

Abstract
Automatic cerebral cortical surface reconstruction is a useful tool for cortical anatomy quantification, analysis and visualization. Recently, the Human Connectome Project and several studies have shown the advantages of using T1-weighted magnetic resonance (MR) images with sub-millimeter isotropic spatial resolution instead of the standard 1-millimeter isotropic resolution for improved accuracy of cortical surface positioning and thickness estimation. Nonetheless, sub-millimeter resolution images are noisy by nature and require averaging multiple repetitions to increase the signal-to-noise ratio for precisely delineating the cortical boundary. The prolonged acquisition time and potential motion artifacts pose significant barriers to the wide adoption of cortical surface reconstruction at sub-millimeter resolution for a broad range of neuroscientific and clinical applications. We address this challenge by evaluating the cortical surface reconstruction resulting from denoised single-repetition sub-millimeter T1-weighted images. We systematically characterized the effects of image denoising on empirical data acquired at 0.6 mm isotropic resolution using three classical denoising methods, including denoising convolutional neural network (DnCNN), block-matching and 4-dimensional filtering (BM4D) and adaptive optimized non-local means (AONLM). The denoised single-repetition images were found to be highly similar to 6-repetition averaged images, with a low whole-brain averaged mean absolute difference of ∼0.016, high whole-brain averaged peak signal-to-noise ratio of ∼33.5 dB and structural similarity index of 0.92, and minimal gray matter–white matter contrast loss (2% to 9%). The whole-brain mean absolute discrepancies in gray–white surface placement, gray–CSF surface placement and cortical thickness estimation were lower than 165 μm, 155 μm and 145 μm—sufficiently accurate for most applications. The denoising performance is equivalent to averaging ∼2.5 repetitions of the data in terms of image similarity, and 1.6–2.2 repetitions in terms of the cortical surface placement accuracy. The scan-rescan precision of the cortical surface positioning and thickness estimation was lower than 170 μm. Our unique dataset and systematic characterization support the use of denoising methods for improved cortical surface reconstruction sub-millimeter resolution.
Introduction
Cerebral cortical surface reconstruction enables the delineation of the inner and outer boundaries of the highly folded human cerebral cortex from anatomical magnetic resonance imaging (MRI) data using geometric models of the cortex. The input for cortical surface reconstruction is typically a T1-weighted structural MR image volume demonstrating high gray matter–white matter and gray matter–cerebrospinal fluid (CSF) contrast. The output of cortical surface reconstruction is a pair of two-dimensional surfaces represented as polyhedral (triangular) surface meshes, which represent the gray matter–white matter interface and the gray matter–CSF interface. Accurate cortical surface reconstruction can be performed automatically using several publicly available software packages1–9 and has been routinely used to quantify cortical morphology10–24, parcellate cortical areas25–27, and visualize and analyze anatomical28–32, microstructural33–36 and functional37–42 signals at various cortical depths and on the folded cortical manifold in a wide range of clinical and neuroscientific applications.
High-quality input T1-weighted MR images are essential for generating accurate cortical surfaces. T1-weighted MR images acquired with 1-millimeter isotropic spatial resolution have been long used for standard cortical surface reconstruction because the 1-millimeter voxels adequately sample the folded cortical ribbon in adult humans and because this acquisition provides an adequate trade-off between acquisition time, spatial resolution and signal-to-noise ratio (SNR). More recently, the Human Connectome Project (HCP) WU-Minn-Ox Consortium and several studies have shown the advantages of sub-millimeter isotropic spatial resolution for further improving the accuracy of the reconstructed cortical surfaces5,43–47. In these studies using sub-millimeter cortical surface reconstruction, the cortical surface positioning and thickness estimation in cortical regions with diminished gray–white contrast on T1-weighted MR images exhibit improved accuracy due to reduced partial volume effects on the sub-millimeter resolution images. This effect is especially noticeable in heavily myelinated cortical areas (e.g., primary motor, somatosensory, visual and auditory cortex), where the gray matter signal appears more similar in signal intensity to the white matter, as well as in insular cortex where the superficial white matter in the extreme capsule immediately beneath the insular cortex appears darker due to partial volume effects with the claustrum43,47. In general, T1-weighted MR images with 0.8-mm isotropic resolution (half of the minimum thickness of the cortex) or higher resolution are recommended by the HCP WU-Minn-Ox Consortium46. This new standard was adopted in the healthy adult HCP44,46 and the subsequent HCP Lifespan Development and Aging48–50. On the surface reconstruction side, several software packages, such as BrainVoyager51, CBS Tools5 and FreeSurfer43 have evolved to process anatomical MRI data at native sub-millimeter resolution.
A significant barrier to the wide adoption of the cortical surface reconstruction at sub-millimeter resolution is the longer scan time. Modern accelerated MRI techniques (e.g., compressed sensing52 and Wave-CAIPI53) can encode a larger number of k-space data samples at the sub-millimeter acquisition with less noise enhancement and artifact penalties compared to conventional parallel imaging approaches. Nevertheless, sub-millimeter resolution MR images remain limited in image quality by the intrinsically low SNR of smaller voxels. Adequate image quality using such data for cortical surface reconstruction requires averaging data from at least two repetitions of the acquisition, resulting in scan times that last ∼15 minutes (assuming a standard imaging acceleration factor of two) compared to ∼5 minutes scan time for a routine 1-mm isotropic resolution acquisition. In fact, the number of the repetitions required to provide the same SNR scales with the square of the voxel size ratio (e.g., ∼3.81 repetitions of 0.8-mm isotropic resolution data are needed to match the SNR of a single repetition of 1-mm isotropic resolution data, assuming all other parameters are held constant). Such long scans are uncomfortable and may result in increased vulnerability to motion artifacts and reduced scan throughput. Ultra-high field (e.g., 7-Tesla and 9.4-Tesla) MRI scanners and highly-parallelized phased-array radio frequency receive coil head arrays (i.e., 64 channels and above54) can significantly boost sensitivity and image SNR, but are currently still expensive and less accessible. Even at ultra-high fields, the SNR of a single repetition of sub-millimeter data may be not sufficient for accurately delineating the cortical surface in the temporal lobes because of signal dropout due to dielectric effects, and more repetitions are needed to enable high-quality whole-brain analysis.
Image denoising provides a feasible alternative strategy to obtain high-quality sub-millimeter anatomical MR images with adequate SNR from a single acquisition. Image denoising aims to recover a high-quality image from its noisy, degraded observation, which is a highly ill-posed inverse problem. Denoising algorithms often rely on prior knowledge as supplementary information to estimate high-quality images. One category of denoising methods incorporate these priors, such as sparseness52,55–58 and low rank59–64, during the formation of MR images. Another category of denoising methods are designed to be applied to the reconstructed images, with numerous algorithms proposed for processing 2-dimensional images (e.g., total variation denoising65, anisotropic diffusion filtering66,67, bilateral filtering68, non-local means (NLM) filtering69, block-matching and 3-dimentional filtering (BM3D)70 and K-SVD denoising71) and 3-dimensional medical imaging data72–76. As a stand-alone processing step, these methods only take in reconstructed images from the MRI scanner as inputs, without any need to intervene in the current MRI workflow, and can be directly incorporated into the existing surface reconstruction software packages.
Convolutional neural networks (CNNs) are advantageous for learning the underlying image priors and resolving the complex high-dimensional mapping from noisy images to noise-free images. Even a simple CNN for denoising (i.e., DnCNN77), comprised of stacked convolutional filters paired with rectified linear unit (ReLU) activation functions, achieves superior performance compared to the state-of-the-art BM3D denoising method. It is also relatively easy for CNNs to incorporate redundant information from other imaging modalities (e.g., using MR images to assist removal of noise in positron emission tomography (PET) images78) to boost denoising performance. Furthermore, denoising CNNs can be trained without use of noise-free target images in a self-supervised manner while still outperforming the state-of-the-art methods, which is especially useful when the noise-free target images are not available79,80. Impressively, CNN-based denoising methods can be executed extremely efficiently (in milliseconds or seconds) once trained. Thus far, CNN-based denoising has been widely applied for various biomedical imaging modalities ranging from fluorescence microscopy80,81, optical coherence tomography82 to x-ray imaging83, x-ray computed tomography84, PET78,85–88 and MRI84,89–95.
In the present study, we leverage multiple available denoising methods for improving cortical surface reconstruction at sub-millimeter resolution and characterize the improvement in the reconstructed surfaces offered by the different denoising approaches using empirical data. Specifically, we reconstruct cortical surfaces using single-repetition 0.6-mm isotropic resolution T1-weighted images denoised by classical denoising methods, including BM4D75, adaptive optimized NLM (AONLM)74 and DnCNN77. We systematically quantify the similarity and image contrast of denoised 0.6-mm isotropic T1-weighted images to the corresponding high-SNR 0.6-mm isotropic images obtained by averaging 6 repetitions of the data acquired within a single scan session and compare the results to those obtained from 2- to 5-repetition averaged data. We also quantify and compare the quality and smoothness of the reconstructed surfaces as well as the similarity of cortical surface positioning and cortical thickness estimation compared to the ground truth. Finally, we characterize the scan–rescan precision of the cortical surface positioning and cortical thickness estimation derived from the sub-millimeter resolution images denoised by different methods.
Materials and Methods
Data acquisitions
T1-weighted images with 0.6-mm isotropic resolution of nine healthy subjects (4 for training and validation of DnCNN parameters, 5 for evaluation) were acquired on a whole-body 3-Tesla scanner (MAGNETOM Trio Tim system, Siemens Healthcare, Erlangen, Germany) using the vendor-supplied 32-channel receive coil, body transmit coil, and standard body gradients at the Athinoula A. Martinos Center for Biomedical Imaging of the Massachusetts General Hospital (MGH) with Institutional Review Board approval and written informed consent of the volunteers. The data were acquired using a 3-dimensional multi-echo magnetization-prepared rapid gradient-echo (MEMPRAGE) sequence96. A slab-selective oblique-axial acquisition using a 13 ms FOCI adiabatic inversion pulse97 and acceleration factor of 2 in the partition (i.e., inner loop) direction was used to minimize the number of partition encoding steps and minimize T1 blurring during the inversion recovery98–100. Because the profile of the radiofrequency pulse for the slab excitation falls off at the slab boundaries, the signal level is lower toward the superior and inferior brain yielding lower SNR locally in the acquired images (Supplementary Fig. 1a). In order to avoid spatial blurring, partial Fourier imaging was not used in any encoding direction to help preserve the 0.6-mm isotropic resolution. The sequence parameters were: repetition time = 2,510 ms, echo times = 2.88/5.6 ms, inversion time = 1,200 ms, excitation flip angle = 7°, bandwidth = 420 Hz/pixel, echo spacing = 8.4 ms, 224 axial slices with 14.3% slice oversampling, matrix size = 400×304, slice thickness = 0.6 mm, field of view = 240 mm × 182 mm, generalized autocalibrating partial parallel acquisition (GRAPPA) factor = 2, acquisition time = 10.7 minutes per run × 6 separate repetitions.
Image processing
Image co-registration was performed six times for each subject. Each time, five image volumes were individually co-registered to the remaining one image volume (the reference image volume which was not resampled) using the robust registration method as implemented in the “mri_robust_template” function101 from the FreeSurfer software1–3 (version v6.0, https://surfer.nmr.mgh.harvard.edu), with “satit” and “fixtp” options and “inittp” set to the number of the reference image volume. The reference image volume was not re-sampled to avoid changing the noise characteristics. The co-registered image volumes were gradually added to the reference image volume to create averaged image volumes with progressively increasing SNR (n=2, 3, 4, 5, 6), which were compared to the de-noised single-repetition data in order to determine the efficiency factor, i.e., the number of image volumes for averaging that would be needed to obtain equivalent image and surface metric values compared to those obtained from denoised single-repetition data. Consequently, 6 pairs of image volumes, each pair consisting of a noisy image volume from the single-repetition data and a high-SNR image volume from the 6-repetition averaged data, were generated for each subject. A total of 24 pairs of image volumes (6 pairs/subject × 4 training subjects) were used as the training and validation data for optimizing the CNN parameters. For evaluation, 30 pairs of image volumes, each pair consisting of a noisy image volume from the single-repetition data (or 2- to 5-repetition averaged data) and a high-SNR image volume from 6-repetition averaged data, were used.
Spatially varying intensity bias maps were estimated using the image volumes from the single-repetition data with the unified segmentation routine7 implementation in the Statistical Parametric Mapping software (SPM, https://www.fil.ion.ucl.ac.uk/spm) with a full-width at half-maximum (FWHM) of 30 mm and a sampling distance of 2 mm102 (Supplementary Fig. 1b). The estimated bias maps were divided from images from the single-repetition and 2- to 6-repetition averaged data for correcting spatially varying intensity bias.
For improved DnCNN performance and evaluation of image and surface quality compared to those obtained from the 6-repetition averaged data, the images from the 6-repetition data were further non-linearly co-registered to the images from the single-repetition data, as well as from the 2- to 5-repetition averaged data, respectively. The non-linear co-registration slightly adjusted the image alignment locally, which accounted for the subtle non-linear shifts of tissue in the images due to factors such as subject bulk motion and the associated changes in distortion due to changing B0 inhomogeneity and gradient nonlinearity distortion during the acquisition of each repetition of data. The non-linear co-registration was performed using the “reg_f3d” function (default parameters, spline interpolation) from the NiftyReg software (https://cmiclab.cs.ucl.ac.uk/mmodat/niftyreg103,104.
The local mean values of the image intensity from the co-registered 6-repetition averaged data were also slightly scaled to match those of the corresponding single repetition as well as 2- to 5-repetition averaged data to remove the residual intensity bias for improved DnCNN performance and image and surface similarity evaluation. The local mean image intensity was computed using a 3-dimenstional Gaussian kernel with a standard deviation of 2 voxels (i.e., 1.2 mm).
Brain masks were created from the 6-repetition averaged image volumes by performing the FreeSurfer automatic reconstruction processing for the first five preprocessing steps (FreeSurfer’s “recon-all” function with the “-autorecon1” option). The binarized brain masks were dilated twice with holes filled using the “fslmaths” function from the FMRIB Software Library software105–107 (FSL, https://fsl.fmrib.ox.ac.uk).
BM4D denoising
T1-weighted image volumes from the single-repetition data were denoised using the BM4D denoising algorithm70,75. BM4D extends the widely known BM3D algorithm designed for 2-dimenstion image data to process 3-dimensional volumetric data. The BM4D method provides superior denoising performance by grouping similar 3-dimensional blocks across the entire volume (both local and non-local) into 4-dimensional data arrays to enhance the sparsity and then performing collaborative filtering. The BM4D denoising was performed assuming Rician noise with an unknown noise standard deviation and was set to estimate the noise standard deviation and perform collaborative Wiener filtering with “modified profile” option using the publicly available MATLAB-based software (https://www.cs.tut.fi/~foi/GCF-BM3D).
AONLM denoising
T1-weighted image volumes from the single-repetition data were also denoised using the AONLM algorithm73,74. In AONLM, the restored intensities of a small block are the weighted average of the intensities of all similar blocks within a predefined neighborhood. The 3-dimensional AONLM extends the 2-dimensional NLM filtering by using a block-wise implementation with adaptive smoothing strength based on automatically estimated spatially varying image noise level. The AONLM was performed assuming Rician noise with 3×3×3 block and 7×7×7 search volume73,74 using the publicly available MATLAB-based software (https://sites.google.com/site/pierrickcoupe/softwares/denoising-for-medical-imaging/mri-denoising/mri-denoising-software).
DnCNN denoising
T1-weighted image volumes from the single-repetition data were also denoised using DnCNN77 (Fig. 1), a pioneering and classical CNN for denoising. The 2-dimensional convolution used for processing 2-dimenstional images was extended to 3-dimensional for MRI to increase the data redundancy from an additional spatial dimension for improved denoising performance and smooth transition between 2-dimensional image slices. DnCNN maps the input image volume to the noise, i.e., the residual volume between the input and output image volume. Residual learning facilitates the DnCNN to only learn the high-frequency information, which boosts CNN performance, accelerates convergence and avoids the vanishing gradient problem77,108,109. DnCNN has a simple network architecture comprised of stacked convolutional filters paired with rectified linear unit (ReLU) activation functions and batch normalization functions. The n-layer DnCNN consists of a first layer of paired 3D convolution (k kernels of size d×d×d×1 voxels, stride of 1×1×1 voxel) and ReLU activation, n − 2 middle layers of 3D convolution (k kernels of size d×d×d×k voxels, stride of 1×1×1 voxel), batch normalization and ReLU activation, and a last 3D convolutional layer (one kernel of size d×d×d×k voxels, stride of 1×1×1 voxel). The output layer excludes ReLU activation so that the output would include both positive and negative values. Parameter value settings of n=20, k=64, d=3 were adopted following previous studies77 (∼2 million trainable parameters).

DnCNN is comprised of stacked 3-dimenstional convolutional filters with rectified linear unit (ReLU) activation functions and batch normalization functions (n=20, k=64, d=3). The input is a noisy anatomical (i.e., T1-weighted) image volume from one repetition of the sub-millimeter acquisition. The output is a high-signal-to-noise ratio T1-weighted image volume obtained by averaging data from multiple repetitions of the same sub-millimeter acquisition. DnCNN maps the input image volume to the residual volume between the input and output image volume (i.e., noise).
Our DnCNN network was implemented using the Keras application program interface (https://keras.io) with a Tensorflow backend (Google, Mountain View, California, https://www.tensorflow.org). Training and validation were performed on image blocks of 81×81×81 voxels (12 blocks per whole-brain volume) because of the limited GPU memory available. Sixty blocks from five random repetitions of data from each of the four training subjects (240 blocks in total) were used for training, while 12 blocks from the held-out repetition of data from each of 4 training subjects (48 blocks in total) were used for validation. The input and output image volumes were skull-stripped and image intensities were standardized by subtracting the mean intensity and then divided by the standard deviation of the image intensities of the brain voxels from the input noisy single-repetition image volumes.
All 3-dimensional convolutional kernels were randomly initialized with a “He” initialization110. Network parameters were optimized by minimizing the mean squared error within the brain (excluding the cerebellum which is irrelevant for cerebral cortical surface reconstruction and has significantly different texture compared to the cerebrum) using stochastic gradient descent111 with an Adam optimizer112 (default parameters except for the learning rate) using a V100 graphics processing unit (GPU, 16G memory) (NVidia, Santa Clara, California) for about ∼15 hours. The batch size was set to 1, the largest batch the GPU memory can accommodate. The learning rate was 0.0001 for the 20 epochs, after which the network approached convergence, and 0.00005 for another 10 epochs (∼0.5 hour per epoch).
The trained DnCNN was applied to the skull-stripped and standardized whole-brain image volumes from each repetition of the 5 evaluation subjects. The predicted image intensities were transformed to the original range by multiplying with the standard deviation of the image intensities and adding the mean intensity of the brain voxels from the input noisy image volumes.
Surface reconstruction
Cortical surface reconstruction at native 0.6-mm isotropic resolution was performed using the FreeSurfer sub-millimeter pipeline43 (version v6.0) (https://surfer.nmr.mgh.harvard.edu/fswiki/SubmillimeterRecon). The “recon-all” function was executed with the “hires” option with an expert file that specifies 100 iterations of surface inflation in the “mris_inflate” function.
Image similarity comparison
To quantify the similarity between the image volumes from the single-repetition and 2- to 5-repetition averaged data and the denoised image volumes compared to the high-SNR image volumes from the 6-repetition averaged data, the mean absolute difference (MAD), peak SNR (PSNR) and structural similarity index (SSIM)113 were computed using custom scripts written for the MATLAB software package (MathWorks, Natick, Massachusetts). PSNR, defined as 10log10(maximum possible value2/mean squared error), was computed using MATLAB’s “psnr” function, with larger value indicating lower mean squared error. SSIM is a perceptual metric for image similarity quantification ranging between 0 and 1 with larger value indicating higher similarity. SSIM was computed using MATLAB’s “ssim” function. For these calculations, the standardized image intensities, which virtually fell into the range [−3, 3], were normalized to the range of [0, 1] by adding 3 and dividing by 6. The group-level mean and standard deviation of the whole-brain averaged MAD, PSNR and SSIM (only within the brain mask) across 30 image volumes from the 5 evaluation subjects were computed to summarize the overall image similarity.
Image contrast comparison
The gray–white contrast is essential for successful cortical surface reconstruction. It was therefore computed from different types of images and compared. Specifically, the gray–white contrast was computed at the location of every vertex on the gray–white surface reconstructed from the 6-repetition averaged images as [white – gray]/[white + gray]⋅100%. The white matter intensity was sampled at 0.6 mm (i.e., the voxel size) below the gray–white surface. The gray matter intensity was sampled at 0.6 mm above the gray–white surface. The group-level mean and standard deviation of the whole-brain averaged vertex-wise gray–white contrast and variation of the vertex-wise gray–white contrast across 30 image volumes from the 5 evaluation subjects were computed to summarize the overall image contrast level.
Surface quality comparison
Percentage of defective vertices and surface smoothness were used for assessing the surface quality. The percentage of defective vertices was computed as the number of vertices identified as being part of topological defects in the initial reconstructed surface prior to topology correction114 (identified by FreeSurfer surface results files “lh.defect_labels” and “rh.defect_labels”) divided by the total number of vertices. The surface smoothness was defined as the median value of the whole-brain vertex-wise mean curvature, which was computed using FreeSurfer’s “mris_curvature” function. The group-level mean and standard deviation of the percentage of defective vertices, gray–white surface smoothness, gray–CSF surface smoothness across 30 image volumes from the 5 evaluation subjects were computed to summarize the overall surface quality.
Surface accuracy comparison
The FreeSurfer longitudinal pipeline101,115,116 (https://surfer.nmr.mgh.harvard.edu/fswiki/LongitudinalProcessing) was used to quantify the discrepancies of the gray–white and gray–CSF surface positioning and cortical thickness estimation from the single-repetition data, 2-to 5-repetition averaged data, and denoised single-repetition data compared to those from the 6-repetition averaged data. For any two image volumes for comparison, the longitudinal pipeline provides a vertex correspondence between the cortical surfaces reconstructed for each image volume, which enables the calculation of a per-vertex vertex-wise displacement for the two bounding surfaces of the cortical gray matter as well as a per-vertex difference of the cortical thickness estimates43,117. The group-level mean and standard deviation of the mean absolute gray–white and gray–CSF surface displacement and cortical thickness difference averaged across the whole brain as well as within 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer across 30 image volumes from the 5 evaluation subjects were computed to summarize the overall surface positioning accuracy.
Surface precision comparison
The FreeSurfer longitudinal pipeline was used to quantify the discrepancies of the gray–white and gray–CSF surface positioning and cortical thickness estimation from two consecutively acquired single-repetition data (5 comparisons in total, i.e., repetition 1 vs. repetition 2, repetition 2 vs. repetition 3 to repetition 5 vs. repetition 6) denoised by DnCNN, BM4D and AONLM as described in the previous section to quantify the scan-rescan reproducibility. The group-level mean and standard deviation of the mean absolute gray–white and gray–CSF surface displacement and cortical thickness difference averaged across the whole brain as well as within 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer across 25 image volumes from the 5 evaluation subjects were computed to summarize the overall surface positioning precision.
Statistical comparison
The non-parametric Wilcoxon signed-rank test was performed for two related samples to evaluate differences between metrics of interest (i.e., the whole-brain averaged MAD, PSNR, SSIM, vertex-wise gray–white contrast, variability of the vertex-wise gray–white contrast, gray–white surface displacement, gray–CSF surface displacement and cortical thickness difference) from different types of image volume (e.g., DnCNN-denoised data vs. BM4D-denoised data, and DnCNN-denoised data vs. 6-repetition averaged data) across 30 image volumes from the 5 evaluation subjects (N=30) for the accuracy metrics and across 25 images volume from the 5 evaluation subjects (N=25) for the precision metrics.
Results
Figure 2 shows that the T1-weighted images (Fig. 2, rows a, b, columns iii–v) denoised using DnCNN, BM4D and AONLM were better able to delineate fine anatomical structures compared to the single-repetition data (Fig. 2, rows a, b, columns ii) and were visually more comparable to the T1-weighted image generated from the 6-repetetion averaged data (Fig. 2, rows a, b, column i). The textural details were more clearly displayed with sharper gray–white and gray–CSF boundaries in the denoised images, especially in the DnCNN-denoised images, compared to those from the single-repetition data (Fig. 2, row b, arrow heads). The differences between the denoised images and 6-repetition averaged image exhibited negligible levels of anatomical structure and were substantially lower compared to those from the single-repetition images (Fig. 2, row c), with lower whole-brain averaged MAD (0.014, 0.015, 0.015 for DnCNN, BM4D and AONLM vs. 0.03) and higher PSNR (34.7 dB, 34 dB and 34 dB for DnCNN, BM4D and AONLM vs. 28.18 dB). The SSIM maps demonstrate that the denoised images were also perceptually similar to the 6-repetition averaged image (Fig. 2, row d), with higher whole-brain averaged SSIM (0.94, 0.93, 0.93 for DnCNN, BM4D and AONLM vs. 0.81). Overall, DnCNN had slightly better denoising performance than BM4D and AONLM, which generated images of very similar quality to one another.

A representative axial image slice from the 6-repetition averaged data (a, i), the single-repetition data (a, ii), and the single-repetition data denoised by DnCNN (a, iii), BM4D (a, iv) and AONLM (a, v), along with magnified views of basal ganglia (row b). The arrowheads highlight the boundary of gray matter and white matter (green), the claustrum (blue), and the blood vessel in the internal capsule (magenta). The difference maps (row c) and the structural similarity index (SSIM) maps (row d) depict the similarity between the images from the single-repetition data and the denoised data compared to the images from the 6-repetition averaged data. SSIM scores range between 0 and 1, with larger values indicating higher similarity. The whole-brain mean absolute difference (MAD), mean peak signal-to-noise ratio (PSNR) and mean SSIM are used to quantify the image similarity.
The noise estimated by the three methods (i.e., the residual maps between the denoised images and the acquired single-repetition image) did not contain any noticeable anatomical structure or biases reflecting the underlying anatomy (Supplementary Fig. 2, rows b, columns iii-v) and were visually similar to the residual map from the 6-repetition averaged data (Supplementary Fig. 2, rows b, column ii). DnCNN estimated slightly lower noise levels in the center of the brain compared to BM4D and AONLM.
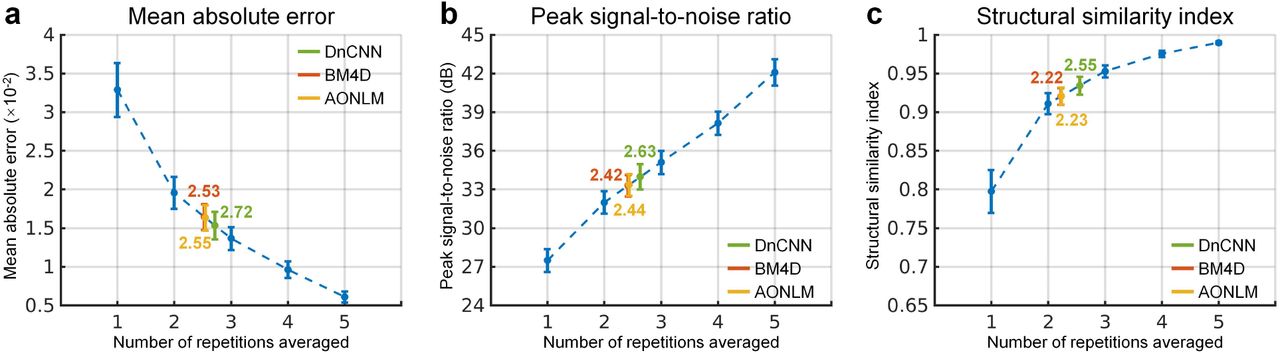
The similarity between images from the single-repetition data and the denoised single-repetition data compared to the 6-repetition averaged data was quantified at the group level and compared to those from the 2- to 5-repetition averaged data in Figure 3. The group-level means (± the group-level standard deviation) of the whole-brain averaged MAD, PSNR and SSIM of the denoised images were approximately two times lower (0.0153 ± 0.0018, 0.0165 ± 0.0017, 0.0163 ± 0.0017 for DnCNN, BM4D and AONLM vs. 0.0329 ± 0.0035), ∼6 dB higher (34.0 ± 0.98 dB, 33.3 ± 0.83 dB, 33.4 ± 0.85 dB for DnCNN, BM4D and AONLM vs. 27.5 ± 0.89 dB) and approximately 0.12 higher (0.93 ± 0.012, 0.92 ± 0.011, 0.92 ± 0.011 for DnCNN, BM4D and AONLM vs. 0.80 ± 0.028), respectively, compared to the single-repetition images. The image similarity levels of the denoised images compared to the 6-repetition averaged images were equivalent to those derived from what would be expected from averaging 2.5 images (2.72, 2.53, 2.55 in terms of MAD, 2.63, 2.42, 2.44 in terms of PSNR, and 2.55, 2.22, 2.23 in terms of SSIM for DnCNN, BM4D and AONLM).

The blue dots and error bars represent the group mean and standard deviation of the mean absolute difference (MAD) (a), peak signal-to-noise ratio (PSNR) (b) and structural similarity index (SSIM) (c) of the images from the single-repetition data and 2- to 5-repetition averaged data compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects. The green, red and yellow dots and error bars represent the group mean and standard deviation of the MAD, PSNR and SSIM of the images from the single-repetition data denoised by DnCNN (green), BM4D (red) and AONLM (yellow) compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects. The red dots and error bars for BM4D are virtually covered by the yellow dots and error bars for AONLM. The numbers above and below the dashed lines that link two neighboring blue dots indicate the number of image volumes that would be needed to obtain equivalent similarity metrics to those obtained from images from single-repetition data denoised by different methods. All comparisons of results from different denoising methods and numbers of repetitions for averaging are statistically significant (p<0.05).
The vertex-wise gray–white contrast maps depict the spatial variation of the gray–white contrast across cortical regions (Fig. 4, averaged maps across 30 image volumes from the 5 evaluation subjects available in Supplementary Fig. 3). Overall, the gray–white contrast was consistently lower in heavily myelinated regions near the central sulcus, calcarine sulcus, paracentral gyrus, Heschl’s gyrus, posterior cingulate gyrus, isthmus of the cingulate gyrus with increased gray matter image intensity on T1-weighted images, and in the insula with decreased white matter image intensity on the T1-weighted images arising from the partial volume effects with the claustrum47. These regions are more prone to noise during the cortical surface reconstruction process.

Left-hemispheric vertex-wise contrast between the gray matter and white matter image intensity (defined as [white − gray]/[white + gray]⋅100%) from the 6-repetition averaged data (column i), single-repetition data (column ii), single-repetition data denoised by DnCNN (column iii), BM4D (column iv) and AONLM (column v) from a representative subject, displayed on inflated surface representations. Different cortical regions from the FreeSurfer cortical parcellation (i.e., aparc.annot) are depicted as colored outlines
Gray–white contrast is critical for accurate cortical surface reconstruction, which should be preserved as much as possible during the noise removal process. The gray–white contrast map from the single-repetition data (Fig. 4, column ii) displayed similar gray–white contrast level compared to the map from the 6-repetition averaged data (Fig. 4, column i), but was more spatially variable. The gray–white contrast maps from the denoised data (Fig. 4, columns iii–v) were smoother and less spatially variable, appearing more similar to the map from the 6-repetition averaged data (Fig. 4, column i). The gray–white contrast level in the map from DnCNN (Fig. 4, column iii) was slightly higher than those from BM4D (Fig. 4, column iv) and AONLM (Fig. 4, column v), and visibly more similar to that from the 6-repetition averaged data (Fig. 4, column i).
The group-level means (± the group-level standard deviation) of the spatial mean and spatial variability of the vertex-wise gray–white contrast across the whole brain were quantified to compare the capability of different denoising methods in preserving gray–white contrast (Fig. 5). The whole-brain averaged vertex-wise gray–white contrast stayed almost the same and decreased only marginally when averaging more repetitions of data (Fig. 5a, blue curve), which was consistent with visual inspection (Fig. 4, columns i, ii). The whole-brain averaged vertex-wise gray–white contrast from DnCNN was slightly higher than that from BM4D and AONLM (13.03 ± 0.71 vs. 12.20 ± 0.73 and 12.10 ± 0.76 for BM4D and AONLM) and was only slightly lower than that from the 6-repetition averaged data (13.03 ± 0.71 vs. 13.30 ± 0.59).

The blue dots and error bars represent the group mean and standard deviation of the spatial mean of the vertex-wise percent gray–white contrast (defined as [white - gray]/[white + gray]⋅100%) across the whole-brain cortical surface (a) and the spatial variability (calculated as standard deviation) of the vertex-wise percent gray–white contrast across the whole-brain cortical surface (b) of the images from the single-repetition data and 2- to 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects. The green, red and yellow dots and error bars represent the group mean and standard deviation of the spatial mean value and spatial variability of the percent gray-white contrast of the images from the single-repetition data denoised by DnCNN (green), BM4D (red) and AONLM (yellow) across 30 image volumes from the 5 evaluation subjects. All comparisons of results from different denoising methods and numbers of repetitions for averaging are statistically significant (p<0.05), except for between the 5- and 6-repetition averaged data for the spatial mean value of percent gray–white contrast (a), and between the 6-repetition averaged data and the single-repetition data denoised by DnCNN for the spatial variability of the percent gray-white contrast (b) (denoted with abbreviation “ns”).
The spatial variability of the vertex-wise gray–white contrast continued to decrease when more repetitions of the data were averaged (Fig. 5b, blue curve). This finding was also visually reflected by smoother gray–white contrast maps (Fig. 4, columns i, ii). The spatial variability of the vertex-wise gray–white contrast in the DnCNN-denoised data was nearly the same as that in the 6-repetition averaged data (4.69 ± 0.10 vs. 4.70 ± 0.13, comparison not significant). The spatial variability in the BM4D- and AONLM-denoised data (4.35 ± 0.10 vs. 4.42 ± 0.10) was further reduced than in the DnCNN-denoised data and 6-repetition averaged data, potentially due to stronger unwanted spatial smoothing effects that reduce tissue contrast.
The effects of data averaging and denoising on the reconstructed cortical surfaces are shown in Figure 6. The cortical surfaces from the single-repetition data (Fig. 6, column ii) resembled the overall cortical geometry represented by the surfaces from the 6-repetition averaged data (Fig. 6, column i), but were not smooth. The bumpy appearance was more obviously displayed in the superior and inferior brain (Fig. 6, column ii, arrow heads), where the SNR was further reduced because of the lower signal level resulting from the non-uniform slab excitation. The cortical surfaces from the 6-repetition averaged data and the denoised data were much smoother and more visually similar (Fig. 6, column i, iii–v). The gray–CSF surfaces were in general smoother compared to the gray–white surfaces.

Gray–white interface surfaces (a–d) and gray–CSF interface surfaces (e–h), along with magnified views near the Calcarine sulcus (rows d, h), reconstructed from the 6-repetition averaged data (column i), the single-repetition data (column ii), and the single-repetition data denoised by DnCNN (column iii), BM4D (column iv) and AONLM (column v) from the left hemisphere of a representative subject. The arrow heads highlight locations toward the superior and inferior brain with reduced signal-to-noise ratio in the acquired data because of the non-uniform slab excitation profile and consequently less smooth cortical surfaces.
The mean curvature can be used to characterize the local smoothness of cortical surfaces quantitatively (Fig. 7, averaged maps across 30 image volumes from the 5 evaluation subjects available in Supplementary Fig. 4)—the mean curvature map of a smooth surface will exhibit low levels of spatial variability. For the single-repetition data, the mean curvature map of the gray–white surface was highly spatially variable near the central sulcus, calcarine sulcus, paracentral gyrus, cingulate gyrus and insula, where the gray–white contrast was lower (Fig. 4) and the image noise had a higher impact on the reconstructed cortical surfaces. The mean curvature maps from the 6-repetition averaged data and the denoised data were much less spatially variable, but were still slightly variable near the superior portion of the central sulcus because of the simultaneous reduction in gray–white contrast and lower signal levels near the edge of the excited slab.

Left-hemispheric vertex-wise mean curvature of the reconstructed gray–white surfaces (a–c) and gray–CSF surfaces (d–f) from the 6-repetition averaged data (column i), single-repetition data (column ii), single-repetition data denoised by DnCNN (column iii), BM4D (column iv) and AONLM (column v) from a representative subject, displayed on inflated surface representations. Different cortical regions from the FreeSurfer cortical parcellation (i.e., aparc.annot) are depicted as colored outlines
Quantitatively, the median of the whole-brain mean curvature decreased as the number of the averaged repetition increased (Fig. 8a, b, blue curves), indicating increased overall surface smoothness. The cortical surfaces from the denoised data were even smoother than those from the 6-repetition data (0.17 ± 0.0051, 0.16 ± 0.0042 and 0.16 ± 0.0052 for DnCNN, BM4D and AONLM vs. 0.18 ± 0.0061 for 6-repetition averaged data for gray–white surface; 0.19 ± 0.0039, 0.18 ± 0.0039 and 0.18 ± 0.0035 for DnCNN, BM4D and AONLM vs. 0.20 ± 0.0038 for 6-repetition averaged data for gray–white surface), potentially due to stronger unwanted spatial smoothing effects. The surface smoothness from DnCNN was more similar to the surface smoothness from the 6-repetition averaged data compared to those from BM4D and AONLM. The percentage of vertices identified as being part of topological defects in the initial surfaces reconstructed from the input data prior to automatic topological correction decreased as the number of the averaged repetitions increased (Fig. 8c, blue curve), indicating improved image quality due to data averaging. The percentage of the defective vertices (typically 0.8 to 1 million vertices in total for a subject for 0.6-mm isotropic data) was even lower in the denoised data than in the 6-repetition averaged data (0.014% ± 0.0028%, 0.01% ± 0.0015% and 0.01% ± 0.0017% for DnCNN, BM4D and AONLM vs. 0.023% ± 0.0056% for 6-repetition averaged data).

The blue dots and error bars represent the group mean and standard deviation of the smoothness of the gray–white (a) and gray–CSF surface (b) (defined as the median of the vertex-wise mean curvature across the cortical surface), and the percentage of the vertices identified as being part of topological defects in the initial surface (c) from the single-repetition data and 2- to 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects. The green, red and yellow dots and error bars represent the group mean and standard deviation of the gray–white and gray–CSF surface smoothness and percentage of the defective vertices from the single-repetition data denoised by DnCNN (green), BM4D (red) and AONLM (yellow) across 30 image volumes from the 5 evaluation subjects. All comparisons of results from different denoising methods and numbers of repetitions for averaging are statistically significant (p<0.05), except for between the BM4D- and AONLM-denoised data for the percentage of the defective vertices (c) (denoted with abbreviation “ns”).
To demonstrate the effects of data averaging and denoising on the accuracy of surface positioning, cross-sections of the cortical surfaces were presented in enlarged views near the central sulcus and the calcarine sulcus (Fig. 9), chosen because they are regions with reduced gray–white contrast. The cortical surfaces reconstructed from the denoised data were similar to those reconstructed from 6-repeition averaged data and were markedly improved compared to the surface placement derived from the single-repetition data (Fig. 9, arrow heads), especially the gray–white surfaces. The discrepancy in positioning of the gray–CSF surface across the different denoising techniques was overall smaller than that of the gray–white surface.

Enlarged views of sagittal image slices from the 6-repetition averaged data (column i), the single-repetition data (column ii), and the single-repetition data denoised by DnCNN (column iii), BM4D (column iv) and AONLM (column v) near the central sulcus (rows a, b) and the calcarine sulcus (rows c, d) from the left hemisphere of a representative subject. Cross-sections of the gray–white (rows a, c) and gray–CSF surfaces (rows b, d) are visualized as colored contours and overlaid on top of the images used for reconstructing the respective surfaces. The surface cross-sections from the 6-repetition averaged data are displayed as red thin contours as references along with the surface cross-sections from the single-repetition data and the denoised data (columns ii-v). The arrow heads highlight locations where denoising provides clear improvement in the cortical surface positioning estimates.
The denoised images exhibited substantially lower discrepancy in the surface positioning relative to surfaces reconstructed from the 6-repetition averaged images compared to the discrepancy seen from the single-repetition images in all cortical parcels on the single-subject level (Fig. 10, columns i–iii) and group level (Fig. 10, columns iv–vi). In the denoised results, the discrepancy was most prominent near the central sulcus, calcarine sulcus, Heschl’s gyrus and cingulate gyrus and insula for the gray–white surfaces (Fig. 10, rows a–d, column iv–vi), near the Heschl’s gyrus and insula for the gray–CSF surfaces (Fig. 10, rows e–h, column iv–vi), and near the Heschl’s gyrus and insula for the cortical thickness estimation (Fig. 10, rows i–l, column iv–vi). Estimates from the single-repetition data and denoised data near the temporal pole and orbitofrontal cortex had larger discrepancies presumably because of the large and varying geometric distortions near air-tissue interfaces in each repetition of the data, which could not be accurately aligned for averaging the 6 repetitions of the data and therefore induced increased misalignment between each single-repetition data and the 6-repetition averaged data.

Left-hemispheric vertex-wise displacement/difference of the gray–white surfaces (rows a–d) and gray–CSF surfaces (rows e–h) and cortical thickness estimates (rows i–l) from the single-repetition data (rows a, e, i) and the single-repetition data denoised by DnCNN (rows b, f, j), BM4D (rows c, g, k) and AONLM (rows d, h, l) compared to the surfaces estimated from the 6-repetition averaged data of a representative subject (column i–iii) and the absolute average across 30 image volumes from the 5 evaluation subjects (rows iv–vi), displayed on inflated surface representations. Different cortical regions from the FreeSurfer cortical parcellation (i.e., aparc.annot) are depicted as colored outlines.
The group mean and standard deviation of the mean absolute displacement/difference of the gray–white surface, gray–CSF surface and cortical thickness was quantified for the whole brain (Fig. 11) and each cortical region (Supplementary Tables 1–3). The accuracy of surface positioning and cortical thickness estimation, especially the gray–white surface positioning was increased in the denoised data. The group-level means (± the group-level standard deviation) of the whole-brain averaged displacement of the gray–white surface in the denoised data were about two thirds of those from single-repetition images (0.15 ± 0.02 mm, 0.16 ± 0.025 mm, 0.17 ± 0.025 mm for DnCNN, BM4D and AONLM vs. 0.25 ± 0.04 mm), which were equivalent to those derived from ∼two-repetition averaged images (2.24, 1.92, 1.92 for DnCNN, BM4D and AONLM, respectively). The group-level means (± the group-level standard deviation) of the whole-brain averaged displacement/difference of the gray–CSF surface and cortical thickness in the denoised data were about four fifths of those from single-repetition images (0.13 ± 0.023 mm, 0.15 ± 0.032 mm, 0.14 ± 0.026 mm for DnCNN, BM4D and AONLM vs. 0.19 ± 0.033 mm for gray–white surface positioning; 0.13 ± 0.02 mm, 0.14 ± 0.027 mm, 0.14 ± 0.023 mm for DnCNN, BM4D and AONLM vs. 0.18 ± 0.027 mm for cortical thickness estimation), which were equivalent to those derived from images by averaging 1.5 to 1.9 repetitions of data (1.91, 1.63, 1.78 for DnCNN, BM4D and AONLM for gray–white surface; 1.85, 1.55, 1.64 for DnCNN, BM4D and AONLM for cortical thickness estimation). The improvement for the gray–white surface positioning was slightly larger than for the gray–CSF surface positioning and cortical thickness estimation.

The blue dots and error bars represent the group mean and standard deviation of the whole-brain averaged absolute displacement/difference of the gray–white surface (a), gray–CSF surface (b) and cortical thickness (c) estimated from the images from the single-repetition data and 2- to 5-repetition averaged data compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects. The green, red and yellow dots and error bars represent the group mean and standard deviation of the whole-brain averaged absolute displacement/difference for the images from the single-repetition data denoised by DnCNN (green), BM4D (red) and AONLM (yellow) compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects. The red dots and error bars for BM4D are covered by the yellow dots and error bars for AONLM for the gray–white surface displacement (a). The numbers above and below the dashed lines that link two neighboring blue dots indicate the number of image volumes that would be needed to obtain equivalent similarity metrics to those obtained from images from single-repetition data denoised by different methods. All comparisons of results from different denoising methods and numbers of repetitions for averaging are statistically significant (p<0.05), except for between the BM4D- and AONLM-denoised data for the gray–white surface displacement (a) (denoted with abbreviation “ns”).
The scan-rescan precision of the cortical surface position and thickness estimation using the denoised data was quantified for the whole brain and each cortical region (Fig. 12, Supplementary Table 4). The reproducibility was in general lower near the temporal pole and orbitofrontal cortex presumably because of the elevated image distortions in these regions. The reproducibility was lower near the central sulcus, calcarine sulcus, Heschl’s gyrus and insula for the gray–white surfaces (Fig. 12, rows a–c), near the insula for the gray–CSF surfaces (Fig. 12, rows d–f) and cortical thickness estimation (Fig. 12, rows g–i), regions where accurate surface reconstruction is challenging.

Left-hemispheric vertex-wise displacement/difference of the gray–white surfaces (rows a–c) and gray–CSF surfaces (rows d–f) and cortical thickness estimates (rows g–i) from two consecutively acquired single-repetition data denoised by DnCNN (rows a, d, g), BM4D (rows b, e, h) and AONLM (rows c, f, i) of a representative subject (column i–iii) and the absolute average across 25 image volumes from the 5 evaluation subjects (rows iv–vi), displayed on inflated surface representations. Different cortical regions from the FreeSurfer cortical parcellation (i.e., aparc.annot) are depicted as colored outlines.
The cortical surface positioning and thickness estimation derived from DnCNN-denoised results were slightly more reproducible than those from BM4D and AONLM. The group mean and standard deviation of the whole-brain averaged absolute displacement/difference between the surface reconstruction results derived from two consecutively acquired single-repetition data denoised by DnCNN, BM4D and AONLM were 0.16 ± 0.034 mm, 0.17 ± 0.034 mm, 0.17 ± 0.035 mm for the gray–white surface, 0.16 ± 0.043 mm, 0.17 ± 0.045 mm, 0.17 ± 0.043 mm for the gray–CSF surface, and 0.15 ± 0.032 mm, 0.16 ± 0.034 mm, 0.16 ± 0.034 mm for the cortical thickness.
Discussion
In this study, we demonstrate improved in vivo human cerebral cortical surface reconstruction at sub-millimeter isotropic resolution using denoised T1-weighted images. We show that three well-known classical denoising methods, including DnCNN, BM4D and AONLM, effectively remove the noise in the empirical T1-weighted data acquired at 0.6 mm isotropic resolution (∼10 minutes scan) and generate high-SNR T1-weighted images similar to those obtained by averaging 6 repetitions (∼ 1 hour scan) of the data with only minimal loss of gray–white image intensity contrast (2% to 9%). The superior quality of the denoised images is reflected by a low whole-brain averaged MAD of ∼0.016, high whole-brain averaged PSNR of ∼33.5 dB and SSIM of 0.92, which is equivalent to those of T1-weighted images obtained by averaging ∼2.5 repetitions of the data, saving ∼15 minutes scan time. Due to the significantly reduced noise, the reconstructed cortical surfaces are smoother with similar positioning compared to those from the 6-repetition averaged data. The whole-brain mean absolute difference in the gray–white surface placement, gray–CSF surface placement and cortical thickness estimation is lower than 160 μm, which is equivalent to those of T1-weighted images obtained by averaging ∼1.55 to ∼2.24 repetitions of the data, saving ∼5 to ∼12 minutes scan time, and on the same order as the test-retest precision of the FreeSurfer reconstruction (0.1 mm to 0.2 mm)117–119.
Our study systematically characterized the effects of denoising on cortical surface reconstruction using empirical data. Three well-known classical denoising methods were evaluated in our study using this characterization framework, similar to what we have applied previously to characterize anatomical image quality in terms of cortical reconstruction precision and accuracy43,47,117,119, which can be applied to evaluate other image-based and k-space-based denoising methods and more sophisticated denoising CNNs. We systematically quantified and compared not only the image similarity compared to the ground truth as in most denoising studies, but also the gray–white tissue contrast that is critical for accurate cortical surface reconstruction, surface smoothness and surface placement accuracy from the denoised data. Because our ground-truth data were obtained by data averaging (6 repetitions, ∼1 hour scan), we were able to evaluate the image and surface metrics from the denoised data relatively to those from 2- to 5-repetition averaged data and determine the efficiency factor, i.e., the number of image volumes for averaging that would be needed to obtain equivalent image and surface metric values compared to those obtained from denoised single-repetition images. This unique metric concisely and intuitively summarizes the denoising performance of different methods compared to data averaging, the most common practice to increase the SNR. Our results show that the denoised single-repetition data are equivalent to ∼2.5-repetition averaged data in terms of image similarity quantified by MAD, PSNR and SSIM (Fig. 1), while being equivalent to 1.55 to 2.24-repetition averaged data in terms of cortical surface positioning and thickness estimation accuracy (Fig. 11). The discrepancy between the efficiency factors calculated using image and surface metrics suggests that the commonly used image similarity metrics alone cannot faithfully reflect the cortical surface reconstruction quality and the objective functions used during the denoising process, e.g., the mean squared error, can be further optimized for cortical surface reconstruction applications.
In addition to improving cortical surface reconstruction at sub-millimeter resolution, denoising methods can be also useful for improving cortical surface reconstruction at standard 1-mm isotropic resolution. The ∼5 minutes scan time of a standard 1-mm isotropic resolution acquisition (assuming a parallel imaging acceleration factor of two) is still considered long for elderly subjects, children and some patient populations prone to motion and/or discomfort. In order to save scan time, T1-weighted images at resolutions lower than 1-mm isotropic (e.g., 3 to 5-mm axial slices in a 2-dimensional acquisition, ∼1.5 mm resolution along the phase-encoding direction in a 3-dimensional acquisition) are also routinely acquired in clinical practice and large-scale neuroimaging studies such as the Parkinson Progression Marker Initiative120, which preclude accurate cortical surface reconstruction and quantitative analysis of cortical morphology at 1-mm isotropic resolution. In these applications, higher parallel imaging factors (e.g., 3 or 4) can be adopted for further shortening the 1-mm isotropic acquisition duration, coupled with denoising methods for accurate cortical surface reconstruction from the noisier images. More advanced fast imaging technologies such as Wave-CAIPI53 can achieve even higher acceleration factors (e.g., 9) with minimal noise and artifact penalties and have been shown to reduce the scan time of a 1-mm isotropic acquisition to 1.15 minutes with estimated regional brain tissue volumes comparable to those from a standard 5.2 minutes scan121. Denoising methods are expected to further improve the image quality of highly accelerated 1-mm isotropic data, acquired even within a minute, for accurately delineating the cortical surface119.
The pros and cons of different denoising methods need to be weighed for different applications. The three denoising methods evaluated here, DnCNN, BM4D and AONLM, are three well-known classical denoising methods with widely accepted superior denoising performance and are often used as references against which newly developed denoising methods are compared. Our results show that CNN-based denoising method DnCNN generates denoised images and consequently reconstructed cortical surfaces that are more similar to the ground truth than BM4D and AONLM, which is achieved by effectively exploiting the data redundancy in local and non-local spatial locations as well as across numerous subjects. However, the data-driven nature of DnCNN requires additional training data (e.g., data from 4 subjects in our study) for optimizing parameters or fine-tuning the parameters of an existing DnCNN pre-trained on other datasets for improved generalization across hardware systems, pulse sequences and sequences parameters. It has been shown that results obtained by directly applying CNNs pre-trained on a different dataset are reasonably accurate but are slightly worse compared to those obtained from fine-tuned CNNs47,122,123. On the other hand, BM4D and AONLM only require a single input noisy image volume, which are more convenient in practice and especially useful when the training data for DnCNN are not available (e.g., denoising legacy data). In terms of computational efficiency, DnCNN, once trained, can be executed in milliseconds or seconds, much faster than BM4D and AONLM with run times that last anywhere from minutes to an hour depending on the computing platform. The extremely fast DnCNN could facilitate review of denoised images in near real-time on the host computer of the MRI console.
The specific DnCNN network we chose for our study is a pioneering, classic CNN for noise removal, which is characterized by its simplest (i.e., cascaded convolutional filters and nonlinear activation functions) yet very deep (20 layers) network topology. The “plain” network architecture achieves superior performance not only in noise removal77, but also vision tasks such as object recognition124 and super-resolution109,125. DnCNN has been demonstrated to outperform the state-of-the-art BM3D denoising for 2-dimension natural images, which is reproduced on empirical 3-dimenstion MRI data in our study in terms of both image quality and cortical surface positioning. The versatile DnCNN can be also used to perform simultaneous denoising and super-resolution (referred to as VDSR in the context of super-resolution109). This versatility is beneficial for obtaining high-quality images at a true, high sub-millimeter resolution using only product sequences and reconstruction provided by vendors, which can only encode a whole-brain volume at a high resolution nominally because of the use of partial Fourier imaging and the increased T1 blurring during the inversion recovery. Simultaneous denoising and super-resolution is also helpful for obtaining images at ultra-high resolution (e.g., 0.25-mm isotropic resolution126, which requires averaging 8 repetitions from 10 hour scan on a 7-Tesla scanner) by making a balance between extremely challenging individual denoising or super-resolution and avoiding the use of prospective motion correction to acquire input noisy images at native ultra-high resolution for denoising127–131. Image super-resolution has also been shown to be an alternative way to obtain high-quality sub-millimeter resolution images for improving cortical surface reconstruction47.
Conclusion
Our unique dataset and systematic characterization of different denoising methods support the use of denoising methods for improving cortical surface reconstruction at sub-millimeter resolution from single-repetition anatomical MR images. The denoised images from three classical denoising methods, namely DnCNN, BM4D and AONLM, are shown to be similar to 6-repetition averaged images, with high image similarity quantified by MAD, PSNR and SSIM that are equivalent to those of T1-weighted images obtained by averaging ∼2.5 repetitions of the data. The discrepancies in the gray–white surface placement, gray–CSF surface placement and cortical thickness estimation are lower than 165 μm, equivalent to that of T1-weighted images obtained by averaging ∼1.55 to 2.24 repetitions of the data and on the same order as the test-retest precision of FreeSurfer. The scan-rescan precision of the cortical surface positioning and thickness estimation from the denoised single-repetition data is lower than 170 μm. The proposed approach would facilitate the adoption of next-generation cortical surface reconstruction methods in a wider range of applications and neuroimaging studies that require accurate models of cortical anatomy.
Data and code availability
The source code of the DnCNN network implemented using Keras API and the pre-trained models using the MGH 0.6-mm isotropic data will be available at https://github.com/qiyuantian/DnSurfer.
Supplementary Information

A representative coronal image slice from the raw data acquired using a slab-selective oblique-axial acquisition (a) and the same image slice corrected for the spatially varying intensity bias induced by the B1 field inhomogeneity (b).

A representative axial image slice from the single-repetition data (a, i), the 6-repetition averaged data (a, ii), and the single-repetition data denoised by DnCNN (a, iii), BM4D (a, iv) and AONLM (a, v), and their residuals (i.e., estimated noise) compared to the image from the single-repetition data (rows a, i).

Left-hemisphere vertex-wise contrast between the gray matter and white matter image intensity (expressed as [white − gray]/[white + gray]⋅100%) from the 6-repetition averaged data (column i), single-repetition data (column ii), single-repetition data denoised by DnCNN (column iii), BM4D (column iv) and AONLM (column v) averaged across 30 image volumes from the 5 evaluation subjects, displayed on inflated surface representations. Different cortical regions from the FreeSurfer cortical parcellation (i.e., aparc.annot) are depicted as colored outlines.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Left-hemisphere vertex-wise mean curvature of the reconstructed gray–white surfaces (a–c) and gray–CSF surfaces (d–f) from the 6-repetition averaged data (column i), single-repetition data (column ii), single-repetition data denoised by DnCNN (column iii), BM4D (column iv) and AONLM (column v) averaged across 30 image volumes from the 5 evaluation subjects, displayed on inflated surface representations. Different cortical regions from the FreeSurfer cortical parcellation (i.e., aparc.annot) are depicted as colored outlines.
The group mean and standard deviation of the mean absolute displacement of the gray–white surface estimated from the images from the single-repetition data, 2- to 5-repetition averaged data and the single-repetition data denoised by DnCNN, BM4D and AONLM compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects, calculated for 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer and for the whole brain.
The group mean and standard deviation of the mean absolute displacement of the gray–CSF surface estimated from the images from the single-repetition data, 2- to 5-repetition averaged data and the single-repetition data denoised by DnCNN, BM4D and AONLM compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects, calculated for 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer and for the whole brain.
The group mean and standard deviation of the mean absolute difference of the cortical thickness estimated from the images from the single-repetition data, 2- to 5-repetition averaged data and the single-repetition data denoised by DnCNN, BM4D and AONLM compared to the images from the 6-repetition averaged data across 30 image volumes from the 5 evaluation subjects, calculated for 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer and for the whole brain. displacement/difference of the gray–white surface, gray–CSF surface and cortical thickness estimated from two consecutively acquired 1-repetition data denoised by DnCNN, BM4D and AONLM across 25 image volumes from the 5 evaluation subjects, calculated for 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer and for the whole brain.
The group mean and standard deviation of the mean absolute displacement/difference of the gray–white surface, gray–CSF surface and cortical thickness estimated from two consecutively acquired 1-repetition data denoised by DnCNN, BM4D and AONLM across 25 image volumes from the 5 evaluation subjects, calculated for 34 cortical parcels (left and right hemispheres combined) from the Desikan-Killiany Atlas provided by FreeSurfer and for the whole brain.
Acknowledgments
Thanks to Mr. Ned Ohringer for assistance in volunteer recruitment and data collection. We gratefully acknowledge the use of the Siemens “Works-In-Progress” package WIP900, which provided the inner-loop accelerated MPRAGE pulse sequence and image reconstruction. This work was supported by the National Institutes of Health (grant numbers P41-EB015896, P41-EB030006, R01-EB023281, K23-NS096056, R01-MH111419, R01-MH124004, U01-EB026996, S10-RR023401, S10-RR019307 and S10-RR023043), a Massachusetts General Hospital Claflin Distinguished Scholar Award, and the Athinoula A. Martinos Center for Biomedical Imaging. B.B. has provided consulting services to Subtle Medical.
References
- 1.↵
- 2.↵
- 3.↵
- 4.
- 5.↵
- 6.
- 7.↵
- 8.
- 9.↵
- 10.↵
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.↵
- 25.↵
- 26.
- 27.↵
- 28.↵
- 29.
- 30.
- 31.
- 32.↵
- 33.↵
- 34.
- 35.
- 36.↵
- 37.↵
- 38.
- 39.
- 40.
- 41.
- 42.↵
- 43.↵
- 44.↵
- 45.
- 46.↵
- 47.↵
- 48.↵
- 49.
- 50.↵
- 51.↵
- 52.↵
- 53.↵
- 54.↵
- 55.↵
- 56.
- 57.
- 58.↵
- 59.↵
- 60.
- 61.
- 62.
- 63.
- 64.↵
- 65.↵
- 66.↵
- 67.↵
- 68.↵
- 69.↵
- 70.↵
- 71.↵
- 72.↵
- 73.↵
- 74.↵
- 75.↵
- 76.↵
- 77.↵
- 78.↵
- 79.↵
- 80.↵
- 81.↵
- 82.↵
- 83.↵
- 84.↵
- 85.↵
- 86.
- 87.
- 88.↵
- 89.↵
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.↵
- 96.↵
- 97.↵
- 98.↵
- 99.
- 100.↵
- 101.↵
- 102.↵
- 103.↵
- 104.↵
- 105.↵
- 106.
- 107.↵
- 108.↵
- 109.↵
- 110.↵
- 111.↵
- 112.↵
- 113.↵
- 114.↵
- 115.↵
- 116.↵
- 117.↵
- 118.
- 119.↵
- 120.↵
- 121.↵
- 122.↵
- 123.↵
- 124.↵
- 125.↵
- 126.↵
- 127.↵
- 128.
- 129.
- 130.
- 131.↵




