

Abstract
Mechanisms that ensure repair of double-stranded DNA breaks play a key role in the integration of foreign DNA into the genome of transgenic organisms. After pronuclear microinjection, exogenous DNA is usually found in the form of concatemer consisting of multiple co-integrated transgene copies. Here we investigated contribution of various DSB repair pathways to the concatemer formation. We injected a pool of linear DNA molecules carrying unique barcodes at both ends into mouse zygotes and obtained 10 transgenic embryos with transgene copy number ranging from 1 to 300 copies. Sequencing of the barcodes allowed us to assign relative positions to the copies in concatemers and to detect recombination events that happened during integration. Cumulative analysis of approximately 1000 integrated copies revealed that more than 80% of copies underwent recombination when their linear ends were processed by SDSA or DSBR. We also observed evidence of double Holliday junction (dHJ) formation and crossing-over during the formation of concatemers. Additionally, sequencing of indels between copies showed that at least 10% of the DNA molecules introduced into the zygote are ligated by non-homologous end joining (NHEJ). Our barcoding approach documents high activity of homologous recombination after exogenous DNA injection in mouse zygote.
Introduction
Genetically modified organisms have become an important element of biomedical research (1), production of pharmaceutical proteins (2), and in agriculture (3). Despite the widespread use of transgenic organisms, many long-standing questions remain unanswered, especially concerning molecular mechanisms involved in DNA integration. It is known that the repair of double-stranded breaks (DSBs) plays an important role during genome editing and integration of foreign DNA into the genome. Homologous recombination (HR) and nonhomologous end-joining (NHEJ) are the two major pathways responsible for DSB repair in eukaryotic cells. The majority of random DSBs in somatic cells are repaired by NHEJ (4), while HR is necessary to resolve more specific problems such as rescuing a stalled replication fork or providing recombination in meiosis (5). Homology-based pathways involve invasion of single-stranded DNA filaments originating from DSB ends into homologous template region, resulting in formation of a D-loop and DNA synthesis. Different HR outcomes are possible, depending on the D-loop processing (6). In synthesis-dependent strand annealing (SDSA), restored DNA end is released after D-loop disruption, and anneals with the second DSB end. Break-induced replication (BIR) initiates long-range DNA synthesis in the absence of a second DSB end (replication fork collapse or telomere shortening). Double-strand break repair (DSBR) operates when the displaced strand from template anneals to the second broken DNA end. This way, both invading ends become physically linked in a double Holliday junction (dHJ) that could be resolved with or without crossing-over (6). With the development of CRISPR-based genome editing, the focus has shifted to other roles of DNA repair pathways: HR is exploited for precise genetic modifications, such as transgene knock-ins, and NHEJ is used to knock-out genes (7, 8). The obvious importance of these pathways for the field of genome editing serves as a driver for studying activity of these pathways in different cells (9, 10); understanding crosstalk between NHEJ and HR (11); and for developing new methods for the preferential activation of a particular pathway (12). Modification of the genome at the zygote stage is an advantageous method for obtaining genetically modified animals. However, in the literature there is no quantitative estimate of the activity of these DNA repair pathways in the early mammalian embryogenesis.
We decided to test the activity of various ways of processing double-stranded breaks in mouse zygotes after pronuclear microinjection of genetic constructs. In this method, exogenous DNA solution is injected inside the pronucleus that contains genetic material of the sperm or egg prior to fertilization (13). Usually, hundreds to thousands of DNA molecules are injected and processed subsequently by cellular DNA repair machinery, resulting in a stable DNA integration. Extensive work of many pioneer groups in the early years of transgenesis revealed several prominent features of pronuclear microinjection (14, 15). For instance, transgenes always integrate at one or few sites in the host genome and most of the transgene copies are prevalently arranged into head-to-tail tandemly oriented copies (concatemers) (data aggregated in Sup. Table 1). Here we investigated mechanisms of exogenous DNA molecule processing by combining the classical approach of pronuclear microinjection with transgene barcoding technique and next-generation sequencing (NGS). Barcoding strategy was initially applied to address individual cell fates among heterogeneous cell population (16, 17) and could be extended to trace transgene copies as well. Ten transgenic mouse embryos with varying amount of barcoded transgenes were analyzed with NGS to read terminal barcodes of each integrated transgene copy. Knowing initial barcode tags of the injected transgenes we could reconstitute connections of most of the transgene copies in concatemers and found various signatures of homology-based DNA repair pathways.
Materials and methods
Cloning of the barcoded vector library
Plasmid pcDNA3-Clover (Addgene #40259) was used as a base vector for cloning barcodes. Vector was digested with PciI, dephosphorylated and ligated with short adapter fragment, introducing SbfI and NheI recognition sites. These sites were used to insert 500 bp PCR product amplified from human genome with primers carrying barcode sequences. Human region was selected to avoid potential recombination of the transgene ends with mouse genome. Sequences of the barcoded primers were as follows: 5’ -CCTGCAGGNNCGANNGCANNTGCNNCTTGAATGACAACTAGTGCTCCAGG -3’ (Primer with Tail barcode), 5’- GCTAGCNNACTNNGATNNGGTNNCTATCCTGACCCTGCTTGGCT -3’ (Primer with Head barcode) (Sup. Fig. 1). Barcoded plasmid library was electroporated into Top10 cells, plated and extracted using GeneJET Plasmid Midiprep Kit (Thermo Fisher Scientific, USA). Number of colonies was estimated to be around 10000 individual clones.
Generation of the transgenic embryos by pronuclear microinjection and PCR genotyping
Barcoded plasmid library was linearized with type IIS BsmBI restriction enzyme to provide incompatible 4bp overhangs (250bp distance from each barcode). Digested DNA was gel purified and eluted from the agarose gel using Diagene columns (Dia-M, Russia) according to the manufacturer’s recommendations. Eluate was additionally purified with AMPure XP magnetic beads (Beckman Coulter, USA) and finally dissolved in TE microinjection buffer (0.01 M Tris–HCl, 0.25 mM EDTA, pH 7.4). Fertilized oocytes were collected from superovulated F1 (CBA × C57BL/6) females crossed with C57BL/6 males. DNA was injected into the male pronuclei (1-2 pl ∼ 1000-2000 copies) as described elsewhere (18). Microinjected zygotes were transferred into oviducts of recipient pseudopregnant CD-1 females. Embryos were extracted at the 13.5 day of development and PCR genotyped with primers for Clover backbone or transgene-transgene junctions (same primers that we used for generating NGS PCR products) (Sup. Table 3). TAIL-PCR was performed as described earlier (19) with primers complementary to the 5’- or 3’-ends of the transgene (Sup. Table 3). Conventional PCR reactions with Taq, Q5 or LongAmp polymerases (NEB, USA) were set up to amplify various rearrangements in concatemer structure, study copy order with barcode-specific primers and validate transgene-genomic borders (Sup. Table 3).
All experiments were conducted at the Centre for Genetic Resources of Laboratory Animals at the Institute of Cytology and Genetics, SB RAS (RFMEFI61914X0005 and RFMEFI61914X0010). All experiments were performed in accordance with protocols and guidelines approved by the Animal Care and Use Committee Federal Research Centre of the Institute of Cytology and Genetics, SB RAS operating under standards set by regulations documents Federal Health Ministry (2010/708n/RF), NRC and FELASA recommendations. Experimental protocols were approved by the Bioethics Review Committee of the Institute of Cytology and Genetics.
Copy number quantification by ddPCR
Droplet Digital PCR (ddPCR) was performed using ddPCR Supermix for Probes (No dUTP) and QX100 ddPCR Systems (Bio-Rad, USA) according to manufacturer’s recommendations. The 20 μl reaction contained 1× ddPCR Supermix, 900 nM primers, 250 nM probes and 3-60 ng digested genomic DNA. We adjusted input DNA quantity for each embryo to account for tissue mosaicism and transgene copy number variation which affected transgene:control relative dilutions in every embryo. We tested various restriction digestion conditions in order to reliable separate all transgene copies (Sup. Fig. 3) and decided to perform overnight digestions with HindIII-HF or DpnII (NEB, USA) in CutSmart buffer. Transgene copy number (Clover gene) was normalized to Emid1 control gene (Codner et al., 2016) or the unique transgene-genome border region (identified for four embryos). PCR was conducted according to the following program: 95 °C for 10 min, then 40 cycles of 95 °C for 30 s and 61 °C for 1 min, with a final step of 98 °C for 7 min and 20 °C for 30 min. All steps had a ramp rate of 2 °C per second. ddPCR was performed in two independent technical replicates. Sequences for primers and probes are available in Sup. Table 3. Data were analyzed using QuantaSoft (Bio-Rad, USA).
DNA library preparation for NGS
NGS library 1 (original barcoded plasmids): barcoded plasmid library was digested with NheI and SbfI (Fig. 1A). 640 bp DNA fragment with a pair of barcodes was gel purified, eluted in TE buffer and sequenced.
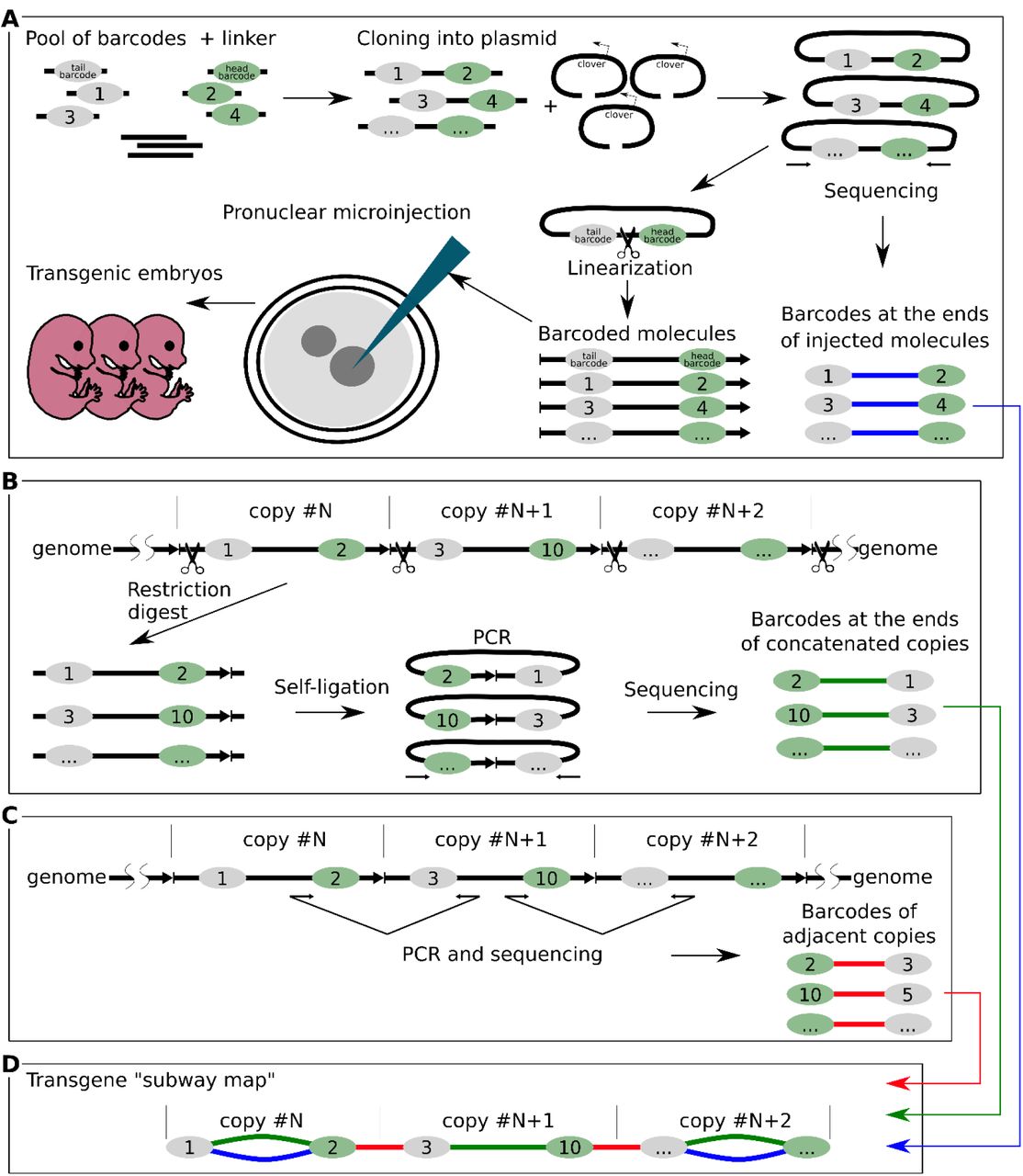
Schematic overview of the experimental design. (A) The main stages of generation of the barcoded plasmid library (NGS library 1) and pronuclear microinjection of barcoded molecules. (B) Determining barcodes at the ends of concatenated copies by inverse PCR. DNA was digested with PciI and ligated in conditions favoring self-ligation (NGS library 3). (C) Determining barcodes of adjacent copies (NGS library 2). (D) Element of a transgene «subway map» - our visualization approach that combined NGS data from three sequencing experiments. Colors indicate different barcode connections: green – actual transgene copy in concatemer from the inverse PCR data; red - transgene-transgene junctions; blue – copies that retained combinations of barcodes which were present in the injected plasmids.
NGS library 2 (PCR of the barcoded transgene-transgene junctions): Concatemer junctions containing barcodes were PCR amplified using Q5 polymerase (Fig. 1C). PCR conditions were tested to avoid accumulation of PCR artifacts in late cycles and to account for copy number variation between embryos (range of 0.2 copies to 300 copies). PCR program: 98°C for 30 s, then 25-30 cycles of 98°C for 15 s, 64°C for 30 s, 72°C for 1 min, with 3 min of final extension at 72°C. 25 µl of PCR reaction were purified using AMPure XP magnetic beads (Beckman Coulter, USA), eluted in TE buffer and sequenced. In order to obtain additional information about transgene-transgene junctions we also sought to sequence PCR products corresponding to the internal junctions (100 bp from BsmBI cut site) in three multicopy lines (embryos #2, 3, 7). To stay in the range of acceptable read length (∼150 bp) we used one primer close to the junction and another one flanking barcode (primer pairs 2+14 and 1+13 at Sup. Fig. 6). PCR products were generated for both orientations. This way, a unique signature of the trimmed junction could be assigned to specific barcodes (Fig. 6).
NGS library 3 (inverse PCR of the barcoded transgene ends): Genomic DNA from transgenic embryos was digested overnight with excess of PciI enzyme that cuts 87 bp away from one of the barcodes, inside the junction (Fig. 1B). Digested DNA was purified with AMPure XP magnetic beads. To avoid incomplete digestion, sticky ends generated with PciI were filled-in with Klenow enzyme to produce blunt ends. This signature was later used for filtering during sequence analysis. After heat inactivation of Klenow enzyme (20 min at 75°C), 300 ng of digested DNA were ligated overnight at 16°C in a large reaction volume (100 µl) to facilitate self-ligation of transgene monomers. Terminal barcodes of self-ligated DNA fragments were PCR amplified with Q5 polymerase with the same primers and conditions as were used for NGS library 2 generation. To remove PCR fragments originating from undigested DNA, Illumina prepared adapter-ligated PCR products were additionally treated with PciI, gel purified and used for sequencing. We have prepared 10 libraries corresponding to 10 embryos and one control library representing a 1:1 mix of self-ligated DNA from embryos #1 and #4 under the same conditions (150 ng + 150 ng of digested genomic DNA in 100 µl ligation). Control library served as a quantitative measurement of random transgene ligation as opposed to self-ligation.
DNA fragments from three libraries were prepared with NEBNext Ultra DNA Library Prep Kit for Illumina (NEB, USA), pooled together and sequenced on the Illumina HiSeq 2500 platform (Illumina, USA). Libraries were assessed using an Agilent 2100 bioanalyzer (Agilent, USA) and a Qubit dsDNA HS assay kit (Life Technologies, USA).
All of the above experiments were performed using Q5 polymerase (NEB) to avoid PCR artifacts (barcode mutations or switching), as it was shown that other polymerases have much higher rate of strand conversion (20).
Computational data analysis
Overview of data processing pipeline
NGS data processing contained four steps. First, reads were trimmed using cutadapt to remove constant sequences flanking barcodes. Second, read pairs were searched for complete or partial match of barcode pattern (NN CGA NN GCA NN TGC NN for tail barcode, NN ACT NN GAT NN GGT NN for head barcode) and pairs sharing identical barcodes were merged. This results in initial set of barcode pairs, which was further filtered at the third step of the pipeline to produce final set of pairs. These resulting pairs were visualized using Network module of the vis.js framework (http://visjs.org/). All computations were performed using nodes of Novosibirsk State University high-throughput computational cluster.
Reads trimming
We used cutadapt v. 1.15 (21) to perform reads trimming. For NGS Library 1 (initial plasmid library) we ran cutadapt independently on each of two mates from the read pair, and then combined obtained results. For NGS Library 2 (Junction PCR) we ran cutadapt in paired-end mode using –G option, which allowed us to distinguish PCR products containing barcodes and PCR products containing internal junction sequences. Each read pair may have one of two orientations. In the Forward-Reverse orientation, first mate corresponds to the 5’-end of the PCR product and the second mate corresponds to the 3’-end. In the Reverse-Forward orientation first mate corresponds to the 3’-end and second mate to the 5’-end. To account for both orientations, we ran cutadapt on the input data twice, each time searching for one of these two scenarios (see Sup. Table 4), and combined obtained results. For NGS Library 3 (Inverse PCR), we first ran cutadapt with adapter sequences, which include inverse PCR ligation junctions (cutadapt’s first pass in the Sup. Table 4). We considered reads where inverse PCR ligation junction was present as inverse PCR products, whereas reads with intact site of PciI enzyme were discarded, as they represented junction between two adjacent transgene molecules. Since PciI site is located far from barcode sequence, we ran cutadapt again on the reads, which, according to the first pass, contained inverse PCR ligation junctions (second pass in the Supplementary Table 2). During second pass, reads were trimmed immediately before barcode sequence, in a same manner as we did for Library 1. Both first and second passes of cutadapt were executed independently for each of two read mates, and obtained results were combined together. Details of cutadapt run parameters are presented in Supplementary Table 2.
Barcode identification and reads merging
We used custom python script to analyze cutadapt output and count identical read pairs. At this stage, we discarded reads which were too short (read length after trimming < 18 bp) and reads with too low quality. As a quality threshold, we required that within 21 base pairs at the 5’-end of the read, which presumably represent barcode sequence, all base calls had mapQ values above 20.
Resulting dataset of read pairs was further analyzed using python regular expression module to find barcode sequences within each read. Although all barcodes were supposed to share similar pattern (NN CGA NN GCA NN TGC or NN ACT NN GAT NN GGT NN), we expected that some of them might be slightly different due to errors, which may occur during oligonucleotide synthesis. Thus, we composed a set of regular expressions covering both exact and partial matches of barcode pattern (Sup. Table 5). Here, it is pertinent to note, that vast majority of identified barcodes (∼96%) perfectly matched expected pattern. Once barcode sequences were identified in each read, we collapsed those read pairs, which have identical barcode sequence followed by same or different 3’-endings. After the merging, we obtained dataset of pairs hereinafter referred as barcode pairs, each characterized by 5’- and 3’-barcode sequences and number of reads, supporting the pair.
Pairs filtering
PCR amplification may introduce mutations which can be interpreted as “novel” barcodes. One can suppose that original sequences will be supported by higher number of reads than their counterparts containing mutations introduced by PCR. However, it is not clear how to select the read count threshold reflecting this difference between correct and erroneous sequences. To solve this problem, we employed the fact that correct barcode sequences should be shared between embryo data (NGS Libraries 2 and 3) and initial plasmid library (NGS Library 1). For each data, we gradually increased read count threshold and monitored increase of the overlap between embryo’s and plasmid barcode sequences, and selected the point when overlap size jumps. An example of such jump for the embryo #3 data is shown in Sup. Fig. 21. Note that for some embryos these approach was not efficient, as overlap size gradually increases and there was no defined jumping point. Thus, we always performed additional visual inspection of read counts distribution to define optimal threshold. For Library 1 (initial plasmid library) analyses, we used relaxed threshold of 8 reads.
After read counts filter, we removed all barcodes identified in embryo data, which were not found in original barcoded plasmid data. At this filtering step, we made exception for those barcodes that were within top 5% by read count in current dataset.
Next, we applied empirical thresholds for pair counts. As barcode pairs maybe shuffled by the cellular DNA repair machinery, and thus pairs observed in embryo may not correspond to pairs determined in initial plasmid library, we could not apply same strategy to find threshold count as we did for barcodes. Thus, we manually selected thresholds for each sample based on read counts distribution (provided in Sup. Table 6). Moreover, if barcode was observed in several pairs in one embryo, we discarded pairs accounting for less than 1% of all paired reads containing this barcode sequence. When processing initial plasmid library, we raised this threshold to 5%.
Availability of data and materials
The sequencing results will be available in the NCBI GEO database upon article acceptance. Processed data (transgene “subway maps” in web-browser file format) are available in supplementary (Sup. Files 1-10) and at http://icg.nsc.ru/ontogen/
Results
Generation of the barcoded concatemers by pronuclear microinjection
We decided to replicate conditions of a typical microinjection experiment. In order to investigate the mechanisms leading to formation of concatemers we injected zygotes with a library of transgene molecules labeled with unique DNA barcodes. The strategy for introducing barcodes is shown in Figure 1A. A 7 Kb plasmid vector expressing Clover was tagged with two barcodes, 280 bp from the future ends (Sup. Fig. 1). We sought to find compromise between the length of the DNA ends precluding barcodes, as longer fragments would preserve barcodes from exonuclease trimming, while shorter ends are more suitable for generating PCR products for NGS sequencing (about 700 bp in our case). We sequenced the DNA of the barcodes in the plasmids and estimated that our library consists of 12,657 different molecules (Fig. 1A). This barcoded plasmid library was linearized with BsmBI which cuts between two barcodes to generate incompatible 4 nt 5’-overhangs. Linear DNA was subsequently injected into pronuclei following standard protocol (each zygote received around 1000-2000 DNA molecules) and zygotes were transferred into pseudopregnant foster mothers. Embryos were collected at the day E13.5 of development and their DNA analyzed by PCR genotyping (Sup. Fig. 2). Out of 50 embryos, 10 turned out to be positive for the transgene integration (20%), constituting a normal outcome for this method.
Determination of the transgene copy number
First, we quantified transgene copy number using droplet digital PCR (ddPCR). A pair of probes was designed for multiplex ddPCR: (1) transgene-specific probe for the Clover gene in the middle of the vector, and (2) standard reference probe for the gene Emid1 at chromosome 11 as control (tested in (22)). As seen in Sup. Fig. 4, transgene copy numbers varied greatly between embryos. In some cases, this number was less than one copy due to mosaicism of the embryo tissues (embryos #5 and #6) which resulted in dilution of the transgenic alleles with wild-type alleles. Fortunately, we managed to obtain genomic localization information for some embryos, using TAIL-PCR. Transgene-genomic border is a unique site that could be used as a probe target region for ddPCR to implement mosaicism correction (Sup. Fig. 3). Thus, replacing the standard reference Emid1 gene with a transgene-genome border specific probe allowed us to clarify copy number for four of the embryos (Sup. Fig. 4). For example, embryo #4 had 23 copies corrected to 45 (roughly 50% mosaicism), embryo #5 - 0.4 to 1, embryo #9 - 5 to 22, embryo #10 - 3.5 to 4. In summary, we obtained 10 transgenic embryos with a broad distribution of transgene copy numbers, ranging from 1 to ∼300 copies, as expected in typical pronuclear microinjection experiments (23).
Next-generation sequencing of DNA barcodes in the concatemers
In order to understand internal structure and origin of concatemers, we sequenced barcodes at the ends of the individual transgene copies. We performed two alternative sequencing experiments. First, we applied the inverse PCR method to determine the head and tail barcodes for each of the molecule in concatemer (Fig. 1B). This was important, considering transgene recombination that may take place prior to integration. Genomic DNA from transgenic embryos was digested with PciI endonuclease that makes a single cut inside transgene-transgene junctions (Fig. 1B). Ligation was performed in a highly diluted solution of digested DNA. Such conditions favor self-ligation of individual transgenes - as a result, terminal barcodes come close at a distance of about 700 bp, and they can be PCR amplified and sequenced using paired- end NGS. DNA sequencing of the inverse PCR library made it possible to establish genuine pairs of barcodes at the ends of each transgene that constitute concatemers. Additionally, we directly PCR amplified and sequenced barcodes at the transgene-transgene head-to-tail junctions to get information about relative positions of molecules in concatemers (barcodes of adjacent copies) (Fig. 1C).
Combining NGS information from all sequencing experiments (initial plasmid library + inverse PCR + junction PCR) allowed us to collect comprehensive data on which transgene molecules were injected into pronuclei, how each molecule changed during end processing, and their relative positions inside concatemers. We visualized the structure of concatemers as a graph, with nodes representing individual barcodes and edges corresponding to connections (based on the NGS data for each of the transgenic embryos) (Fig. 2A) (Sup. Fig. 7–16) (Sup. Files 1-10). Figure 2A illustrates organization of all connections between barcodes of the embryo #9, taken as an example. For clarity, each type of barcode connection was assigned one of three colors. Green color – connection between two barcodes located on different ends of individual molecule within concatemer (based on the inverse PCR data); red color - shorter connections that correspond to the transgene-transgene junctions; blue color – copies that retained combinations of barcodes that were present in the injected plasmid. We named these colored schemes “transgene subway maps”. Counting of unique barcode connections in 10 embryos revealed more than 1000 individual copies of barcoded transgenes (summed up in Table 1 and Sup. Fig. 4).

(A) Transgene “subway map” for embryo #9.Transgenes are oriented in head-to-tail fashion: green and gray colored ellipses designate head and tail barcodes respectively. Gaps between transgene chains are either due to deletions or alternative junction orientations. (B) Box plots represent the distributions of relative copy number for each terminal barcode combinations (green connections) in transgenic embryos. Relative copy numbers were calculated as read counts divided by median. Most of the outliers (relative copy number >1) were tied to deletions that create shorter PCR product. N indicates copy number (green connections) analyzed for each embryo.
Frequencies of various connection patterns in transgenic embryos.
Amongst noteworthy map features are discontinuities in connection chains (embryo #1 and #9 are prominent examples) (Sup. Fig. 7, 15). The gaps obviously indicate lack of PCR product connecting barcodes in our sequence reads. This could happen for two reasons. First, transgene-genome borders are not subjects for PCR with our NGS primers, thus at least two detached barcodes are ensured for any map. In addition, we cannot exclude multiple integration events that will increase number of connection gaps. Partial transgene deletions and inversions are another source of discontinuity: most of the gaps are certainly caused by NGS primer site loss at the concatemer junctions. As expected, we detected many transgene deletions and complex rearrangements with conventional PCR and TAIL-PCR. Number of transgene rearrangements correlated with copy number for each embryo. Embryos #2, 3, 7, 8 have hundreds of copies and plethora of rearrangements (Sup. Fig. 5). On the contrary, remaining embryos had few (#4, 6, 9) or zero (#1, 5, 10) abnormal transgene junctions. The list of some sequenced deletions and rearrangements is available in Supplementary material next to the corresponding concatemer maps. Some interesting cases (embryos #9 and #10) are highlighted in Discussion section (Sup. Fig. 15, 16).
Next, we inspected our NGS sequence data presented in a form of transgene “subway map” to understand molecular mechanisms that lead to concatemer emergence.
De novo amplification does not contribute to concatemer formation
One of the motivations for our work was to test the hypothesis that rolling circle replication or analogs can take part in the formation of a tandem of head-to-tail oriented copies (24). This mechanism is used by some viruses of eukaryotes to amplify their genome (25), and is suspected to participate in telomere maintenance (t-circles) (26) and in yeast mitochondria replication (27). It is established that after microinjection some DNA copies can be circularized by NHEJ (28). Such circular molecule could probably undergo rolling circle replication with the involvement of a BIR-like mechanism and strand displacement, for example. Conceptually, this mechanism can be a good candidate for the role of the constructor of tandemly oriented concatemers. However, in our data we did not find any evidence supporting this hypothesis, since the number of unique barcoded molecules found in concatemers was in good agreement with the estimates obtained by the ddPCR method (Sup. Fig. 4), even in multicopy embryos (70-300 copies). Nevertheless, in order to assess whether individual transgenes were amplified, we analyzed distribution of the sequence read counts for each of the unique transgene copies (green connections). Although we found several transgenes that had increased read counts, in most of these cases the shift was explained by deletions in the transgene-transgene junction regions, resulting in shorter PCR products which altered PCR kinetics. Still, there are several copies for which this technical explanation does not work. Apparently, these are genuine examples of molecules that have doubled their copy number (embryo #3 (Fig. 2B)). Although our data do not allow us to suggest a non-contradictory mechanism for this phenomenon, it is worth noting that in our analysis there were more than 1000 molecules in concatemers, of which only around 10 could be suspected of amplification. Thus, we can conclude that the concatemers are formed by direct linkage of injected molecules, rather than by de novo amplification mechanism.
HR is essential for concatemer formation
Our transgene “subway maps” illustrate high recombination activity that assembles transgenes into concatemers, including barcode “switching” (green connections without paired blue connections) and “branching” of the barcode nodes in the multicopy lines. We identified several typical connection patterns in the transgene “subway maps” and proposed which of the known DNA repair pathways could led to their formation. Of these, we examined NHEJ and two sub pathways of HR - SDSA and DSBR (Sup. Fig. 17). First, it is important to note that identical linear copies of DNA cannot be combined by HR mechanism without template region bridging two copies. Therefore, the formation of any concatemer undoubtedly begins with non-homologous end joining. However, aside from initial ligation, NHEJ plays only a minor role in assembling concatemers (see estimates in next chapters). For example, as seen in Figure 2A, in embryo #9 only 9 out of 20 copies preserved initial combination of barcodes that were observed in the injected plasmid library (coinciding blue and green connections) while the other 11 contain the head barcode from one molecule, and the tail one from the other (therefore they do not have blue connection). Such an exchange of genetic information between molecules is a characteristic signature of homologous recombination and strikingly differs from the simple combination of intact (with the exception of small indels at the junction) molecules produced by NHEJ mechanism. In our total sample of 1066 copies, only 20% (212) retained the original combination of barcodes (Table 1). Thus, it can be concluded that at least 80% of the molecules in the concatemers were processed by the homologous recombination mechanism. Most likely, this is an underestimation, because in our experimental system barcodes are located almost 300 bp from the ends and resection might not always reach barcode sequence to change it through recombination (Sup. Fig. 17).
Recombination mechanisms devised from connection patterns
To make comprehensive analysis of the connection patterns, it is important to discuss how the structures could be formed. We planned to use terminal barcodes as mere informative tags for concatenation analysis, but their location at the ends unexpectedly turned them into an indicator of recombination activity. Figure 4 shows possible mechanisms explaining the formation of recombined copies. In DSBR, after 3’-end resection and homologous duplex invasion, the D-loop synthesis reaches the barcode and forms a mismatch on one of the strands. This mismatch is a substrate for the mismatch repair system, which removes the fragment of the strand containing the mismatch and completes the gap on the template of the remaining strand. It is known that during recombination strand discrimination removes information from the invading strand rather than from the repair template, resulting in gene conversion (29, 30). Thus, mismatch repair leads to the copying of the donor barcode into the invading transgene. Simply put, the exchange of barcodes between the copies is a typical example of gene conversion. Interestingly, our assumption about the active participation of the mismatch repair system was confirmed by the analysis of embryo #1. Here we found two chains of transgenes consisting of 3 and 11 copies. As can be seen in Fig. 3A, some barcode connections form an unusual structure with a fork at one end (bottom part of the map). We assumed that the embryo #1 is a mosaic, whose cells contain one of two barcodes in a given position of concatemer in equal proportions. This is possible if, for some reason, the mismatch that was formed during recombination was not repaired before replication and daughter cells received two different barcode variants (Fig. 3B) (Sup. Fig. 18). These separated barcodes have about half the number of reads than the other copies in concatemer (Fig. 3C). We did not observe this pattern in any other embryo, so it must represent a unique event.

(A) Transgene «subway map» for embryo #1. Copies B and C have two alternative head barcodes. (B) The scheme explaining the emergence of mosaic embryo consisting of two cell populations in case the barcode mismatches were not repaired in time before DNA replication (more details in Sup. Fig. 18). (C) Copies B and C have roughly half as many reads as the other copies in the embryo #1.
Copying barcodes from a donor template explains why in many cases concatemer maps look like a web of branched nodes (embryos #2, #3, #4, #7, #8) (Sup. Fig. 8, 9, 10, 13, 14). Whenever the junctions that were originally linked together by HR or NHEJ serve as a donor template, they can share their barcode (one or both) with invading copy causing it to switch barcodes (Fig. 4). This way, one barcode will be connected with two partners at independent junctions even if these regions lie at distant positions in concatemer. Abundance of these nodes demonstrates intensive HR process that sometimes copies one junction 3-5 times with different invading ends (404 counts overall, Table 1), but also greatly complicates the “subway map” for visual inspection. Note that, as stated earlier, most of the original transgenes (blue connections) fail to be incorporated into the concatemers even if they provide recombination templates for other copies.

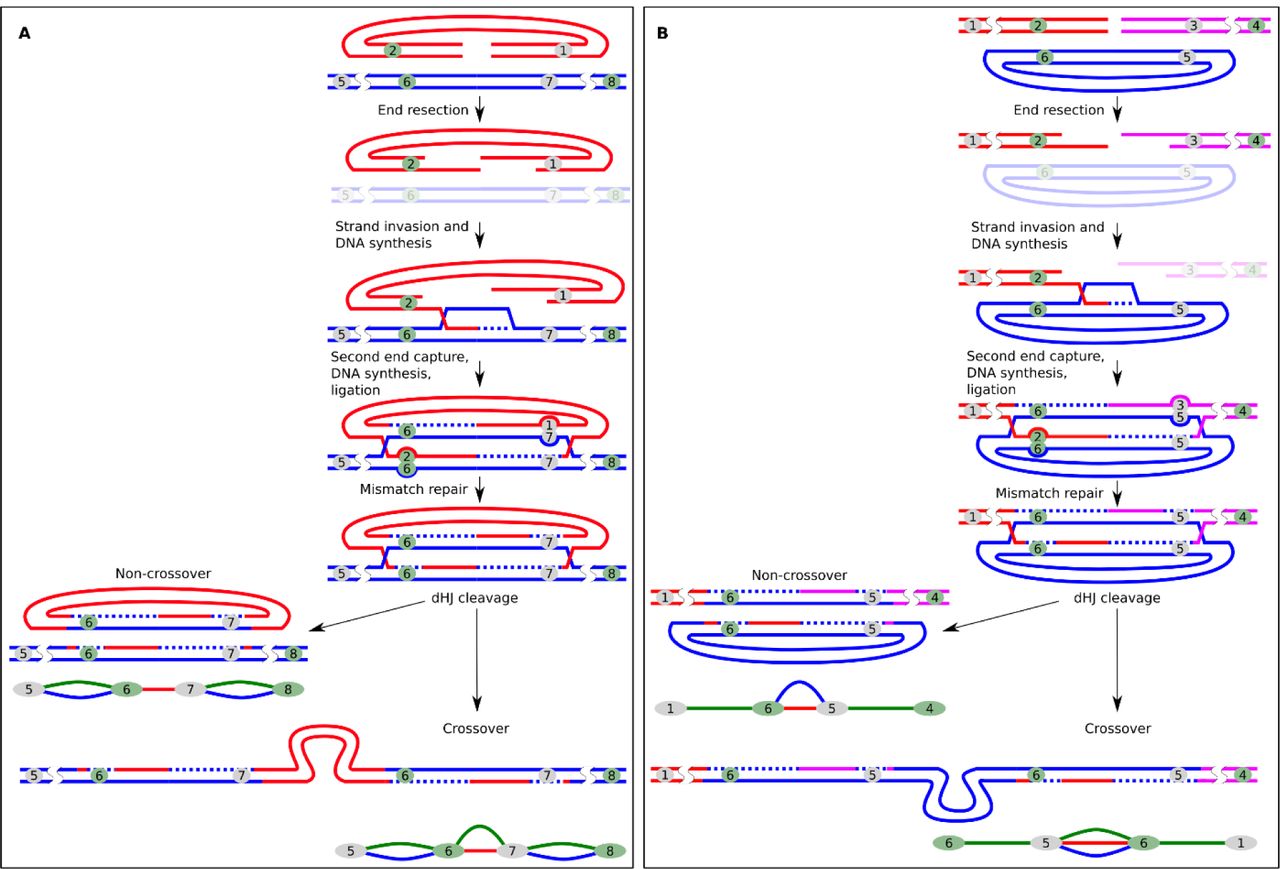
Principle of recombination between transgene copies causing barcode “switching”. Stages common to all pathways of homologous recombination (A) and stages characteristic of DSBR (B) and SDSA (C). The numbers denote barcodes. Outcomes of recombination are shown as elements of the transgene “subway map”. The mismatch repair steps are shown in the box.
Evidence of dHJ formation
In the schemes described above, SDSA products are indistinguishable from non-crossover DSBR products (Fig. 4 and Sup. Fig. 17). However, we found three connection patterns that strongly support the fact of dHJ resolution with crossing-over. dHJ pattern 1: If both ends of a single transgene molecule invade one junction, dHJ is formed and can be resolved with the formation of crossover products. This leads to the integration of the “attacking” copy between the two original ones, and both of the “attacking” copy’s barcodes are overwritten by those in the junction (Fig. 5A). On our concatemer maps, this is represented by paired green and red connections. For example, there are two such connections in the embryo #1 (Sup. Fig. 7) and 32 in total (Table 1). Interestingly, if dHJ is resolved without formation of crossover products, then the attacking molecule becomes circularized. Such circles are either lost during cell division or serve as templates for other linear transgene copies.

Resolution of dHJs during DSBR leads to characteristic connection patterns. (A) Crossing-over between copies could result in assimilation of another copy (“attacker”) into junction with loss of the “attacker”’s barcodes (green + red pattern). (B) DSBR between linear ends and a circular copy can have two detectable outcomes: circular copy donates barcodes without crossing-over (red + blue pattern) or gets incorporated into “attacking” molecule while also donating barcodes (green + red + blue pattern). Outcomes of recombination are shown as elements of the transgene “subway map”.
dHJ pattern 2: Another crossover scenario occurs when a single circular copy is attacked by the ends of two other molecules (Fig. 5B). In this case, dHJ resolution with the formation of crossover products leads to the joining of all three copies, while the “attacking” molecules copy barcodes from the circular template. This outcome appears as two barcodes linked by three connections at once. There are five such structures in our maps (Table 1). In addition, even if the “attacking” molecules copy barcodes from the template without crossing-over and physical integration of the circular copy, we would still see such events (Fig. 5B). On our maps, such barcodes are connected by red and blue connections (dHJ pattern 3). This pattern is characteristic of a circularized copy as well. However, these are only a few (11 of 1066 total molecules in our analysis), which says that the closure of a single molecule in a ring is a rare event (Table 1). This is important, because according to the initial theories, circularization and subsequent random breakage were considered one of the key stages of the formation of concatemers (28).
We would like to emphasize that although we found only sparse evidence of crossing-over (5% of the copies) (dHJ patterns in Table 1), all of these were simple, categorizable cases which are just a tip of the iceberg, as many simultaneous recombination events must have created higher order patterns. For instance, crossovers could be formed by multicopy tandems that are incorporated into junctions (this would result in a side loop on transgene “subway map”). As many of the individual transgenes also switch barcodes by junction invasions, this side loop would be connected to multiple nodes in other concatemer regions, thus vanishing in the complex “subway map” (like in embryos #2, 3, 4, 7, 8) (Sup. Fig. 8, 9, 10, 13, 14).
Role of NHEJ in concatemer formation
Our data suggests that HR plays a leading role in the formation of tandemly oriented copies, but as noted earlier, initially HR requires template junctions created by NHEJ. Since the typical signatures of NHEJ are small indels at the repair sites (4), we decided to explore the repertoire of indels at the transgene-transgene junctions in multicopy embryos (#2, 3, 7). In total, we analyzed the sequences of junctions adjacent to 1803 barcodes. We found almost a hundred possible variants for the structure of ligation sites between copies (Fig. 6A). However, the frequency of sequence variants was distributed very unevenly, so that the three most frequent variants were found in 80% of the junctions (Fig. 6B). These top 3 variants were the same in all examined embryos. These variants were clippings of the protruding 4 nt 5’-ends: -5 nt (Var1), -5 nt (Var2), -7 nt (Var3). Remarkably, other deletions of the same or even smaller size were rare (Fig. 6A). The fact that identical indels appeared in three independently injected zygotes confirms that NHEJ has preferred ligation products. In our case, processing of the 5’-overhangs might have revealed complementary nucleotides (GA in Var1 and AG in Var3), hence favoring ligation of these variants over others. Recent rigorous analysis of NHEJ patterns in mouse ES cells (31) demonstrated that 5’-protruding ends are repaired by either NHEJ or TMEJ (polymerase theta-mediated end-joining). In our case, sequence variants Var1-3 did not have any additional insertions or SNPs and formed uniform clusters, thus TMEJ activity could be excluded (Fig. 6B).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sequence variants of indels at the junctions. (A) 4 nt 5’-protruding ends were generated by BsmBI digestion prior to microinjection. Sequence variants of the transgene-transgene head-to-tail junction region (Var1-Var93) are aligned below the original sequence. In most of the junctions, end processing removed only 5’-overhangs. (B) We calculated junction variant frequency for all detected mutations. Diagram shows distribution of the top three variants (Var1, 2, 3) and remaining variants (“all other”) in analyzed embryos.
Unfortunately, the fact that NHEJ favored few junction variants disrupted our initial idea to estimate the total number of transgene molecules, which were independently joined by NHEJ and served as template for HR. Nevertheless, information about sequence of the junctions made it possible to check our prediction that the result of the joining of molecules by HR mechanism would be an exact copying of the template junction. For example, different copies with the same barcodes in dHJ patterns (Fig.5) should also have the same variant of junction. We checked it and this is true for most of the cases. Only in 8% of cases, the barcode had not one, but two different variants of the junction (data not shown).
We can roughly estimate efficiency of NHEJ-mediated ligation: the number of independent NHEJ-ligated molecules should be no less than the number of unique junction variants from the embryos. According to our data, this corresponds to 1 event per 10 injected copies. Obviously, this is the lower estimate and the real value is several times higher. We also did not analyze other copy orientation variants (head-to-head or tail-to-tail), because their sequencing was impossible due to technical reasons (see Discussion section and Sup. Fig. 6). In general, we can conclude that NHEJ plays a prominent role during initial ligation of exogenous DNA in zygote.
Discussion
Concatemers are a prominent feature of pronuclear microinjection method (Sup. Table 1). To our knowledge, the only paper that addressed the mechanism of concatemer formation was published by Mario Capecchi group more than 35 years ago (14). In this seminal experiment, albeit performed on cultured mammalian cells, nuclei were injected with 2-500 copies of DNA molecules (linear or circular). In addition to clarifying various technical aspects, the group also devoted a part of the report to investigating how concatemers are formed. They injected nuclei with a mixture of two similar transgenes, A- and B-molecules, - plasmid backbones with HSV thymidine kinase gene in two orientations. Southern blot analysis with specific restriction enzymes showed that transgene concatemers consisted of interspersed tandemly oriented A/B copies. This elegant effort challenged transgene amplification hypothesis, but authors were cautious about low copy number integrations and random fluctuations due to the presence of only two transgene versions. Our data unequivocally confirm that concatemers are formed by recombination of individual transgenes without de novo amplification.
We also managed to obtain decisive evidence that head-to-tail tandems are mostly formed by HR between linear copies. We base this conclusion on the lack of red+blue double connections (self-circularized copies). SDSA and DSBR are two main ways of repairing double-stranded DNA breaks by homologous recombination (5). These pathways have similar initial stages and usually resolve into indiscernible non-crossover products, evident in the form of barcode “switching” in our assay (green connections without blue connection from initial plasmid library). However, DSBR sometimes manifests itself in the formation of crossover products after dHJ resolution. We found several convincing examples of crossovers leaving traces at the concatemer “subway map” (5% copies) (Table 1). As far as we know, this is the first described case of somatic crossing-over in early mammalian embryos. Apparently, the formation of crossovers is quite dangerous for somatic cells as it can lead to the loss of heterozygosity of a large chromosome fragment (32). The fact that crossing-over is not completely suppressed in early embryos is of interest and expands our scarce knowledge of DNA repair at this stage.
In addition to crossovers and barcode “switching”, we also noticed another indication of HR activity. Analysis of junctions and transgene-genome integration sites revealed that sometimes transgene copies contain junction sequences, corresponding to the D-loop disruption intermediates (33). One can imagine that resected transgene’s 3’-end invades homologous template at the transgene-transgene junction, copies a portion of junction, and then, after D-loop disruption, it gets incorporated into concatemer or genome by NHEJ or MMEJ (Sup. Fig. 19). We also noticed similar pattern in some published transgene integration models (34, 35). We have two reasons to suspect SDSA involvement, instead of traditionally accepted random breakage explanation. First of all, junctions which border these fragments lack blue barcode connection and does not originate from a self-ligated copy. Second, these fragments are frequently terminated at the barcode sequence, which hints that synthesized displaced strand probably could not reinvade homologous duplex, because of barcode heterogeneity. These cases demonstrate that HR intermediates could be processed by NHEJ at par with fragmented copies. It is also worth mentioning, that we couldn’t directly detect activity of alternative HR pathways, such as single-strand annealing (SSA) and break-induced replication (BIR). SSA might potentially link randomly broken transgene circles (formed after initial circularization) and therefore result in red + blue connections, which were in fact very rare. BIR would manifest itself as amplification of contiguous regions of concatemers, and, indeed, we found one region encompassing 3 transgene molecules with double read counts (embryo #3) (Fig. 2B), but this was a single event. We deduced that these pathways do not contribute to the concatemer formation, probably because long-range resection is prevented by competition with SDSA (36).
The real proportion of NHEJ-processed copies in concatemers has always remained enigmatic. Southern blot estimations from many transgenic mouse lines (Sup. Table 1) confirm that head-to-tail orientation is dominant (>90% of copies vs 50% in case of random ligation). Likewise, our transgene “subway maps” display contiguous tandem head-to-tail chains (>10 copies) with no gaps (e.g. in embryos #1 (Sup. Fig. 7), #4 (Sup. Fig. 10A) or #9 (Sup. Fig. 15A)). Unfortunately, studying complex rearrangements in concatemers is nearly impossible at present, because PCR is not suitable for detection of palindromic junctions (our experience; (37)), and repetitive nature of concatemers complicates NGS-based methods (38, 39). However, it is well established that NHEJ often contributes to concatemer emergence with fragmented and truncated copies arranged in random orientation (38, 40). We ourselves detected truncated copies in most of transgenic embryos and their abundance correlated with transgene copy number (Sup. Fig. 5A,B).
Why is there no perfect palindromic head-to-head or tail-to-tail junctions then? Palindromic sequences are quite stable in mammalian cells (41), thus palindromes are likely wiped out at the initial step, during extrachromosomal recombination. We documented high activity of HR recombination between ends (>80% of copies) and it made us believe that frequent strand invasion and D-loop formation could provoke secondary structures such as hairpins and cruciforms in template palindromic junctions (Sup. Fig. 20). Another possible HR-related mechanism is folding back of the single-stranded resected end of a linear transgene after copying fragment of the palindromic junction (42). These hairpin structures are next recognized and removed by cell repair systems.
Ultimately, we aimed to utilize barcode connections to figure out unequivocal transgene order in concatemers. The closest we achieved this goal was in embryo #1 (only 1 gap unresolved) (Sup. Fig. 7), embryo #9 (Sup. Fig. 15A) and embryo #10 (Sup. Fig. 16). In embryo #9, tandemly oriented chains of variable lengths are presumably separated by inverted copies (full-sized or truncated). We sequenced some of them (Sup. Fig. 15B). Lastly, embryo #10 puzzled us with complex barcode distribution pattern. As seen in Sup. Fig. 16, transgene “subway map” in this embryo has quite peculiar plan with four transgene copies but only 2 unique barcode pairs (8 barcodes total). We validated duplication of each barcode with ddPCR (Sup. Table 2). We employed long-distance PCR with barcode-specific primers to position all copies and their respective barcodes in the four-copy concatemer (Sup. Fig. 16). It appears that two initially ligated copies with unique barcode pairs underwent recombination and assimilated two other copies. It definitely was not a simple duplication event, because barcodes were shuffled between copies.
Concluding remarks
Using DNA barcodes helped us to explain some of the long-standing questions in the field of transgenesis. First of all, we showed that hundreds of copies are joined together independently without contribution of long range de novo synthesis. Terminal barcodes were also useful to track self-ligated copies and we found no concatemer contribution from such rings, although it had been frequently proposed that concatemers are formed by recombination of overlapping fragments of broken circular copies. In theory, injection of circular copies that go through random breakage and recombine with backbone regions must lead to complete disappearance of barcode “switching” in our assay. Clearly, understanding HR regulation in zygote will be of great importance for implementation of revolutionary transgenesis methods such as newly designed gene drivers (43) or contiguous DNA assembly by overlaps (44), and might help finetune HR to prevent unwanted recombination that complicates CRISPR/Cas9 knock-in experiments (45).
Funding
This work was supported by Russian Science Foundation [grant #16-14-00095], NGS libraries preparation was partially performed using experimental equipment of the Resource Center of the Institute of Cytology and Genetics SB RAS (state project No. 0324-2019-0041).
Authors Contribution
AS and NB initiated the study. AY constructed barcoded plasmid library. AK and IS carried out the mouse experiments. AS performed the experiments. AS, VF and NB analyzed data. AS and NB wrote the manuscript. All authors read and approved the final version of the manuscript.
Footnotes
Email addresses: AS hldn89{at}gmail.com; AY yunusova-nastya92{at}mail.ru; AK: korablevalexeyn{at}gmail.com; IS irina_serova2004{at}mail.ru; V.F. minja-f{at}ya.ru; N.R. battulin{at}bionet.nsc.ru
References
REFERENCES




