

Abstract
The dependence between pairs of time series are commonly quantified by Pearson’s correlation. However, if the time series are themselves dependent (i.e. exhibit temporal autocorrelation), the effective degrees of freedom (EDF) are reduced and the standard error is biased. This issue is vital in resting-state functional connectivity (rsFC) since the fMRI time series are notoriously autocorrelated and therefore rsFC inferences will be biased if not adjusted. We find that the available EDF estimators make restrictive assumptions that are not supported by the data, resulting in biased rsFC inferences that lead to distorted topological descriptions of the connectome. We propose a practical method that accounts not only for distinct autocorrelation in each time series, but instantaneous and lagged cross-correlation. In addition to extensive synthetic and real data validations, we investigate the impact of this correction on rsFC measures in data from the Young Adult Human Connectome Project.
1 Introduction
Resting-state functional connectivity (rsFC), the neuronal interaction between the brain regions in the absence of any external stimuli, has been proven to be an effective technique for gaining a deeper understanding of the human brain. Many rsFC methods make use of temporal correlation estimated with the Pearson product-moment correlation coefficient, often converted to a Z-score via Fisher’s transformation. However, standard results for the variance of Pearson’s correlation (before or after Fisher’s transformation) depends on independence between successive observations. fMRI time series are autocorrelated (i.e. correlated with temporally-lagged version of themselves), and autocorrelation inflates the sampling variance of Pearson’s correlation (we interchangeably use the terms autocorrelation and serial correlation throughout this work). This variance inflation – equivalently, reduction in effective degrees of freedom (EDF) – generates excess false positives and dramatically biases rsFC measured in Fisher’s standardized Z-scores.
Although autocorrelation has been thoroughly investigated in task fMRI analysis (Friston et al., 2000; Woolrich et al., 2001; Lund et al., 2006), there is much less work on resting-state analyses. The first reference we are aware of directly addressing the issue is Fox et al. (2005) which refers to “Bartlett’s Theory”, citing Watts and Jenkins (1968). Later, Dijk et al. (2010) uses the same approach, labeled “Bartlett’s Correction Factor”, describing it as the “integral across time of the square of the autocorrelation function”; as discussed below, this “integral” is of course a sum for discretely sampled fMRI data and, while not necessarily implied, must include both positive and negative lags of the autocorrelation function (ACF). The nominal N is divided by this BCF to give an EDF (see Section 2.2.1).
While these previous works use an arbitrary ACF, other authors have used an order-1 autoregressive (AR(1)) model. For example, the FSLnets toolbox (Smith et al., 2011) uses a Monte Carlo approach to estimate the variance of sample correlation coefficients (see Section 2.2.2). However, it only considers a single autocorrelation parameter over all nodes. More recently, Arbabshirani et al. (2014) made a thorough study of Pearson correlation variance for AR(1) time series, where, crucially, the AR(1) coefficient can vary between the pair of variables and non-null correlations were considered1.
Wavelet representation of time series are particully useful for handling autocorrelation, and Patel and Bullmore (2015) and Váša et al. (2018) use wavelet EDF-estimators initially proposed by Percival and Walden (2006) in analysis of functional connectomes obtained via wavelet transformation coefficients (Leonardi and Van De Ville, 2011).
Further, Fiecas et al. (2017) proposes an inference framework for group-level analysis of functional connectomes which accounts for the autocorrelation via the variance estimator of Roy (1989). Roy’s estimator is unique among the previous methods as it directly accounts for dependence within and between the time series, and is closely related to our method (see Section 2.2).
Alternatively, other studies have proposed pre-whitening on the resting-state BOLD time series (Christova et al., 2011; Lewis et al., 2012; Bright et al., 2017). For example, Bright et al. (2017) has used pre-whitening methods, inherited from task fMRI analysis (Bullmore et al., 1996), to account for autocorrelation in resting-state analysis. Although pre-whitening is a well-established technique in task fMRI, its application in rsFC is yet to be fully investigated. Firstly, pre-whitening in fMRI will tend to attenuate low frequency components while amplifying the high frequency ones, which seems poorly suited to the low-frequency nature of the BOLD signal. Secondly, choosing an optimal model for autocorrelation, in absence of a task paradigm, appears to be troublesome (see Bright et al. (2017)). Finally, spatial regularisation used some neuroimaging toolboxes (e.g. FSL’s FILM) are designed for voxelwise or vertex wise analyses and would need to be adapted to Region of Interests (ROIs) data.
The concern about effect of autocorrelation on Pearson’s correlation has a long history in spatial statistics (Haining, 1991), econometrics (Orcutt and James, 1948) and climate sciences (Bretherton et al., 1999), but the fundamental work is Bartlett (1935), who first asserted that the lack of independence (between observations) is a bigger challenge than non-Gaussianity. In his 1935 paper, Bartlett proposes a variance estimator of sample correlation coefficients based on a AR(1) model, but he acknowledges that a limitation of the work is that it assumes zero cross-correlation. In later work he proposed a more general estimator which accounts for higher order AR models (Bartlett, 1946) but still fails to account for cross-correlation. Two extensions to the work has been proposed by Quenouille (1947) and Bayley and Hammersley (1946) where the former adapts the estimator to the cases where the autocorrelation functions are not identical across the two time series and the latter down weights the autocorrelation of long lags. Several years later Clifford et al. (1989) also proposed a reformulation of Bayley and Hammersley (1946). We have found little comparative evaluation of these methods in the literature, save Pyper and Peterman (1998) that compared False Positive Rates on low order autoregressive models of uncorrelated time series.
Importantly, save for the work of Roy (1989), all of the methods we have discussed so far have been derived under the rsFC null hypothesis (i.e. independence between the two series). This null encomposes both zero instantaneous and lagged cross-correlations. This is problematic for rsFC, as typically the challenge is not only to detect edges but also to measure the strength of the connectivity. Moreover, as we show below, ignoring non-null lagged cross-correlation induces biases in estimation of the variance, even in absence of autocorrelation. We identify the confounding responsible for this effect (see Section D).
In this work we propose a variance estimator, which we call xDF, which imposes no assumptions on the (intra-time-series) autocorrelation or (inter-time-series) correlation of the time series. To motivate and introduce our results, Figure 1 shows correlation of BOLD time series of Left Dorsal Prefrontal Cortex (PCFd) from one HCP subject to all 114 ROIs (i.e. parcellated with Yeo atlas) of a different HCP subject. Due to the random nature of resting-state BOLD time series, we expect 5% of the 114 correlation coefficients to be significant; instead, the standard Fisher’s z result (see Section 2.4) finds 35.7% of the regions significant controlling the false discovery rate (FDR) at 5% (Figure 1.D). After application of our xDF correction, no regions survive FDR correction (2.6% of nodes were found to be significant, at the nominal level of 5%). A plot of xDF-adjusted z-scores against Naive z-scores shows the dramatic difference in values (Figure 1.D). Observe how L-SoMotCent (blue marker) is incorrectly detected and is highly auto‐ and cross-correlated (blue ACF, Figure 1.E). This causes the z-score of the correlation to be greatly reduced. In contrast, R-Insula (red marker) has essentially the same Naive and xDF-adjusted z-score and has nearly zero autocorrelation (red ACF, Figure 1.E).

Analysis of null resting state functional connectivity to illustrate the problem of inflated correlation coefficient significance. Panel A shows standardised BOLD data for the Left Dorsal Prefrontal Cortex (PFCd) of HCP one subject (HCP-1). Panel B illustrates the standardised BOLD time series of R-Insula (red) and L-SomMotCent (blue), illustrating the dramatically different degree of autocorrelation. Panel C maps the z-scores of correlation between this PCFd region and time series from a different HCP subject (HCP-2), parcellated with the Yeo’s atlas and overlaid on an MNI standard volume. Panel D compares Z-scores accounting for autocorrelation vs. naive Z-scores, showing apparent significance (in this null data) with naive Z-scores and lack of significance for xDF-adjusted Z-scores. On the horizontal axis are naive Z-scores that ignore autocorrelation, while on the vertical axis are Z-scores adjusted according to xDF. Uncorrected critical values (±1.96) are plotted in dashed lines, FDR-corrected critical values as solid lines; for xDF-corrected Z-scores, no threshold controls FDR at 5% but an arbitrary threshold is shown at ±4. Panel E shows autocorrelation of each time series (left). Horizontal solid lines indicate the confidence intervals calculated as described in Section 2.3. The difference in magnitude and form of autocorrelation among the three time series is evident, with PFCd exhibiting strong, long-range autocorrelation and R-Insula showing virtually no autocorrelation. Also shown is the the cross-correlation (right panels) between HCP-1’s PCFd and HCP-2’s Left Central SomatoMotor Cortex (L-SomMotCent) (top), and HCP-1’s PCFd and HCP-2’s Right Insula (R-Insula) (bottom).
The remainder of the work is as follows. We first present a concise overview of the model and the proposed estimator. Second, we discuss the importance of accounting for unequal autocorrelation between the pair of variables, i.e. node-specific autocorrelation, by showing how the autocorrelation structures are spatially heterogeneous and dependent of parcellation schemes. Third, we discuss how ignoring such effects may result in spurious significant correlations and topological features. Fourth, using Monte Carlo simulations and real-data, we show how xDF outperforms all existing available variance estimators. And finally, we show how using xDF may change the interpretation of the rsFC of the human brain. The potential impact of such corrections on interpretation of rsFC is investigated for conventional thresholding method (i.e. statistical and proportional) as well as un-thresholded functional connectivity maps.
2 Methods
2.1 Notation
Without loss of generality, we assume to have mean zero and unit variance time series X = {x1, …, xN} and Y = {y1, …, yN}, each of length N, have  and
and  , respectively; we write the covariance between X and Y as
, respectively; we write the covariance between X and Y as  ; we assume stationarity, and thus have Toeplitz ΣX, ΣY and ΣXY, and denote auto-correlations
; we assume stationarity, and thus have Toeplitz ΣX, ΣY and ΣXY, and denote auto-correlations
 where k = i − j, likewise for Y. The cross-correlations between X’s time point i and Y’s time point j is
where k = i − j, likewise for Y. The cross-correlations between X’s time point i and Y’s time point j is
 where k = j − i. The key rsFC parameter is ρXY,0, the cross-correlation at lag 0, which we refer to as simply ρ going forward. Note we do not assume that cross-correlations are symmetric, i.e. ρXY,k and ρXY,−k are distinct.
where k = j − i. The key rsFC parameter is ρXY,0, the cross-correlation at lag 0, which we refer to as simply ρ going forward. Note we do not assume that cross-correlations are symmetric, i.e. ρXY,k and ρXY,−k are distinct.
2.2 Variance of Sample Correlation Coefficients
For the sample correlation coefficient for mean zero data,  , in Appendix B we derive a general expression for its variance:
, in Appendix B we derive a general expression for its variance:

For stationary covariance (see Appendix C), we can rewrite Eq. 1 as
 where wi = N − 2 − k. While Eq. 2 takes the same form as the estimator of Roy (1989), we obtain our result from finite sample as opposed to asymptotic arguments (see Appendix B).
where wi = N − 2 − k. While Eq. 2 takes the same form as the estimator of Roy (1989), we obtain our result from finite sample as opposed to asymptotic arguments (see Appendix B).
It is also useful to discuss two special cases of the Eq. 1. First, suppose two time series X & Y are both white but correlated such that ΣX = ΣY = I, and ΣXY = Iρ. Eq. 1 then reduces to
 a well-known result for the variance of the sample correlation coefficients between two white noise time series (see §5.4 in Lehmann (1999b)).
a well-known result for the variance of the sample correlation coefficients between two white noise time series (see §5.4 in Lehmann (1999b)).
Second, suppose X and Y are autocorrelated but are uncorrelated of each other, with non-trivial ΣX and ΣY but ΣXY = 0. Then, Eq. 1 reduces to

a result on the variance inflation of ρ̂ in spatial statistics, proposed by Clifford et al. (1989) and also discussed as the variance of the inner product of two random vectors in Brown and Rutemiller (1977). Written in summation form (see Appendix C) this expression is
 a result proposed much earlier by Bayley and Hammersley (1946) which has found use in neuroimaging (Nicosia et al., 2013; Valencia et al., 2009). A closely related form (Dutilleul et al., 1993) that adjusts for mean centering has also been used in neuroimaging (Nevado et al., 2012; Pannunzi et al., 2018), though for typical time series lengths (i.e. N » 20) there should be little difference from the original result.
a result proposed much earlier by Bayley and Hammersley (1946) which has found use in neuroimaging (Nicosia et al., 2013; Valencia et al., 2009). A closely related form (Dutilleul et al., 1993) that adjusts for mean centering has also been used in neuroimaging (Nevado et al., 2012; Pannunzi et al., 2018), though for typical time series lengths (i.e. N » 20) there should be little difference from the original result.
2.2.1 Effective Degrees of Freedom for the Correlation Coefficient
One way of dealing with autocorrelation is to modify a variance result that assumes no autocorrelation, replacing N with a deflated EDF N̂. This can be done in terms of ρ̂ (e.g. Eq. 3) or after Fisher’s transformation; here we consider EDFs for ρ̂ and return Fisher’s transformation in Section 2.4.
Different corrections have been proposed to estimate N̂. One of the earliest results is due to Bartlett (1935), who proposed an EDF for uncorrelated (ρ = 0) AR(1) time series:

We refer to this EDF estimator as B35.
Building on work of Bartlett (1946), Quenouille (1947) proposed a more general EDF that allowed for any form of autocorrelation,
 though still assuming ρ = 0. We refer to this EDF estimator as Q47.
though still assuming ρ = 0. We refer to this EDF estimator as Q47.
In neuroimaging, a global form of Eq. 7 has been used, where the a single ACF ρGG,k is computed averaged across voxels or ROIs for each subject, or even over subjects (Fox et al., 2005; Dijk et al., 2010); it takes the form

We refer to this EDF as G-Q47.
Finally, the variance result due originally Bayley and Hammersley (1946) and Clifford et al. (1989) (Eqs. 4 & 5), gives EDF
 still under an independence assumption ρ = 0. We refer to this EDF as BH.
still under an independence assumption ρ = 0. We refer to this EDF as BH.
Whether defined with infinite or finite sums, some sort of truncation or ACF regularisation is required to use these results in practice, which we consider in Section 2.3.
2.2.2 Monte Carlo Parametric Simulations
The one other approach we evaluate is Monte Carlo parametric simulation (MCPS) (Ripley, 2009). In this approach the variance of the sample correlation is estimated from surrogate data, simulated to match the original data in some way. If a common autocorrelation model and parameters are assumed over variables and subjects, this can be a computationally efficient approach. For example, the FSLnets2 toolbox for analysis of the functional connectivity assumes an AR(1) model with the AR coefficient chosen globally for all subjects and node pairs. While MCPS avoids any approximations for a given model, it can only be as accurate as the assumed model.
We evaluate the method used by FSLnets, which chooses the number of realisations set equal to the number of nodes. We refer to this as AR1MCPS.
2.3 Regularising Autocorrelation Estimates
All of the advanced correction methods described depend on the true ACFs ρXX,k, ρY Y,k and some on the cross-correlations ρXY,k. We expect true ACFs and cross-correlations to diminish to zero with increasing lags, but sampling variability means that substantial non-zero ACF estimates will occur even when the true values are zero. Thus all ACF-based methods use a strategy to regularise the ACF, by zeroing or reducing ACF estimates at large lags.
Several arbitrary rules have been suggested for truncating ACF’s, zeroing the ACF above a certain lag. For example, Anderson (1983) suggests that the estimators should only consider the first  lags or Pyper and Peterman (1998) has found that truncating at
lags or Pyper and Peterman (1998) has found that truncating at  lags is optimal. Hence in this work we use the
lags is optimal. Hence in this work we use the  cut-off for our truncated ACF estimator.
cut-off for our truncated ACF estimator.
Smoothly scaling ACF estimates to zero is known as tapering. Chatfield (2016) suggests tapering methods using Tukey or Parzen windows. For example, for Tukey tapering, the raw ACF estimate is scaled by  for k < = M and zeroed for k > M. Similar to truncating, finding the optimal M appears to be cumbersome; Chatfield (2016) suggests an M of
for k < = M and zeroed for k > M. Similar to truncating, finding the optimal M appears to be cumbersome; Chatfield (2016) suggests an M of  while Woolrich et al. (2001) propose the more stringent
while Woolrich et al. (2001) propose the more stringent  ; for a detailed comparison of tapering methods see Woolrich et al. (2001).
; for a detailed comparison of tapering methods see Woolrich et al. (2001).
In this study we consider fixed truncation and Tukey tapering, as well as an adaptive truncation method. For our adaptive method, we zero the ACF at lags k ≥ M, where M is the smallest lag where the null hypothesis is not rejected at uncorrected level α = 0.05, based on approximate normality of the ACF and sampling variance of  . We base the truncation of the cross-correlation ρXY,k on the ACFs of X and Y, choosing the larger M found with either time series.
. We base the truncation of the cross-correlation ρXY,k on the ACFs of X and Y, choosing the larger M found with either time series.
2.4 Statistical Testing
Inference on H0 : ρ = 0 can be conducted directly on ρ̂ or after applying Fisher’s transformation, arctanh(ρ̂). This transformation has approximate variance
 and in fact is derived to cancel the effect of ρ on
and in fact is derived to cancel the effect of ρ on  under uncorrelated sampling – recall
under uncorrelated sampling – recall  (Eq. 3) for this case; Fisher derived a more precise variance in this setting of
(Eq. 3) for this case; Fisher derived a more precise variance in this setting of  (yet this is still an approximation; see Fouladi and Steiger (2008)).
(yet this is still an approximation; see Fouladi and Steiger (2008)).
Following practice in the field, we do not consider inference using ρ̂ but focus our evaluations only on Fisher’s transformed sample correlations, Z-scores of the form

The particular correction method used determines  . For xDF we use Eq. 1, while for all other methods we use the nominal variance with an EDF, i.e.
. For xDF we use Eq. 1, while for all other methods we use the nominal variance with an EDF, i.e.  ; Naive has N̂ = N − 3, and each other EDF method uses their respective estimate N̂, as described in Section 2.2.1.
; Naive has N̂ = N − 3, and each other EDF method uses their respective estimate N̂, as described in Section 2.2.1.
2.5 Simulations and Real Data Analysis
The xDF is validated and compared with other existing estimators via series of Monte Carlo simulations and real data experiments. We simulate time series with complex autocorrelation, under both uncorrelated and correlated conditions, using ACF parameters estimated from one HCP subject (see Section 3.4). We generate null realisations with real data by randomly exchanging the nodes between subjects (see Section S3.6). From both of these sources of null data we evaluate the distribution of z-scores and false positive rates.
To investigate sensitivity as well as specificity, we simulate correlation matrices, transformed to z-scores with each method, with a known proportion of edges with non-null (ρ > 0) edges (see Section S3.5). Sensitivity, specificity, accuracy (sum of the former) and area-under-the-ROC-curve is computed for each method.
We consider graph metrics computed on real data, with z-scores computed with each method. We use one session of resting state data from each of the 100 unrelated HCP subjects. This data was pre-processed (Section S4) and we created P × P resting-state functional connectivity matrices (z-scores), where P is number of ROIs, depending on the choice of parcellation scheme; we use the Yeo, Power and Gordon atlas in their volumetric form and ICA200 and Multimodal Parcellation (MMP) in surface mode (see Section S4.1). The rsFC matrices were then thresholded using two conventional thresholding methods; statistical thresholding (see Section S4.3) and proportional thresholding (see Section S4.4). Finally, the effect of the autocorrelation corrections on two centrality measures (weighted degree and betweenness) and one efficiency measure (local efficiency) are investigated (see Section S4.5.3).
In all our evaluations we estimate the ACFs from the time series, incorporating this important source of uncertainty (Algorithm 2 in SM). An exception are “Oracle” simulations in which the true ACF parameter values are used when estimating the variance (see Algorithm 1 in SM).
2.6 Autocorrelation Length
To summarise the strength of autocorrelation effect on time series X of length N, we define the autocorrelation length (ACL), τX, as

3 Results
3.1 Autocorrelation and Parcellation Schemes
We find that the degree of autocorrelation of resting state data is highly heterogeneous over the brain, Figure 2.A shows a map of voxel-wise autocorrelation length, averaged across 100 subjects, finding values range from 1 to 4. We found that using parcellation schemes not only fail to reduce the spatial heterogeneity, but instead magnify the autocorrelation effects: Figure 2.B shows autocorrelation lengths for three ROIs of Yeo’s atlas, for each voxel in an ROI and as ROI averages: Left posterior cingulate (LH-PCC; 1091 voxels), Left somatosensory motor (LH-SomMot; 4103 voxels) and Left dorsal prefrontal cortex (LH-PFC; 19 voxels). This shows the dramatic increase in autocorrelation that comes with averaging within ROIs (see Appendix E for the likely origin of this effect).

Variation in strength of autocorrelation over space within an atlas, and between atlases. Panel A maps autocorrelation length (ACL) voxelwise and for 3 different atlases; variation is particularly evident for Yeo and Gordon; Power is more homogeneous (but see Panel D). Panel B shows ACL of three regions of interests (ROIs) from the Yeo atlas, for voxels within each ROI (left plot) and ROI-averaged time series (right plot); ROIs are Left Posterior cingulate (LH-PCC), Left somatosensory motor (LH-SomMot) and Left dorsal prefrontal cortex (LH-PFC). Averaging within ROIs dramatically increases the strength of autocorrelation. Panel C plots the ACL, averaged over subjects of the HCP 100 unrelated-subjects package, vs. region size for ICA time series and three atlases, where ICA and one atlas (MMP) are surface-based. There is a strong relationship between ACL and ROI size. The “ROI size” for ICA is defined as number of voxels in each component above an arbitrary threshold of 50. For MMP, the ROI size is defined as number of vertices comprising an ROI. Panel D considers the Power atlas, which has identically sized spherical ROIs, plotting ACL vs. distance to a voxel in the thalamus. Cortical ROIs have systematically larger ACL than subcortical ROIs. Panel E shows variance explained by inter-subject and inter-node ACL profiles for the Gordon, ICA200, Power and Yeo atlases; the large variance explained by inter-subject mean indicates substantial consistency in ACL over subjects.
More generally, we find that the size of ROIs predicts autocorrelation of the ROI in both volumetric and surface-based parcellation schemes (Figure 2.C). Further, not only the size of the ROI, but the location of the ROI influences autocorrelation. Using the Power atlas, where all ROIs have identical volume (81 2mm3 voxels), the autocorrelation in subcortical structures is weaker than in cortical structures, as summarized by plotting autocorrelation length vs. distance to Thalamus (Figure 2.D). While differences in BOLD characteristics between subcortical and cortical voxels could contribute to the autocorrelation structure, it is more likely the higher noise levels (far from the surface coils, and more susceptible to problems of acceleration-reconstruction, in this HCP data) explain the lower autocorrelation length in subcortical regions.
We also quantify the heterogeneity of autocorrelation length using the variance explained by the inter-subject and inter-node mean profile (Figure 2.E). For time series extracted using Power atlas, only 36% of inter-subject variance is explained, while for ICA200 time series up to 73% of inter-subject is explained, showing that the autocorrelation profiles is highly dependent on parcellation scheme. On the other hand, the variance explained of inter-node autocorrelation length is below 12% across all four parcellation schemes suggesting the importance of addressing the autocorrelation as a node-specifically.
3.2 Real-data and Monte Carlo Evaluations
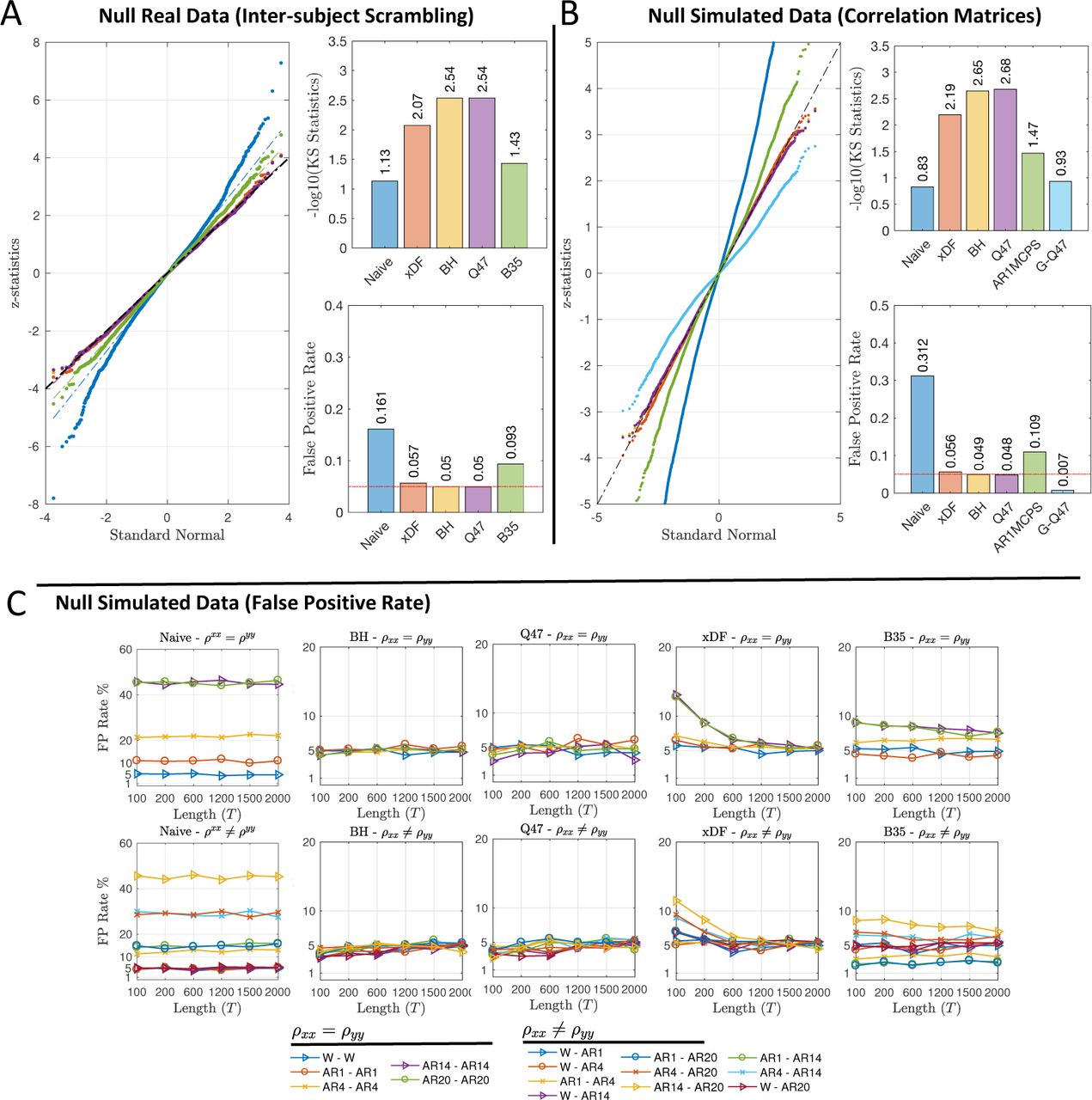
Using inter-subject scrambling of 100 HCP subjects, parcellated with Yeo atlas, to create null realisations with realistic correlation structure, we compare different EDF methods in terms of FPR and distribution of Fisher’s Z scores, both visually via QQ plots and by Kolmogorov–Smirnov (KS) statistics of observed Z scores vs. a standard normal distribution. Results on node-specific autocorrelation corrections in Figure 3A show that Naive and B35 have greatly inflated FPR, while BH and its approximation, Q47, successfully preserve the FPR level at the 5% level while distribution of the both methods closely follow normal distribution (i.e. −log10(KS) = 2.54). Similar results for other FPR levels (%1 and 10%) are also illustrated in Figure S3.

Evaluation of false positive rate control for testing ρ = 0 with different autocorrelation correction methods. Panel A shows results using real data and inter-subject scrambling of HCP 100 unrelated package with the Yeo atlas ROIs, comprising to 235,500 distinct z-scores (see Figure S5 for same results with other atlases). Left shows the QQ plot of Z-scores of each method, top right shows the −log10 KS statistics (larger is better, more similar to Gaussian), and bottom right the FPR, all of which show that Naive and B35 have very poor performance. Panel B depicts a similar evaluation, except a single ACF is used to simulate all time series with identical autocorrelation (see Section S3.5), again under the null; here we additionally consider two “global” correction methods that assume common ACF between the nodes, G-Q47 and AR1MCPS. Here the Naive and the two global methods have poor false positive control. Panel C reports on the FPR at nominal α level=5% across five methods (i.e. columns) for identical (top row) and different (bottom row) ACFs, over a range of time series lengths. Naive (note different y-axis limits) and B35 have poor FPR control, while BH, Q47 and xDF all have good performance for long time series, with xDF having some inflation for the most severe autocorrelation structures with short time series.
Since majority of methods used are not node-specific but instead consider the autocorrelation as a global effect (Fox et al., 2005; Zhang et al., 2008; Hale et al., 2016), we evaluate them under their homogeneity assumption using simulated correlation matrices comprised of uncorrelated time series with strong autocorrelation measured from one particular HCP subject (see Section S3.5 for details). Figure 3B shows comparison of node-specific methods (B35 excepted, due to its poor FPR control) to global methods AR1MCPS and G-Q47. Both global correction methods fail to achieve the desired FPR level and the KS statistics of the two methods are also amongst the lowest; this poor performance is likely due to the simple AR correlation model used by each of these methods. On the other hand, the node-specific methods (xDF, BH and Q47) remarkably improves the FPR and KS statistics. However, for uncorrelated time series, BH and G-Q47 outperform the xDF. Similar results for other FPR levels (%1 and 10%) are illustrated in Figure S4.
We also repeated the FPR and KS analysis of correlation matrices for another sets of simulated correlation matrices, this time with autocorrelation structures drawn from a different subject than above. Results suggest similar FPR and KS statistics except for AR1MCPS which almost meet the FPR-level. This clearly suggests that the performance of the global measures, especially AR1MCPS, are subject-dependent.
We further complement the validation methods with FPR and ROC analysis. Using the same simulation techniques, discussed in section S3.1, we compare the FPR levels for pair-wise uncorrelated time series. Figure 3.C illustrates the FPR of each method for α-level= 5%. Figure 3.C suggests that the Naive correction (first column) can only maintain the desired FPR level when at least one of the time series are white, otherwise, the FPR level can approach 50%, in cases where the both time series are highly autocorrelated. Second and third columns of Figure 3.C shows the FPR levels after the degrees of freedom are corrected via BH and Q47 methods where results suggest an remarkable improvement. Despite both methods having a conservative FPR level on short time series, both successfully maintain the FPR level on larger N. The FPR results for xDF suggest that for short time series, the method fails to contain the FPR level, especially on highly autocorrelated time series, however as N grows, the FPR levels approaches the nominal α-level until N = 2000 where the xDF has the closest FPR level. We finally, evaluate the FPR of B35 where, for majority of the autocorrelation structures, the method has failed to control the FPR level regardless of the sample size. For example, for time series with AR1-AR14 structure, the FPR level is as conservative as 2% while for AR14-AR20 the level exceeds 7%.
Results presented in Figure 3 are for highly autocorrelated, yet uncorrelated, time series (ρ = 0). However, in rsFC, it is the highly correlated time series that are of interest. This motivates us to investigate the accuracy of standard errors for ρ̂ for highly autocorrelated time series, with non-zero cross-correlation, simulated following the model described in Section S3.1. Figure 4.A illustrates the precent bias of standard deviation estimated using xDF (i.e. Eq. 1) across different sample sizes with the two time series having either identical (top panels) or different (bottom panels) autocorrelation structures; we used the adaptive truncation method (see section 2.3) to regularise each ACF.
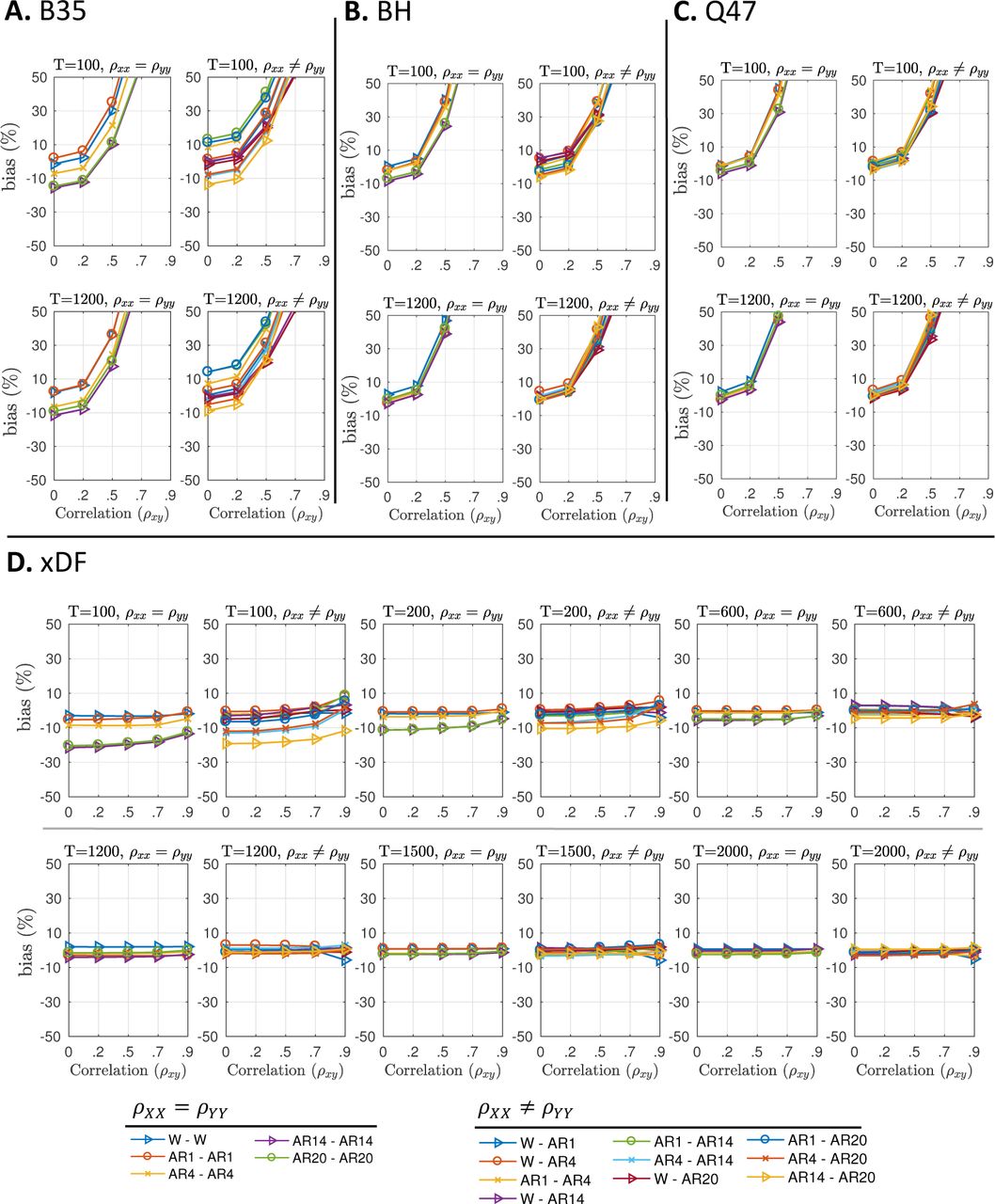
Percentage bias of estimated standard deviation of ρ̂ by each method (Algorithm 2 and Eq. S10 in supplementary materials). Panel A plots the bias of the B35 method for T = 100 (top) and T = 1200 (bottom) for equal (left) and unequal (right) ACF’s. Panel B plots the same for BH, and Panel C for Q47. Panel D, plots the same information for a wider range of time series lengths T. These results show the dramatic standard error bias in BH35, BH and Q47 with increasing ρ. All results here are for our adaptive truncation method; see Figures S6 and S7 bias results with different tapering methods.
For xDF (Figure 4.D), the performance is dramatically better, with less  bias over all and no notable dependence on ρ. The worst performance is for short time series and high-order AR autocorrelation, but for N ≥ 200 bias is mostly within ±5% and improves with N.
bias over all and no notable dependence on ρ. The worst performance is for short time series and high-order AR autocorrelation, but for N ≥ 200 bias is mostly within ±5% and improves with N.
We further investigate the percentage biases for B35, BH and Q47 in Figure 4.B-D, respectively. Figure 4.A, 4.B & 4.C show percent bias of ρ̂ standard error for existing methods, B35, BH and Q47, respectively. While BH and Q47 corrections give mostly unbiased standard errors in case of independence (ρ = 0) there is substantial bias as correlation ρ grows, for both short and long time series length. For example, for ρ = 0.5, BH and Q47 corrections overestimates  by more than 30% bias. The bias for the B35 standard errors show a similar pattern but with biases being more sensitive to particular autocorrelation structure. A notable finding from these ρ ≠ 0 results is for white data (“W-W” for ρXX ≠ ρY Y, blue triangles): For B35, BH and Q47 methods, this ‘easy’ case of no autocorrelation gives just as bad performance as severe autocorrelation. We identified the source of this problem, a confounding of autocorrelation with cross correlation; see Appendix D for details.
by more than 30% bias. The bias for the B35 standard errors show a similar pattern but with biases being more sensitive to particular autocorrelation structure. A notable finding from these ρ ≠ 0 results is for white data (“W-W” for ρXX ≠ ρY Y, blue triangles): For B35, BH and Q47 methods, this ‘easy’ case of no autocorrelation gives just as bad performance as severe autocorrelation. We identified the source of this problem, a confounding of autocorrelation with cross correlation; see Appendix D for details.
Results for Oracle simulation (Figure S2.A) also confirm the confounding of autocorrelation with cross-correlations, as Q47 and BH are both biased even when the true parameters are used, while xDF shows negligible biases across different autocorrelation structures and sample sizes.
We also use the simulations to evaluate ρ̂ standard error bias across different tapering methods (see section 2.3). Figure S7 suggests that despite similarities between the tapering methods on low‐ and mid-range correlations, they differ on higher correlation coefficients where unregularised, Tukey tapered  and truncation
and truncation  autocorrelation functions overestimate the variances while the shrinking and Tukey of
autocorrelation functions overestimate the variances while the shrinking and Tukey of  lags maintain the lowest biases. Although the two methods, Tukey taper with cut-off at
lags maintain the lowest biases. Although the two methods, Tukey taper with cut-off at  lags and adaptive truncation, appear to have very similar biases we notice that adaptive truncation has less bias for short time series. Moreover, adaptive truncation is immune from arbitrary choice of lag cut-off. We therefore use adaptive truncation as the ACF regularisation method for remainder of this work.
lags and adaptive truncation, appear to have very similar biases we notice that adaptive truncation has less bias for short time series. Moreover, adaptive truncation is immune from arbitrary choice of lag cut-off. We therefore use adaptive truncation as the ACF regularisation method for remainder of this work.
The FPR analysis presented, in Figure 3.C, concern only the null case of uncorrelated time series. To summarise performance in the presence of correlation ρ > 0 we evaluate the sensitivity and specificity of each method, via ROC analysis, on simulated correlation matrices, discussed in section S3.5, where the time series are highly dependent and autocorrelated. Figure 5 illustrates the sensitivity, specificity and accuracy measures for each of the methods across three different sample sizes. For correlation matrices comprised of short and long sample sizes, the xDF outperforms all other existing methods to deliver the highest sensitivity while controlling false positive rates. For shorter time series, B35 and AR1MCPS are runner-ups to xDF. AUC analyses showed virtually no difference between the methods for FPR < 10% (Fig. S6).

Performance of testing ρ = 0 at level α = 0.05 on 2000 simulated correlation matrices (114 114, matching Yeo atlas) with 15% non-null edges (see Section S3.5). From top to bottom, specificity, sensitivity and accuracy (sum of detections at non-null edges and non-detections at null edges) are shown. Specificity (i.e. FPR control) is good for xDF, BH, Q47 and G-Q47, and sensitivity increases with time series length; accuracy is best for xDF, closely followed by BH and Q47.
3.3 Effect of Autocorrelation Correction on Functional Connectivity
Figure 6.A suggests that, as expected, the z-score of the functional connections either remained unchanged or has been reduced due to unbiased estimation of variance using xDF correction. For example, the functional connection between node 37 and 94 (i.e. both series are almost white; see Figure 1.E) has experienced almost no changes; zxDF(37, 94)=3.61 and zNaive(37, 94)=3.65, while functional connection between nodes 23 and 13 (i.e. both series are highly autocorrelated; see Figure 1.E) was reduced for 200%; zxDF(13, 25)=2.08, zNaive(13, 25)=6.02.

Impact of Naive, xDF and BH corrections on rsFC in one HCP subject parcellated with the Yeo atlas. Panel A plots rsFC z-scores of xDF-corrected connectivity vs. Naive, showing that the significance edges with Naive computation of ρ̂ variance is almost always inflated, but to varying degrees. Solid lines are the critical values corresponding to the cost-efficient (CE) density. Dashed lines illustrates the critical values of FDR-corrected p-values. Taking xDF as reference, edges that are incorrectly detected with Naive are coloured green (FDR but not CE) and blue (CE). The black point marks edge (37,94) and red point (13,25), discussed in body text. Panel B, plots rsFC z-scores of xDF-corrected connectivity vs. BH, same conventions as Panel A, showing deflated significance of z-scores computed with the BH method. The green point marks edge (103,104). Panel C, pp-plot of p-values of z-scores from xDF (green), BH (blue) and Naive (red) corrections. Dashed line is %5 Bonferroni threshold for 6,441 edges. Panel D, shows the differences in mean functional connectivity (mFC) of each correction method across statistical (FDR) and proportional (CE) thresholding. See Figure S9 for a similar plot for a different HCP Subject.
Naturally, such drastic changes in z-scores are also reflected in p-values of statistical inferences for each connection. Figure 6.C illustrate these changes (i.e. orange dots) between FDR-corrected p-values of Naive correction (left y-axis) and similar statistics of xDF correction (x-axis) where, broadly speaking, large number of the connections with significant p-values no longer meet the 5% α-level.
Since the changes in z-scores due to xDF are spatially heterogeneous, both statistical and proportional thresholding methods are dramatically affected. In statistical thresholding (ST), after xDF correction, the FDR critical values (shown as dotted lines on Figure 6.A) are slightly increases from 2.064 to 2.14. With the use of xDF, 13.66% of the edges change from being marked FDR-significant to being non-significant; i.e. over 10% of the edges would be incorrectly selected with the Naive method. Similarly, proportional thresholding (PT) is also affected since the cost-efficient densities (shown as solid lines on Figure 6.A, see section S4.4 for more details on cost-efficient densities) are decreased from 35% to 27.5%. These changes in cost-efficient density result in 16.61% false positive edges meaning that they were found to be significant merely due to the autocorrelation effect.
The same analysis on another HCP subject finds very similar changes in functional connectivity (Figure S9) as in ST and PT, the critical values and cost-efficiencies were reduced by more than 50% and 26%, respectively, due to xDF correction. This results in 16% FP edges in ST and 19% FP edges in PT.
While Figure 6.A shows that there is a profound effect of xDF relative to no correction (Naive), it is of interest to see how xDF compares to an existing methods that does attempt to correct for autocorrelation. For this we compare xDF z-scores to BH z-scores (Figure 6.A); recall that BH correction does not account for cross-correlation ΣXY and, due to confounding of cross-correlation and autocorrelation, can over-estimate ρ̂ standard errors. When the z-scores are low (corresponding to weak correlation) there is little difference between the approaches, while for stronger effects the difference between the two correction methods become clearer. For example, the z-score for the edge between node 103 and node 104 (green dot in Figure 6.B; ρ̂103,104 = 0.8) with BH and xDF correction is 6.93 and 15.30, respectively; suggesting that the confounding in autocorrelation estimates (see Appendix D) has reduced the functional strength of this edge for more than 50%. Similarly, we also follow changes in rsFC of another HCP subject for nodes 23 and 88 (green dot in Figure S9.B; ρ̂23,88 = 0.67) where the confounding effect produces a similar effect; zBH(23, 88) = 9.95, zxDF(23, 88)=14.26.
Functional connectivity changes reported so far were limited to study of single subjects. In Figure 6.D we show the impact of autocorrelation correction on mean value of rsFC z-scores for edges included in proportional (left) and FDR-based statistical (right) thresholding. Reflected what was found in simulation, autocorrelation correction reduces z-scores (reflecting Naive’s under estimation of  ), but the BH method has appreciably smaller z-scores (attributable to the confounding problem).
), but the BH method has appreciably smaller z-scores (attributable to the confounding problem).
3.4 Effect of Autocorrelation Correction on Graph Theoretical Measures
Graph measures are notorious for their sensitivity to changes in functional connectivity (van den Heuvel et al., 2017). Using subjects from 100 HCP unrelated package, we show how accounting for autocorrelation can influence basic graph theoretical measures such as centrality and efficiency. In this section the results are discussed for proportional and FDR-based statistical thresholding methods (see Section S5.8 results with unthresholded functional connectomes).
Figure 7.A uses Bland-Altman plots to show the changes in graph measures of rsFC obtained using proportional thresholding. The left column of Figure 7.A shows the impact of xDF relative to no correction: Most dramatic is the overall reduction in weighted degree, with the degree hubs having the highest rate of losing weighted degrees; these nodes are parts of the Default Mode Network (DMN; i.e. DefaultABC) and Saliency Ventral Attention Network (SVAN; i.e. SalVenAtt). Similarly, the local efficiency of more than 98% of nodes were changed after xDF correction. Parts of DMN and SVAN in addition to parts of the Visual network are among the nodes which have been affected the most. In contrast, betweenness centrality has experienced modest changes of only ≈5% in their values.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Overall changes in global and local graph theoretical measures with the 100 unrelated HCP package parcellated by Yeo atlas. Panel A, Bland Altman plots of xDF vs. Naive for weighted degree (top), betweenness (middle) and local efficiency (bottom) computed with a cost-efficient threshold. There is one point for each of 114 nodes, the particular measure averaged over subjects, and the nodes are colour coded according to their resting-state network assignment. Panel B Shows the same graph measures, but with statistical thresholding (corrected via FDR correction). Panel C shows the differences in weighted CE density (left) and Global efficiency (right), and Panel D illustrates the same results statistical FDR thresholding. There is a dramatic impact of correction method on all graph metrics considered.
The left column of Figure 7.B illustrates the changes in local graph measures of FDR-based statistical thresholded rsFC. Similar to ST results, the weighted degree of nodes suggests a significant reduction, with degree hubs (parts of DMN and SVAN) having the largest reduction. Local efficiency of almost every node (≈ 99%) of nodes were affected, especially highly efficient nodes appear to be mostly influenced by xDF correction with parts of the DMN, SVAN and Visual network among them. Although the pattern of changes in betweenness centrality suggest almost no relation to the betweenness value of nodes before the correction, betweenness centrality of ≈ 22% of nodes are yet affected.
The right columns of Figures 7.A and 7.B reflect how the BH estimator is a more conservative correction (due to correlation-autocorrelation confounding effect; see Appendix D). Table 1 summaries changes due to the confounding effect; Visual network, DMN and SVAN are among the nodes which are most impacted.
Percent of nodes that have significantly lower graph measures, for xDF vs. Naive and xDF vs.xDF (see Figure 7). This quantifies the dramatic impact of correction method on each graph metric.
We also evaluate changes in the global measures. Figure 7.C shows the changes in network density (left) where the density of networks with Naively corrected network were significantly reduced after xDF and BH correction however there is a slight, yet significant, difference between density of xDF-corrected and BH-corrected networks. Similarly, the global efficiency of networks (Figure 7.C) are significantly reduced after accounting for autocorrelation. Figure 7.C also suggests that overestimation of variance due to correlation-autocorrelation confounding may yet reduce the local efficiency.
In the global measures a similar pattern of changes is also found for CE-based proportional thresholded networks, as the density (Figure 7.D) of xDF-corrected networks are significantly reduced. However, in spite of changes in weighted degree, the confounding effect may not affect the network densities. Finally, global efficiency of xDF-corrected networks suggests a significant reduction. Despite a small difference, the confounding effect has also reduced the global efficiency.
We repeat this analysis for the Gordon and the Power atlas. For the Power atlas, Figure S12 suggests that the autocorrelation leaves a very similar pattern of changes for both PT and ST. The highest changes take place in nodes with highest degree and efficiency measures; nodes comprising Visual, Fronto-parietal and Default Mode Network (DMN). For Gordon atlas (Figure S11), we found very similar results where the changes suggest that nodes from DMN, Fronto-parietal and Sensory-Motor (i.e. SMHand) networks experienced the highest changes in their weighted degree and local efficiency. Interestingly, similar to the Yeo atlas, Betweenness centrality has shown the highest resilience towards these changes. Finally, Figure S13 shows similar results for subjects parcellated using ICA200.
4 Discussion
We develop an improved estimator of the variance of the Pearson’s correlation coefficient, xDF, that accounts for the impact of (possibly different) autocorrelation in each variable pair as well as the instantaneous and lagged cross-correlation. On the basis of extensive simulations under the null setting (ρ = 0) using simulated data and real data with intersubject scrambling, the xDF, BH and Q47 methods have good control of false positives, with xDF showing only slight FPR inflation on real null data (5.7%) and, on simulated data, only inflated with strong autocorrelation for short time series. Naive (no correction) have severe inflation of FPR and other methods based on simplistic AR(1) autocorrelation models (G-Q47, AR1MCPS) or common ACF for each pair of variables have poor FPR control. Simulations with realistic autocorrelation and non-null cross-correlation find that Naive severely under-estimates variance while BH and Q47 over-estimates variance, likely due to a confounding of auto‐ and cross-correlation in those corrections; xDF, in contrast, has negligible bias for long time series and for short time series has low bias for all but the strongest forms for autocorrelation.
On real data (non-null) rsFC we replicate the simulation findings, with Naive z-scores dramatically inflated relative to xDF, BH and Q47 z-scores smaller in magnitude. The differences between the methods, however, are node specific, reflecting how xDF adjusts for autocorrelation in each node pair. We recommend that all rsFC analyses that are based on z-scores, whether thresholded arbitrarily or or, say, use a mixture modelling approach (Bielczyk et al., 2018), use the xDF correction to obtain the most accurate inferences possible.
We show that graph analysis measures are dramatically impacted by use of xDF, relative to either Naive or BH corrections. Broadly speaking, accounting for autocorrelation results in lower z-scores and lower rsFC densities. These heterogeneous changes alter the topological features of the functional connectome, however the changes are not similar across resting-state networks; in the HCP data, we find nodal strengths and local efficiencies in parts of the sub-cortical regions experience lower changes compared to nodes from the frontoparietal and default mode networks, which are among the highly affected areas. The pattern of changes suggest that the nodal degree and efficiency hubs are among the most affected. In contrast, results for betweenness centrality suggest no systematic pattern with relatively lower changes.
We provide a comprehensive review of the literature on autocorrelation corrections for the variance of the sample correlation, usually cast as estimation of the effective degrees of freedom. In the neuroimaging community this is sometimes referenced as “Bartlett Correction Factor (BCF)”, though it has been only defined as “the integral across time of the square of the autocorrelation function” (Dijk et al., 2010; Fox et al., 2005), with citation to textbook (Jenkins and Watts, 1968), and used as a global correction over subjects and ROIs (Hale et al., 2016). We emphasize the importance of truncation or tapering of ACF’s and that such sums (not integrals) reflect the symmetry of ACFs, doubling of a sum counting only positive lags, as well as computing a correction for each node pair.
We note the strong influence of ROI size on the strength of autocorrelation, with, at one extreme, voxel-level data having the weakest correlation, increasing in strength as the size of the ROI increases. We also showed that, even for an ROI atlas with identically sized regions (i.e. Power atlas), autocorrelation can vary substantially over the brain depending on their location. These factors could become a significant source of bias in analyses of rsFC based on z-score if not otherwise corrected. We stress that these findings hold for both volumetric and surface-based analysis (Figure 2.C).
We do not wish, however, to say that all analyses of rsFC must be conducted in z-score units. Our derivation shows that Pearson’s correlation is approximately unbiased for the correlation ρ in the data (Appendix B). Hence researchers need to consider whether an r-units or z-units analysis is most appropriate for their question and then, if z-units, computing standard deviation with xDF is essential. We note that this assertion of the unbiasedness of correlation is at odds with other recent works (Arbabshirani et al., 2014; Davey et al., 2013). This is not inconsistent: Both of these works start their analysis with a pair of white noise variables with instantaneous correlation ρ and then assess the impact of inducing autocorrelation on those variables. In particular, they note that if different autocorrelation structures are induced then a bias in estimate of ρ can arise. Instead, we study the auto‐ and cross-correlation of the presented data (X, Y), without reference to an (unobserved) autocorrelation-free signal; in this setting Pearson’s correlation is (approximately) unbiased regardless of differential autocorrelation. We believe our empirical approach is more appropriate, as the BOLD signal is not white and hence inference on the correlation of presented (and not latent white) signals is of primary interest.
We note that other authors have proposed pre-whitening as a solution to improve inference on correlation (Bright et al., 2017), and when conducting system identification of the cross-correlation function ρXY,k it is recommended to first whiten each variable (Priestley, 1983). However, we still see the value of the no-whitening plus xDF correction approach. First, pre-whitening requires accurate estimate of ΣX and ΣY, and careful evaluation is required to see if the FPR is valid and the standard error unbiased over a range of settings. Second, pre-whitening changes the definition of ρ, from concerning the instantaneous correlation of the observed time series to that of the (unobserved, latent) white time series. And, finally, perhaps most important for moving window time-varying rsFC, pre-whitening mixes data from distant time points with neighbouring ones, challenging the interpretation of the individual time points as pertaining to a precise moment in time.
One immediate extension to the current work is to adapt the xDF estimator to partial correlations. Partial correlations have recently drawn substantial attention after they were shown to be effective in resting-state analysis (Marrelec et al., 2006; Smith et al., 2011). Further, recent studies have shown that accounting for autocorrelation is remarkably sensitive to sampling rates of the fMRI BOLD time series (Bollmann et al., 2018), therefore evaluating the proposed methods on different sampling rates would be useful. We have not attempted to investigate how the changes in z-scores we describe would affect the inter-group changes, but this would be a useful extension, as Váša et al. (2018) did for Schizophrenia in context of wavelet EDF. Finally, it is important to note that application of the xDF is not confined to rsFC of fMRI time series as it can be used in other modalities such as EEG and MEG as both modalities were shown to suffer from dependencies amongst their data-points.
5 Software Availability and Reproducibility
Analysis presented in this paper have been done in MATLAB 2015b and R 3.1.0. Graph theoretical analysis were done using Brain Connectivity Toolbox (accessed: 15/1/2017) (Rubinov and Sporns, 2010).
Variance of Pearson’s correlation, z-scores and p-values of such correlation matrices can be estimated via xDF.m available in https://gitub.com/asoroosh/xDF. The script is an standalone function and is executable using Statistics and Machine Learning Toolbox in MATLAB 2016 or later. The repository also contains six other variance estimators discussed in this work.
The autocorrelation (AC_fft.m) and cross-correlation (xC_fft.m) functions are estimated using Wiener–Khinchin theorem which involves discrete Fourier transformation of time series. We also used an algorithm proposed by Higham (1988) to find the nearest positive semi-definite covariance matrices for simulations described in Section S3.
Scripts and instructions to reproduce all the figures and results, are also available via http://www.github.com/asoroosh/xDF_Paper18. For details regarding the reproduciblity of the figures see section S6 of the supplementary materials.
A Results for Joint Distribution of Time Series X and Y
Here we provide basic results required for the next appendix, for moments of inner and cross produces of X and Y.
Theorem 1
(Covariance of Quadratic Form of Bivariate Gaussian Distribution). For fixed matrices A and B, if G is a random vector such that G ∼ N (0, Φ) then ℂ(G⊤AG, G⊤BG) = 2 tr(ΦAΦB)
Proof.
The result follows from application of the definition of covariance,
 and expectation of a quadratic form for Gaussian variates (Petersen et al., 2008),
and expectation of a quadratic form for Gaussian variates (Petersen et al., 2008),
 and expectation of quadratic forms,
and expectation of quadratic forms,  and
and  .
.
The Gaussian assumption can be relaxed, but then an additional term arises to account for departures from Gaussian kurtosis.
The inner products of X and Y can now be represented in terms of a quadratic form of
 for following maticies:
for following maticies:
 such that X⊤X = G⊤AXX G, Y⊤Y = G⊤AYY G, and X⊤Y = G⊤AXY G.
such that X⊤X = G⊤AXX G, Y⊤Y = G⊤AYY G, and X⊤Y = G⊤AXY G.
B xDF: Variance of Sample Correlation Coefficient for Arbitrary Dependence
For mean zero length-N random vectors X and X with (N × N) variance matrices ΣX and ΣY and cross-covariance ΣXY, we develop the variance of the sample correlation. Following Lehmann (1999a) and Hunter (2014), we derive an approximation for the sampling variance of Pearson’s correlation. Starting with the 3-dimensional sufficient statistic
 note that the function
note that the function  generates the correlation coefficient ρ̂. Then the first order Taylor’s series of ρ̂ = f (W) about
generates the correlation coefficient ρ̂. Then the first order Taylor’s series of ρ̂ = f (W) about  is
is
 so that
so that  and
and
 where the gradient of f (•) is
where the gradient of f (•) is
 evaluated at
evaluated at  ,
,
 and, by Theorem 1 in Appendix A,
and, by Theorem 1 in Appendix A,

Based on these expressions, evaluating the matrix product  gives the result in Eq. 1. While very similar, this derivation is not a standard delta method result as we do not have independent observations.
gives the result in Eq. 1. While very similar, this derivation is not a standard delta method result as we do not have independent observations.
C Trace of product of two Toeplitz Matrices
If ρXX,k and ρY Y,k are autocorrelation coefficients of time series X and Y on lag k, the diag(ΣX ΣY) can be re-written as

Considering that the autocorrelation function of time series is symmetric (i.e. the negative and the positive lags are identical), for X and Y we can simply obtain the trace of the ΣX ΣY as,

Similarly, the covariance matrix, ΣXY, can be written as a Toeplitz matrix of form

Knowing that the cross-covariance matrices are asymmetric but  , the trace of
, the trace of  and can be re-written as
and can be re-written as

Similarly, other terms of the Eq. 1 can be re-written as vector operations (see Eq. 2).
D Confounding of Serial and Cross-correlation Estimates
Majority of the EDF estimators discussed have the term tr(ΣX ΣY) which depends on the product of autocorrelation functions, ρXX,k ρY Y,k (see Appendix C). Some unexpected results such as poor variance estimation for the seemingly easy case of time series with no autocorrelation (see Section 3.2) were found to be caused by confounding between serial and cross correlation. Observe that for two white but dependent time series (ρXX,k = ρY Y,k = 0 for k > 0, but ρXY,0 ≠ 0), the product of the sample autocorrelation functions are

In this last expression note that in the first sum each summand has an expected value of ρ2, while the second sum has an expected value of zero. As a result, even when there is no (or very light) serial correlation, methods dependent on tr(ΣX ΣY) or ρXX,k ρY Y,k alone can be substantially biased by non-zero cross-correlation. This includes BH and all its variations listed in Pyper and Peterman (1998). Our xDF, on the other hand, is immune of the effect thanks to the cancelling cross-covariance terms in Eq. 2.
E Autocorrelation in Regions of Interests
We observed substantial differences in severity of autocorrelation in voxel-wise data as opposed to data derived from regions of interest (ROI). This section proposes a model that explains the effect.
Suppose that a ROI contains R voxels, and the data for time t and voxel i = 1, …, R can be be modelled as,
 where the St a common “signal” shared across all the voxels within the ROI (i.e. a ROI-specific global signal) and Vit are the voxel-specific component of data. Assuming that the two components are uncorrelated, the autocorrelation for the ROI is defined as,
where the St a common “signal” shared across all the voxels within the ROI (i.e. a ROI-specific global signal) and Vit are the voxel-specific component of data. Assuming that the two components are uncorrelated, the autocorrelation for the ROI is defined as,
 where
where  and
and  are the variances of V and S, respectively, and ρV V,k and ρSS,k are the autocorrelation coefficient of V and S at lag k, spectively. Now, for the ROI-averaged time series,
are the variances of V and S, respectively, and ρV V,k and ρSS,k are the autocorrelation coefficient of V and S at lag k, spectively. Now, for the ROI-averaged time series,  , the autocorrelation is:
, the autocorrelation is:

6 Acknowledgements
We thank Simon Schwab and Samuel Davenport at University of Oxford and Jeanette Mumford at University of Wisconsin for their useful input.
T.E.N. is supported by the Wellcome Trust (100309/Z/12/Z). S.M.S. is financially supported by the Well-come Trust Centre for Integrative Neuroimaging (203139/Z/16/Z) and the Wellcome Trust Strategic Award “Integrated Multimodal Brain Imaging for Neuroscience Research and Clinical Practice” (098369/Z/12/Z).
Data were provided in part by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.
Footnotes
↵1 While not the topic of this work, Arbabshirani et al. (2014) also discuss bias in ρ̂ due to autocorrelation. In contrast, our derivation (Appendix B) finds no such bias; see Section 4.
↵2 http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FSLNets; visited on 18 September 2015
References




