

Abstract
Advances in science and technology depend on the work of research teams and the publication of results through peer-reviewed articles representing a growing socio-economic resource. Current methods to mine the scientific literature regarding a field of interest focus on content, but the workforce credited by authorship remains largely unexplored, and appropriate measures of scientific production are debated. Here, a new bibliometric approach named TeamTree analysis is introduced that visualizes the development and composition of the workforce driving a field. A new citation-independent measure that scales with the H index estimates impact based on publication record, genealogical ties and collaborative connections. This author-centered approach complements existing tools to mine the scientific literature and to evaluate research across disciplines.
Introduction
Progress in science and technology depends on research teams working on specific topics of interest and on the publication of their results in peer-reviewed articles [1]. The rapidly growing body of scientific information [2] reflects past and current states of the art and represents an invaluable socio-economic resource guiding future research activities, policies and investments [3–8]. Its utility relies on the quality and accessibility of bibliographic databases [9, 10] and on refined methods to search and analyse the content of scientific articles [3, 6, 11–16]. Authorship on these articles credits contributions of individual team members with diverse expertise and skills [17–21], but choosing the best method to evaluate research, for example to identify potential experts, recruits and collaborators, remains a challenge [22]. Presently, the impact of individual contributors [23], journals [24], institutions and nations [25] is predominantly estimated based on citation counts of scientific articles (for reviews see [5, 26–28]). In a frequent scenario, a user interested in a specific topic queries a bibliographic database, scrutinizes the resulting list of relevant publications and learns readily about scientific advances. But, it is very difficult for the user to learn about the contributing teams and their impact. To address this recurring issue, I propose a new bibliometric approach, further referred to as TeamTree analysis (TTA). Using author names and publication years of scientific articles related to a field of interest, TTA reveals the development and composition of the workforce with new visuals, named TeamTree graphs (TTGs), and estimates the impact of authors with a new metric named TeamTree product (TTP). TTP takes into account three aspects of scientific production: publication of articles, the generation of offspring and the establishment of collaborations. TTP does not depend on citation counts or journal impact, but scales with the H index [23] and the sum of citations. Here, the principles of TTA are introduced and its main features are illustrated using a generic model and publications from selected fields of science and technology.
Methodology
The principal steps and key features of TTA are introduced in Fig 1 using generic publications. The TTA-derived parameters are summarized in Table 1. Typically, scientific articles related to a user-defined topic of interest are retrieved from a bibliographic database (Fig 1A; Table 2). From each article, TTA extracts the authors, the year of publication and a database-specific article identifier (Fig 1A). TTA includes author initials to reduce author ambiguity [29]. For some fields, frequent ambiguous author names were removed. TTA categorizes authors according to their byline position and sorts publications by year. Then, it assigns a chronologic author index (AI) and a randomly generated color (C) to each last author (Fig 1B). TTA focuses on authors on the last byline position as they are mostly responsible for the research [19]. In the following, the term “author” refers to “last author” unless indicated otherwise.

(A) Screenshots of the PubMed website and of a comma-separated values (csv) file illustrating a query in the bibliographic database MEDLINE, the download of scientific articles and the extraction of data required by TTA. (B) Table showing generic articles with identifiers (ID), authors separated by byline position, and years of publication. Only authors mentioned at least once on the last byline position are taken into account and indicated by generic names (AUx). TTA sorts articles by year of publication in ascending order, assigns to each last author a chronologic author index (AI) and a unique color (C) and counts the number of articles per author per year (PCy). Curved arrows indicate genealogical relations between ancestors and offspring on the last and first byline position, respectively. Straight arrows indicate collaborative connections between last authors and co-authors (out) and vice-versa (in). (C) Family tree and (D) collaborative network derived from the generic articles shown in panel B with genealogy- and collaboration-related parameters indicated for each author. AG, author generation; OC, offspring count; CC = CCout + CCin, number of collaborative connections. (E) Three-dimensional plot of key metrics (PC, publication count as last author) for a selected author (AU2) shown in panel B. The volume occupied by the author within the parameter space is indicated by the author-specific color and represented numerically by the TeamTree product (TTP). The table summarizes the TTA-derived parameters of generic authors. (F) TeamTree graphs (TTGs) of the generic authors shown in panel B indicating from top to bottom their publication record, genealogic and collaborative connections and TTP values. For publications and TTP values, signs of AI alternate between odd and even values. For genealogic relations, signs of family members are determined by the first generation author. To indicate collaborative connections, AI of last authors and co-authors are negative and positive, respectively. Symbol sizes represent indicated parameters.
TTA explores three aspects of scientific production: the publication record of authors, their genealogical relations and their collaborations. Several parameters are calculated to assess performance in each category (Table 1). To summarize the publication record of each author, TTA calculates the total numbers of articles listing the author on the first (PCfirst) and last byline position (PC), the number of publications (as last author) in each year (PCy; Fig 1B; Table 1), the publication period in years and the average annual publication count (PCannu; Table 1). Single author articles are counted as last author publications. Genealogical relations between authors are derived from offspring – ancestor pairs, where offspring and ancestor are listed on the first and last byline position of an article (Fig 1B, C). Three conditions apply: First, each offspring is assigned to a single ancestor with the earliest common article defining a genealogical relation. Second, this common article has to be published before the earliest (last author) publication of the offspring. Third, the AI value of the ancestor must be smaller than the one of the offspring. TTA assigns a generation index (AG) to ancestors (AG = i) and offspring (AG = i+1; Fig 1C; Table 1) and calculates for each ancestor the number of offspring (OC; Fig 1C) and the number of articles published with offspring (PCoff; Table 1). Families are defined as progeny of a first generation ancestor (AG = 1) encompassing all offspring (AG > 1). TTA derives collaborations based on co-authorship [30] (Fig 1B, D). For out- and in-degree connections, an author lists other authors as co-authors and an author is listed as co-author, respectively (Fig 1B). TTA calculates the numbers of these connections (CCin, CCout; Fig 1C), their sum (CC = CCin + CCout) and the number of corresponding publications per author (PCcol; Table 1). The TTA-derived metrics – PC, OC and CC – define a three-dimensional space, in which each author occupies a distinct volume reflecting publications, offspring and collaborative connections (Fig 1E). The product of these parameters, further referred to as TeamTree product (TTP), defines a new metric to estimate author contributions to a research field (Fig 1E; Table 1).
The workforce contributing to the field is visualized by TTGs. TTGs are scatterplots where each author is represented by a symbol with the AI value and the earliest year of publication plotted on the x and y axis, respectively. The symbols are displayed with author-specific colors (Fig 1F). TTGs provide a framework to illustrate an author’s contributions to each category analysed by TTA. To show the publication records, symbols connected by lines represent the years of publication with symbol sizes indicating the number of articles per year. To achieve an accessible presentation of the publication data, the sign of AI values alternates between odd (positive) and even (negative) numbers rendering a symmetric tree-like design (Fig 1F). Genealogical relations between authors are indicated by lines connecting ancestors and offspring. To represent this aspect with TTGs, the sign of the AI representing the first generation ancestor determines the AI sign of all family members (Fig 1F). To visualize collaborations in the field, lines connect last authors and co-authors with AI signs adjusted to negative and positive values, and symbol sizes indicating CCout and CCin values, respectively (Fig 1F). To represent the overall contribution of an author to the field, TTGs show authors with alternating AI signs and symbol areas representing TTP values (Fig 1F).
TTA is implemented with custom-written routines based on the open source software R [31] and selected R packages for data handling (data.table [32]), statistical and network analyses (igraph [33]; dunn.test [34]) and data visualization (eulerr [35]; ggfortify [36]; ggplot2 [37]; ggrepel [38]; igraph [33]; plot3D [39]). The R script is freely available upon request to the author and at https://github.com/fw-pfrieger/TeamTree. It can be used to analyse publications in a user-defined field of interest. Bibliographic records were obtained from MEDLINE using PubMed (https://pubmed.ncbi.nlm.nih.gov/) and from Web of Science (WoS) (https://apps.webofknowledge.com/; accessed via institutional subscription). To compare citation-independent TTP values with citation-based metrics, the Hirsch indices and the total number of citations were calculated from bibliographic records (WoS).
Results
To expose the utility of TTA, the new approach was applied to scientific articles from selected fields of research in science and technology (Table 2).
Visualizing the workforce driving research fields
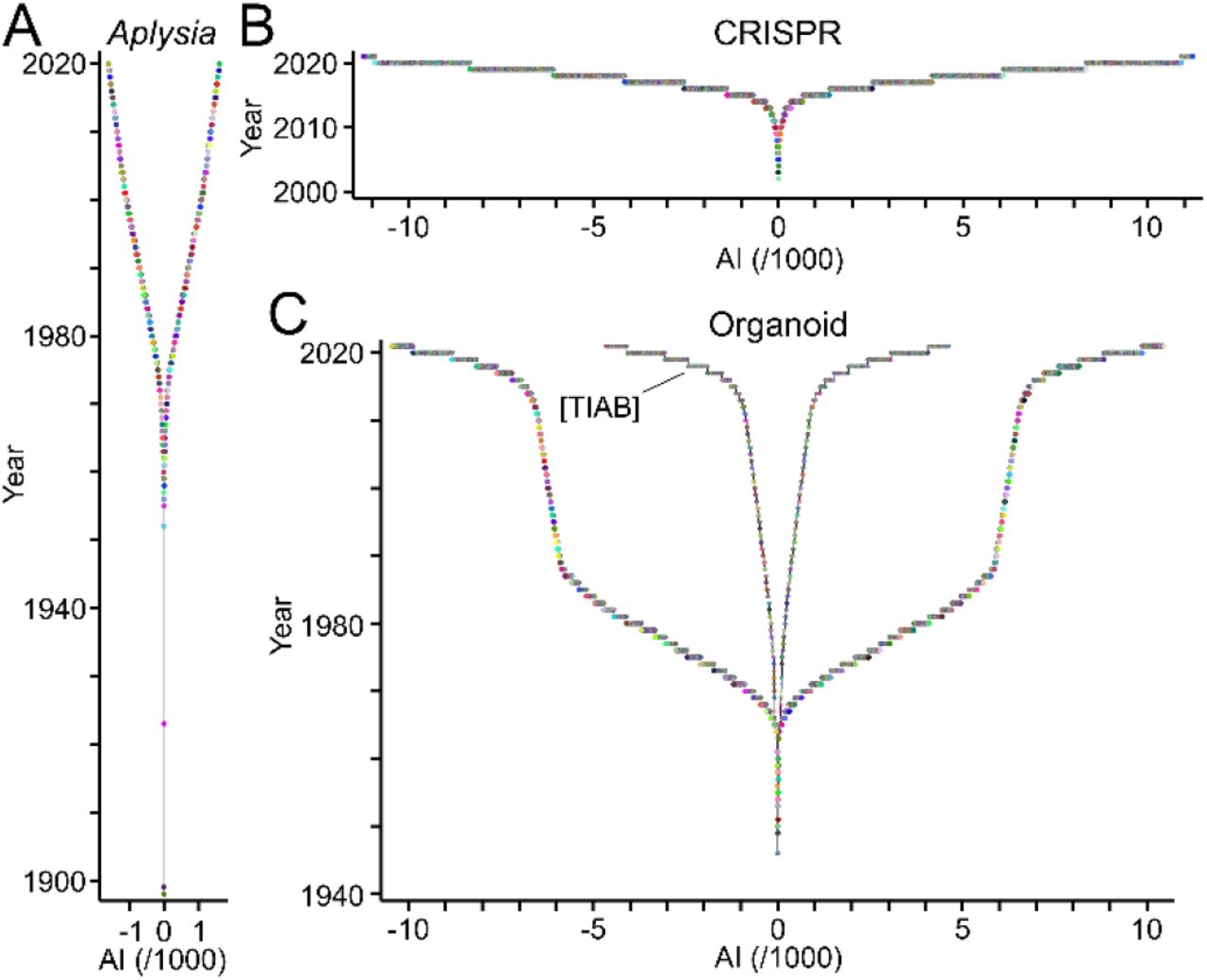
A new type of visual named TTG reveals the ensemble of authors contributing to a topic of interest (Fig 1). To exemplify this, TTA was applied to three fields of biomedical research each of which showing distinct history, size and dynamics (Fig 2). Corresponding publications were obtained from PubMed/MEDLINE (Table 2). Research on Aplysia, a genus of sea slugs, started at the end of the 19th century. Since then, the field expanded slowly but steadily reaching less than 2000 authors total [40] (Fig 2A). The discovery of “clustered regularly interspaced short palindromic repeats” (CRISPR) and the subsequent development of CRISPR-derived genetic tools established a new field, whose workforce is expanding exponentially reaching more than 10,000 authors within a decade [41] (Fig 2B). The field related to “organoids” shows a peculiar development. The workforce expanded transiently during the 1970ies and much of the 80ies (Fig 2C), but this phase was probably due to changing definitions of the term and its assignment to publication records [42]. It is absent when only publications bearing the term in the title or abstract are taken into account (Fig 2C; Table 2). The exponential growth of the workforce within the last decade (Fig 2C) was driven by important breakthroughs suggesting organoids as models of human organs [43, 44].
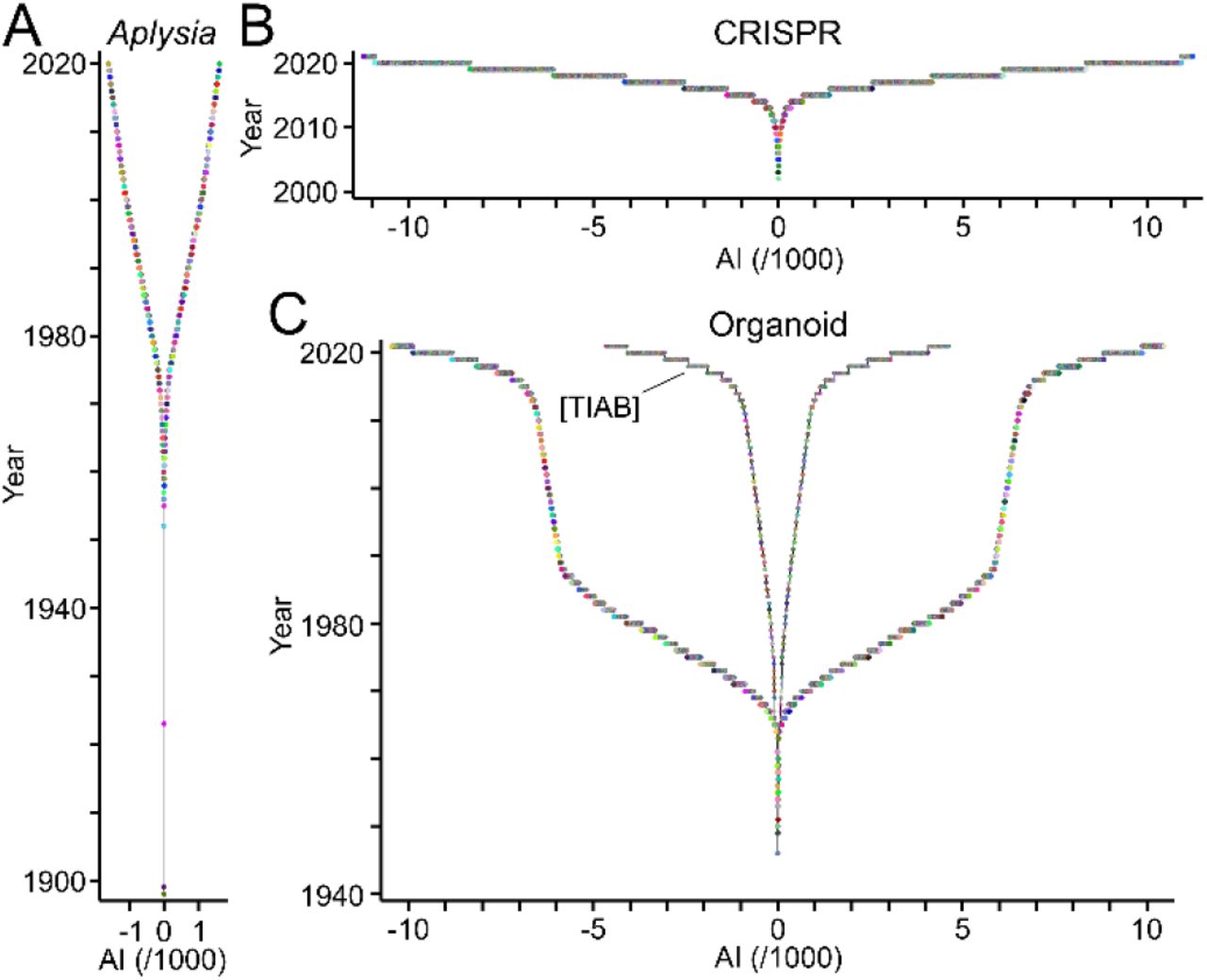
TTGs reveal the distinct duration, growth and size of the workforce publishing scientific articles related to Aplysia (A), CRISPR (B) and organoids (C). Circles represent authors contributing to each field with the year of their first publication as last author plotted against their AI values. Signs of AI values alternate for better accessibility. Note the distinct development of the “organoid” field in panel C when only publications were analysed, where the term “organoid*” is only mentioned in the title or abstract as indicated by the field specifier [TIAB].
Display and quantitative analysis of publication record, genealogy and collaborations
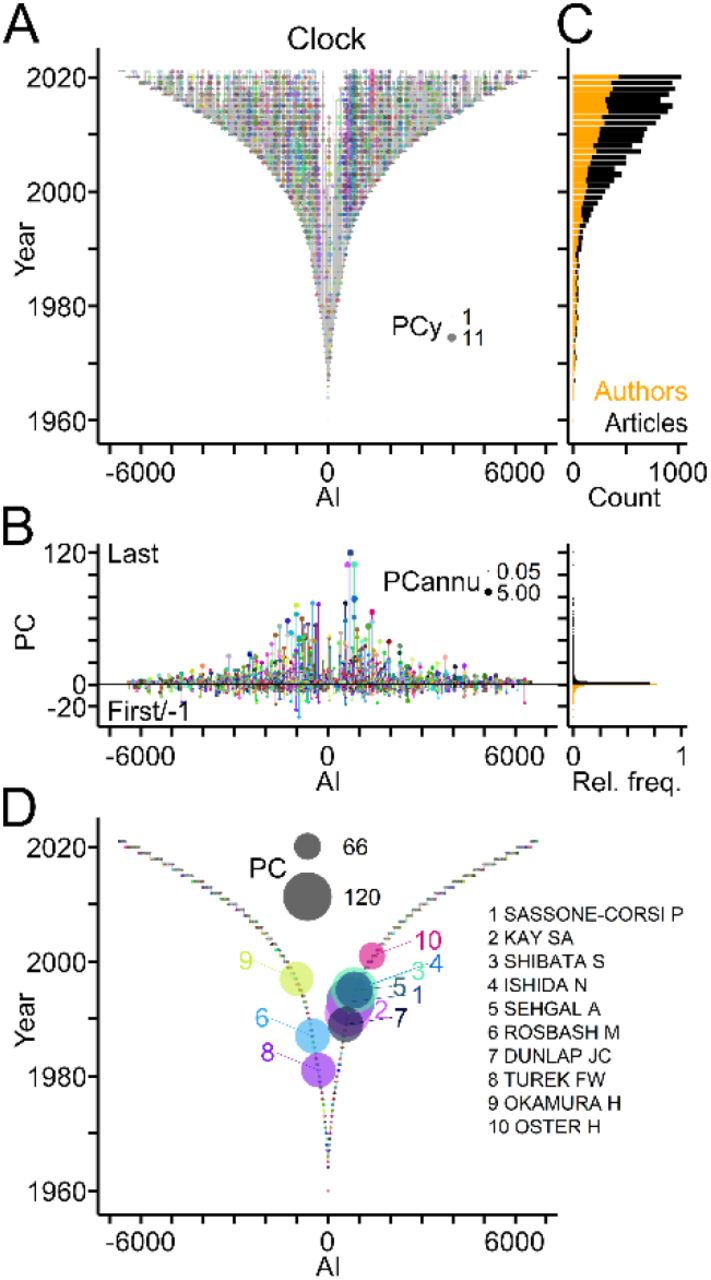
TTA evaluates the publication record of authors, the generation of offspring and the establishment of collaborations. To illustrate this point, TTA was applied to publications related to “circadian clock” (Clock) [45], a well-established field of biomedical research (source: PubMed/MEDLINE; Table 2). Fig 3 shows the publication records of authors in the Clock field using TTGs as framework. Individual authors published as many as 120 articles (PC), but 70% of the workforce contributed single articles (Fig 3B). This percentage was similarly high (68%), when authors entering during the last two years were excluded. The Clock field expanded rapidly within the last decades as indicated by linearly growing annual counts of newly entering authors and of published articles per year, respectively (Fig 3C). Ranking authors by PC values identified the top contributors of articles to the Clock field (Fig 3D).
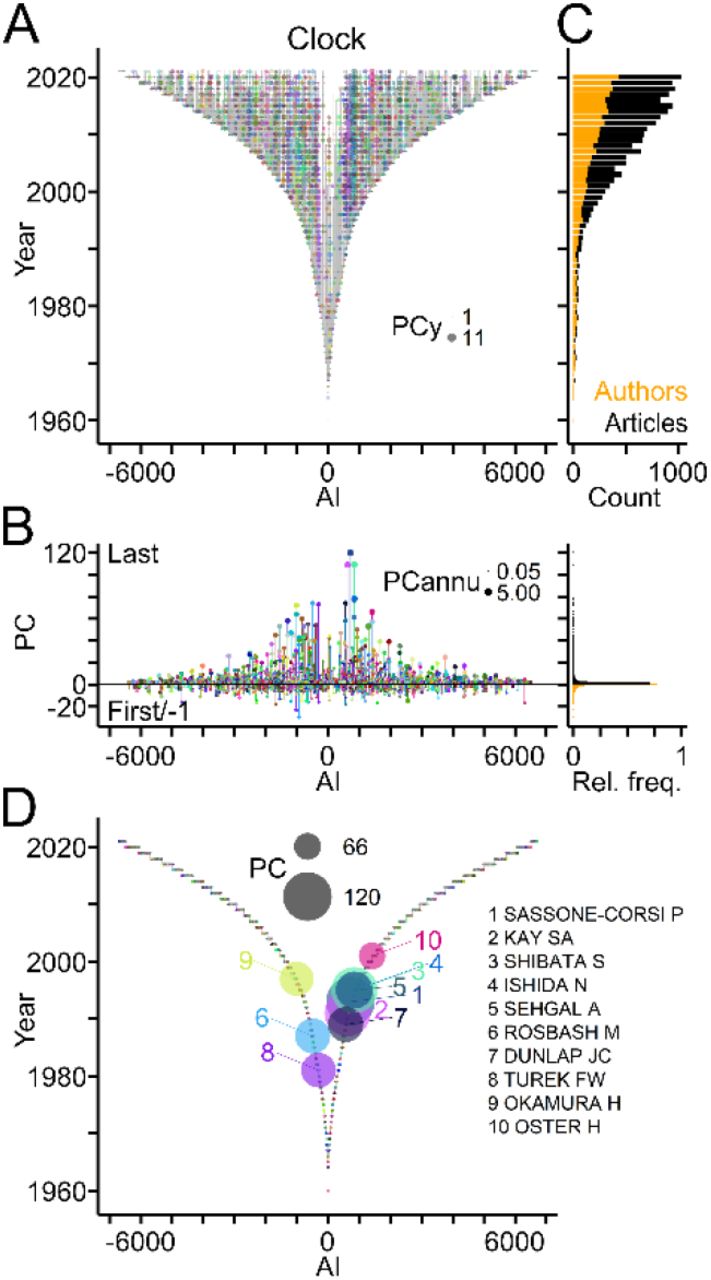
(A) TTG showing the publication records of authors working in the Clock field. Circles connected by vertical grey lines represent for each author, the years of publications as last author plotted against the AI. Circle area indicates number of publications per author per year (PCy). (B) Left, publication counts per author indicating last and first author articles by positive and negative values, respectively. Circle area indicates the average number of publications per year (PCannu). Right, relative frequency distributions of PC values shown on the left. (C) Number of authors entering the field per year (orange) and of articles (black) published per year. (D) TTG showing authors with top ten PC values indicated by circle area.
Fig 4 depicts genealogical relations in the Clock field based on last author - first author pairs of articles, and presents a quantitative assessment (Table 1). A quarter of authors published previously as first authors thus qualifying as offspring (Fig 3B) and 10% of the authors qualified as ancestors (Fig 4B). Ancestors generated up to 24 offspring and published up to 75 articles with their offspring (Fig 4B). Overall, the Clock field comprised 506 families with up to 40 members spanning maximally 6 generations (Fig 4B). For the last two decades offspring authors and publications with offspring represented a small, but constant fraction of the workforce entering the field each year and of the annual scientific production (Fig 4C). Ranking by OC values revealed the most prolific authors and their families in the Clock field (Fig 4D).

(A) TTG showing genealogic relations derived from publications. Circles and grey lines indicate ancestor-to-offspring connections. Connections of authors with the ten largest offspring count (OC) values are shown in color (names indicated in panel D). Circle area indicates OC. AI signs of offspring and of ancestors were adjusted to the first generation ancestor. (B) Left, from top to bottom, OC values, number of articles with offspring (PCoff), author generation (AG) and family size (FS). Circle area indicates PCannu. Right, relative frequency distributions of parameters shown on the left. (C) Fraction of offspring authors (orange) entering the field and of publications with offspring (black) compared to total numbers per year. (D) Names and family connections of authors with top ten OC values indicated by circle area.
Fig 5 shows collaborative connections in the Clock field based on co-authorship and quantitative data using collaboration-specific parameters (Table 1). In total, half of the authors in the Clock field established a variable number of out- and in-degree collaborations with up to 90 authors and published up to 104 collaborative papers as last and co-author, respectively (Fig 5B). During the last two decades, collaborators represented half of the new authors entering per year and their contribution remained fairly constant (Fig 5C). The number of authors per article increased steadily (Fig 5A). Ranking authors based on collaboration counts revealed strongly connected teams in the field and their networks (Fig 5D).

(A) TTG showing collaborations between last authors (out; negative AI) and co-authors (in; positive AI) derived from co-authorship on scientific articles. Connections of authors with ten highest connection count (CC) values (in+out) are shown in color. Circle areas indicate CCout and CCin values of these authors. Inset shows the mean author count (AC) per article published each year. (B) Left, counts of collaborators and of collaborative articles per author. Circle area indicates PCannu. Right, relative frequency distributions of parameters shown on the left. (C) Fractions of new collaborating authors (orange) and of collaborative publications (black) compared to total numbers per year. (D) Names of authors with top ten CC values and their networks. Circle area indicates CC values normalized to the maximum.
Workforce dynamics and field development
TTA was used to explore how the workforce of the Clock field developed over time. Plotting the number of authors entering and exiting the field based on the first and last year of their publications, respectively, indicated strong growth of the workforce. The accuracy of exit counts decreases for the last years (Fig 6). The publication periods or life-spans of authors reached nearly five decades, but the large majority published only during one year and in most cases a single article (Fig 3C; Fig 6A-C). Separating “Newcomers” entering the field per year from “Established” authors revealed that the established workforce consisted mostly of authors with genealogical and collaborative ties, whereas most newcomers had collaborative connections or no ties and contributed single articles (Fig 6D).
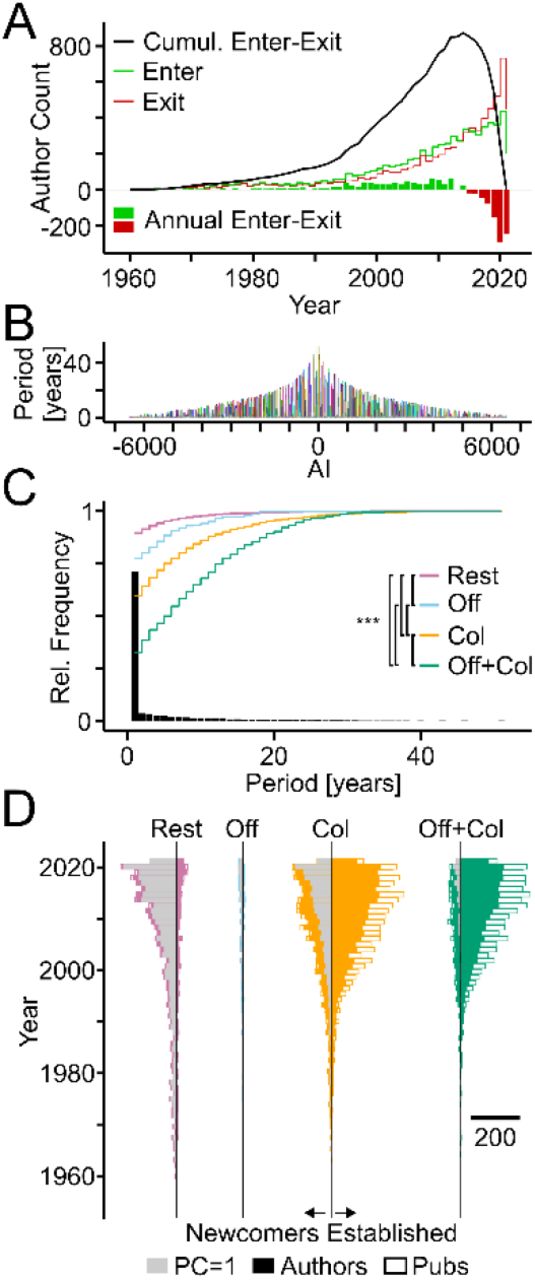
(A) Annual counts of authors entering (green bars) and leaving the field (red bars) with lines showing cumulative sums. (B) Publication periods of individual authors in years. (C) Bars and lines showing the relative frequencies of all publication periods and the cumulative relative frequencies of publication periods of authors from indicated categories, respectively. Col, authors with collaborative but no genealogical connections; Off, genealogical but no collaborative connections; Off+Col, both types of connections; Rest, without connections. Statistically significant differences among groups are indicated (Kruskal-Wallis tests chi-squared = 265.12, df = 3, p < 0.0001. Asterisks indicate level of significance: ***, p < 0.001; post-hoc Dunn test, Benjamini-Hochberg adjusted; sample size = 256; adjusted to smallest sample size by random selection). (D) Horizontal bars indicate number of authors (filled) and of publications (white) per year of newcomers (left) and established teams (right) from the indicated categories. Grey bars indicate authors with single publications. Scale bar indicates number of authors and publications.
Evaluation of scientific production based on publications, offspring and collaborations
A key goal of bibliometric analyses is to gauge author impact on a field of research. The new metric TTP takes into account an author’s publication record (PC), offspring generation (OC) and collaborations (CC) (Table 1). The concept was introduced with generic publications (Fig 1). Its validity was tested first using publications related to the Clock field (Fig 7). Intersection of the top 100 authors ranked by three key parameters showed that a core of 43 authors figured among the top in all three categories (Fig 7A). Three-dimensional scatterplots of the parameters revealed that authors occupy distinct volumes (Fig 7B) indicating that TTP, calculated as product PC × OC × CC, allows for a more differentiated author ranking than each parameter alone. Fig 7C shows authors with top ten TTP values in the Clock field. To validate its utility, TTP was compared with frequently used citation-based benchmarks of author performance. Scatterplots and statistical analyses revealed that TTP values of individual authors working in the Clock field correlated with the total numbers of citing articles (ρ = 0.828; p < 0.001) and with their H indices (ρ = 0.924; p < 0.001; n = 731; Spearman’s rank correlation; Fig 7D).
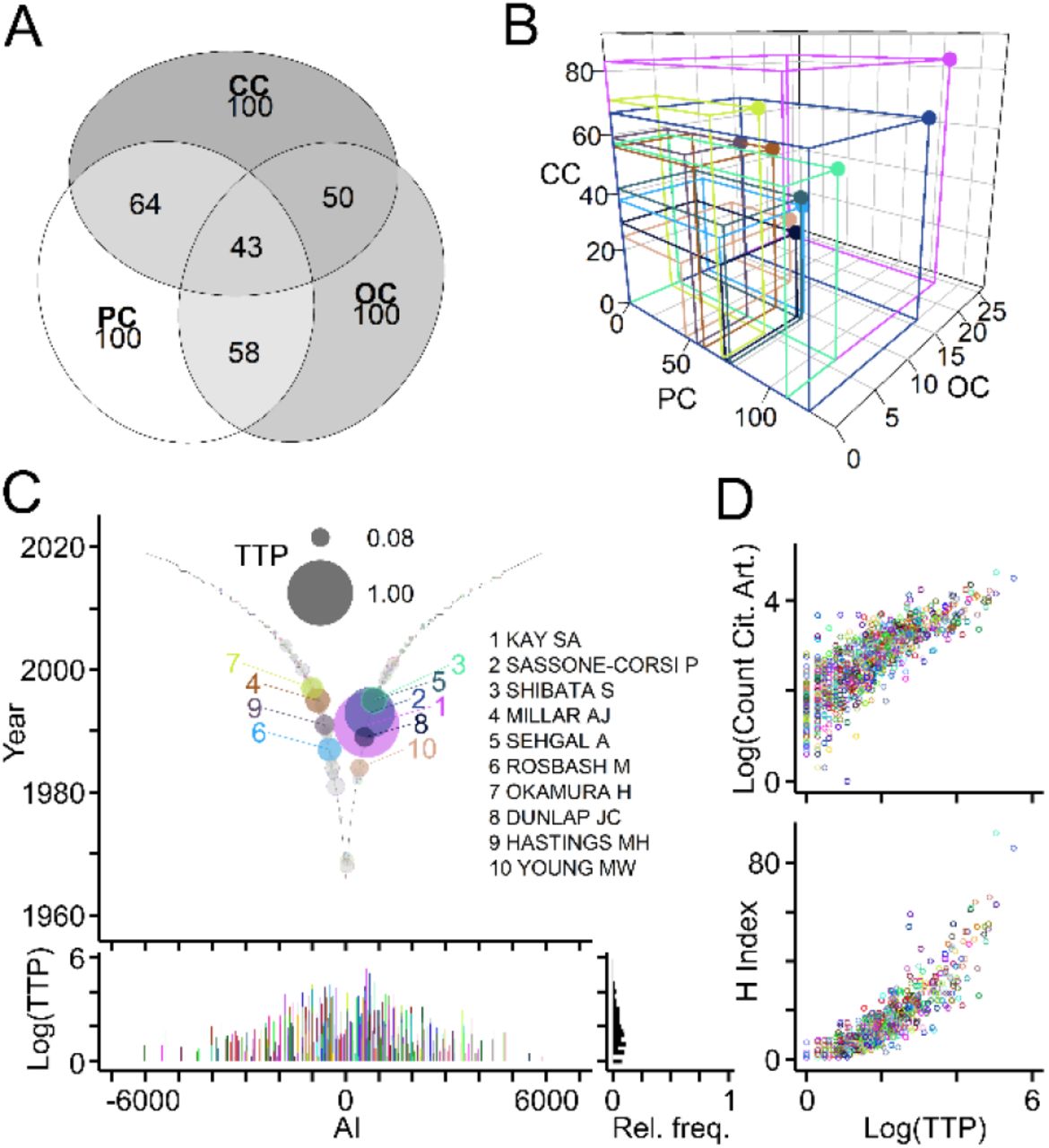
(A) Numbers of intersecting authors in the Clock field ranking among top 100 for each parameter (PC, OC, CC). (B) Scatterplot of indicated parameters for authors with top ten TeamTree product (TTP) values calculated as the volume occupied by each author (PC × OC × CC). (C) Top, graph showing the TTP of authors in the Clock field with colored circles and names indicating authors with ten higest values. Grey circles with colored border indicate authors with TTP values above zero. Circle size indicates log10(TTP) normalized to maximum. Bottom, log10(TTP) values and their relative frequency distribution. (D) Scatterplots, where circles represent individual authors (indicated by color) with their total number of citing articles (top; log10 values) and their H indices (bottom) plotted against their TTP (log10 values).
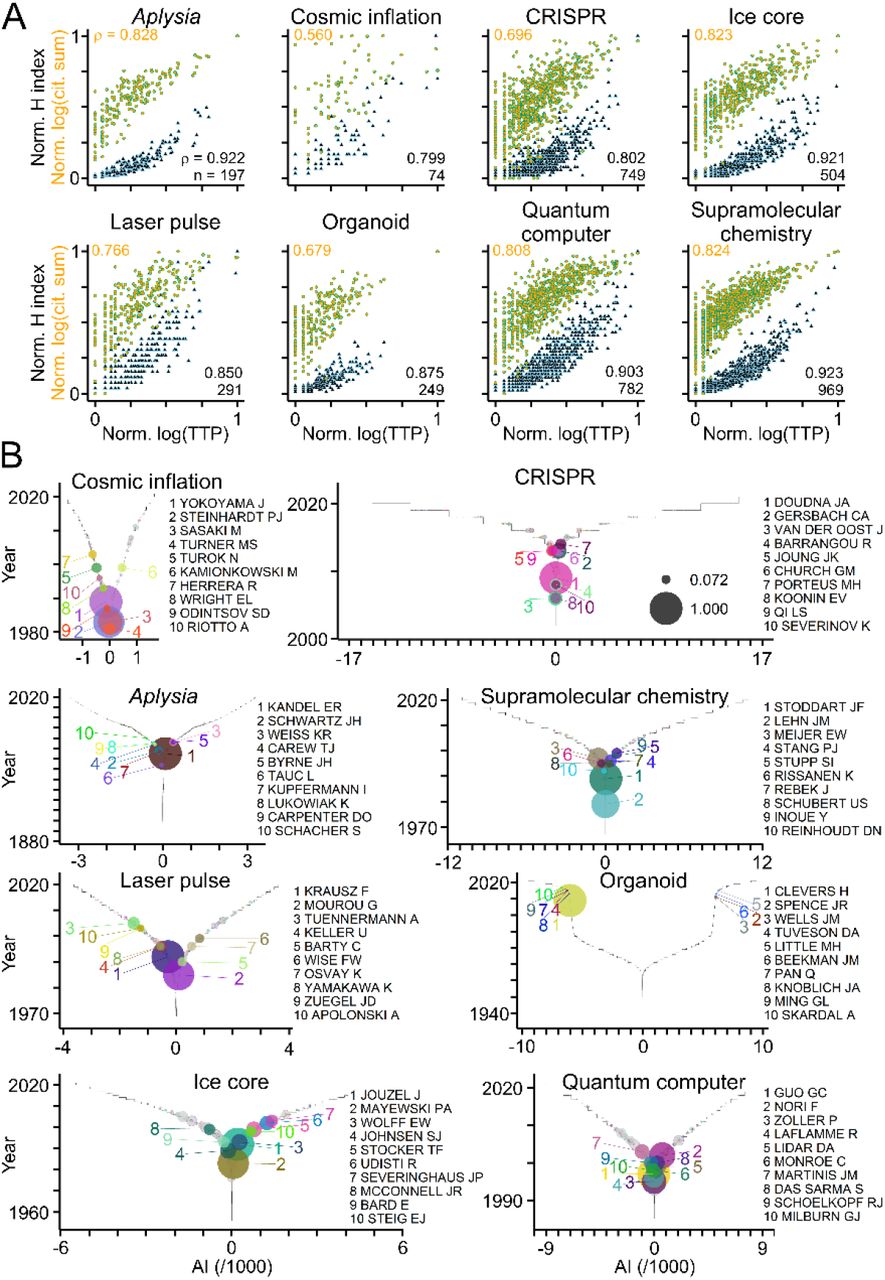
To further validate TTP as citation-independent measure of productivity, TTA was applied to publications from the fields of biomedical research shown in Fig 2 and to selected fields of science and technology (Table 2). As shown in Fig 8, the TTP values of authors correlated significantly with their H indices and citation counts across fields and disciplines (Fig 8A), and ranking authors by TTP values identified key players in each field (Fig 8B).

(A) Scatterplots where circles represent individual authors publishing in the selected fields of science and technology (Table 2) with their H indices (black-blue triangles; normalized to maximum) and sum of citations (orange-green circles; log10 values normalized to maximum) plotted against their TTP values (log10 values normalized to maximum). Numbers indicate rho values and sample sizes (Spearman’s correlation test; p < 0.0001 for all comparisons). (B) Graphs showing TTP values of authors in selected fields with colored circles and names indicating authors with ten highest TTP values. Grey circles with colored border indicate authors with TTP values above zero. Circle size indicates log10(TTP) normalized to maximum.
Discussion
TTA fills a gap between global investigations of the scientific endeavour and the recurrent need to identify and evaluate the teams working on a user-defined topic of interest in science and technology.
A prime feature is the new measure to estimate scientific production named TTP. Several aspects distinguish this metric from existing author-level indicators. TTP takes into account three important aspects of research activity: the publication of peer-reviewed scientific articles, the training and mentoring of junior scientists, who continue their career within the field, and the establishment of collaborative connections that signify recognition due to specific expertise and capacities. The respective parameters are derived solely from the author(s) of scientific articles and the year of publication. Thus, TTP estimates scientific production independently from citation counts and augments the group of indicators that do not rely on this factor [46–49]. Notably, the significant correlation of TTP values of authors with their numbers of citations and their H indices in all fields tested indicates the usefulness of the new measure. A second feature introduced here are new visuals named TTGs that provide users with ad-hoc views on the workforce driving a field. They reveal its origin, development and size, and expose the publication records of authors as well as their genealogical and collaborative connections. These graphs complement present approaches to display bibliometric information and to visualize different aspects of scientific production [50–58].
TTA exposes factors that impact the workforce development of a field. For example, the calculation of publication periods revealed that few authors contributed for more than one year to the Clock field. This finding supports previous reports that in many research areas only a small fraction of the workforce publishes during long periods of time [59]. The delineation of families and collaborator networks in the Clock field revealed that genealogical and collaborative connections prolong the life-span of authors. These observations are in line with studies showing the relevance of training and mentorship [60–64] and the importance of collaborations [65–72]. The automatic delineation of family connections from first author-last author pairs provides an alternative to efforts requiring user input [73–75] (https://www.genealogy.math.ndsu.nodak.edu/, https://academictree.org/). However, TTA underestimates offspring counts in the case of co-first or co-last authorship, of alphabetical author lists or of field-specific author ranking [76, 77]. Other caveats should be mentioned: TTP values are field-specific, scale with the size of research groups and depend on the publication period of authors. Therefore, TTP-based ranking is context-dependent and unsuited to evaluate junior scientists [78]. Moreover, TTP is highly selective as only a fraction of authors has non-zero values, and it cannot value innovative, ground-breaking contributions from small teams or from teams that contribute only briefly to a field. TTA like all other name-dependent approaches faces the challenge of author disambiguation, which can be mitigated by assignment of unique author identifiers (https://orcid.org/) and computational algorithms [5, 29, 79–83]. Honorary and ghost authorship will confound results of TTA depending on their prevalence in the field [84, 85].
Peer-reviewed articles were used to introduce the features of TTA as this form of publication represents the core of scientific production [1], but the approach may also be applied to other types of publications such as preprints [86] and patents [87]. Future versions of TTA should provide web-based access to TTA allowing for direct retrieval and immediate processing of bibliographic information and the interactive display of results.
Supporting information
S1 File. TTA-derived results for the Clock field. Csv file summarizing TTA data for the Clock field using PubMed articles related to “circadian clock”.
Acknowledgments
The author thanks V. Demais, S. Eglen, N. Elghobashi-Meinhardt, J. Jouzel, J.M. Lehn, M. Muzet, V. Pallottini, J.L. Paluh, B. Poulain, H. Runz, J.P. Sauvage, D. Schulte, S. Silber and M. Slezak for helpful discussions and comments on previous versions of the manuscript.
Footnotes
This is a substantially revised version of the previous ms.
References
- 1.↵
- 2.↵
- 3.↵
- 4.
- 5.↵
- 6.↵
- 7.
- 8.↵
- 9.↵
- 10.↵
- 11.↵
- 12.
- 13.
- 14.
- 15.
- 16.↵
- 17.↵
- 18.
- 19.↵
- 20.
- 21.↵
- 22.↵
- 23.↵
- 24.↵
- 25.↵
- 26.↵
- 27.
- 28.↵
- 29.↵
- 30.↵
- 31.↵
- 32.↵
- 33.↵
- 34.↵
- 35.↵
- 36.↵
- 37.↵
- 38.↵
- 39.↵
- 40.↵
- 41.↵
- 42.↵
- 43.↵
- 44.↵
- 45.↵
- 46.↵
- 47.
- 48.
- 49.↵
- 50.↵
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.↵
- 59.↵
- 60.↵
- 61.
- 62.
- 63.
- 64.↵
- 65.↵
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.↵
- 73.↵
- 74.
- 75.↵
- 76.↵
- 77.↵
- 78.↵
- 79.↵
- 80.
- 81.
- 82.
- 83.↵
- 84.↵
- 85.↵
- 86.↵
- 87.↵





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}