that the GWAS datasets for obtaining instruments, SNP effects on the exposure, and SNP effects on the outcome must have no overlapping sample. The multivariable MR method we used (GRAPPLE) allows the exposure and outcome GWAS to be dependent and estimates the proportion of overlapping sample. However, GRAPPLE still requires that the selection GWAS uses an nonoverlapping sample.
The MR designs we implemented in this study are summarized in Appendix 3-Table 1. We considered two ways of instrument selection for univariable MR. In “traditional selection”, the traditional lipid traits were used to select the instruments for the corresponding subfraction traits. That is, HDL-C was used to select SNPs for HDL subfractions and particle size, LDL-C for IDL and LDL subfractions and particle size, and TG for VLDL subfractions and particle size. This tends to select more instruments because the GWAS for traditional lipid traits had a larger sample size. In “subfraction selection”, the instrumental SNPs were selected for each lipoprotein subfraction and particle size using the same or closest trait in the selection GWAS. For example, if the exposure under investigation is S-HDL-L but it is not measured in the Davis GWAS (if it is used for selection), S-HDL-P is used instead for instrument selection.
For multivariable MR, we considered two models with different sets of exposures: TG, LDL-C, HDL-C, and the subfraction/particle size under investigation; TG, ApoB, ApoA1, and the subfraction/particle size under investigation. SNPs were selected as potential instruments if they were associated (p-value ≤ 10−4) with at least one of the four exposures. LD clumping was then used to obtain independent instruments, as described in Materials and Methods.
We briefly comment on the statistical methods used in univariable MR. All the three methods we used—RAPS, IVW, weighted median—require that the exposure GWAS and outcome GWAS have non-overlapping samples. RAPS and weighted median can provide consistent estimate of the causal effect even when some of the genetic variants are not valid instruments, provided that the direct effects of the genetic variants are independent of the strength of their associations with the exposure. The last condition is called the Instrument Strength Independent of Direct Effect (InSIDE) assumption in the MR literature [50]. RAPS is also robust to idiosyncratically large direct effect [43]. Because IVW and weighted median can be severely biased by weak instruments [43], we only used them with the set of SNPs that have genome-wide significant association (p-value ≤ 5 x 10−8) with the exposure. In comparison, RAPS does not suffer from weak instrument bias and we used it with all the SNPs obtained by LD clumping without any p-value threshold.
Below, Appendix 3-Figure 1 shows the MR results for the 27 lipoprotein measurements selected in phenotypic screening. Estimates that are statistically significant at a false discovery rate of 0.05 are shown in Figure 2 of the main paper. Appendix 3-Table 2 shows the estimated effect of all the lipoprotein subfractions and particle sizes on myocardial infarction or coronary artery disease in various MR designs. Full results of the multivariable MR analyses, including the estimated effects of the traditional lipid risk factors, can be found in Appendix 3-Table 5 and 6. The results of the univariable MR analyses using IVW and weighted median estimators can be found in Appendix 3-Table 3 and 4.
Three-sample Mendelian randomization designs.
Appendix 3.1 Pooled results

Mendelian randomization results for the 27 lipoprotein measurements selected in phenotypic screening.
In the tables below, Red indicates p-value is significant (at level 0.05) after Bonferroni correction for all the results in the corresponding table and blue indicates p-value ≤ 0.05
Mendelian randomization results using all selected SNPs (univariable MR using RAPS and multivariable MR using GRAPPLE).
Appendix 3.2 Univariable MR results
Mendelian randomization results using genome-wide significant SNPs and inverse variance weighted (IVW) estimator.
Mendelian randomization results using genome-wide significant SNPs and the weighted median estimator.
Appendix 3.3 Multivariable MR results
Multivariable Mendelian randomization results (adjusted for HDL-C, LDL-C, and TG).
Multivariable Mendelian randomization results (adjusted for ApoA1, ApoB, and TG).
Appendix 3.4 Q-statistics for multivariable Mendelian randomization
Modified Cochran’s Q-statistics (p-values) for the multivariable Mendelian randomization analyses (adjusted for HDL-C, LDL-C, and TG). DF is short for degrees of freedom.
Modified Cochran’s Q-statistics (p-values) for the multivariable Mendelian randomization analyses (adjusted for ApoA1, ApoB, and TG). DF is short for degrees of freedom.
Appendix 4 Diagnostic plots and the genetic markers
As mentioned above, RAPS is more robust against invalid instruments than other statistical methods for univariable MR, but it still needs the InSIDE assumption to be approximately satisfied. Zhao et al. [38] described two diagnostic plots RAPS that checks whether there is clear evidence that the InSIDE assumption is violated. Here we report these plots for HDL-C and M-HDL-P in different studies. Notice that a lack of evidence to falsify the InSIDE assumption does not mean that it is true.
Appendix 4.1 S-HDL-P

Diagnostic plots for S-HDL-P (selection: Davis; exposure: Kettunen; outcome: UK Biobank).
Appendix 4.2 M-HDL-P

Diagnostic plots for M-HDL-P (selection: Davis; exposure: Kettunen; outcome: UK Biobank).
Appendix 4.3 Genetic markers for M-HDL-P and S-HDL-P
We can further assess the validity of the InSIDE assumption for M-HDL-P and S-HDL-P but examining the associations of their genetic instruments with the traditional lipid risk factors and other subfraction traits. We meta-analyzed the summary results in the two lipidome GWAS (Davis and Kettunen) and obtained SNPs that are associated with S-HDL-P and M-HDL-P (p-value ≤ 5 x 10−8; the results are LD-clumped). The next two Tables show some information about these genetic markers and their associations with other traits.
Appendix 4-Figure 3 and 4 shows how adjusting for LDL-C and TG changes the effects of the selected SNPs for S-HDL-P and M-HDL-P on CAD. The adjusted effect on CAD is obtained by original effect on CAD – 0.45 * effect on LDL-C – 0.25 * effect on TG. After the adjustment, the associations of the genetic variants with CAD generally became closer to the fitted lines that correspond to the estimated effects of S-HDL-P and M-HDL-P.
List of SNPs associated with M-HDL-P.
List of SNPs associated with S-HDL-P.

Scatter-plots for S-HDL-P with the effects on CAD adjusted for LDL-C and TG. Red lines correspond the fitted effects of S-HDL-P in multivariable MR.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Scatter-plots for M-HDL-P with the effects on CAD adjusted for LDL-C and TG. Red lines correspond the fitted effects of M-HDL-P in multivariable MR.
Appendix 4.4 Gene expression
Tissue-specific gene expressions associated with the 4 discovered genetic markers in the gTEX project.
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].
- [6].↵
- [7].
- [8].↵
- [9].↵
- [10].
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].
- [53].↵
- [54].↵
- [55].↵
- [56].
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].
- [72].↵
- [73].↵
- [74].↵
- [75].↵




