

Abstract
Humans and other group-living animals tend to distribute their social effort heterogeneously; individuals predominantly interact with their closest companions while maintaining weaker social bonds with less familiar group members. By incorporating this heterogeneity into a mathematical model we find that a single parameter, which we refer to as social fluidity, controls the level of social mixing in the population. Large values of social fluidity correspond to gregarious behavior whereas small values signify the existence of persistent bonds between individuals. To investigate how social behavior influences the likelihood of an epidemic outbreak we derive an analytical expression of the relationship between social fluidity and the basic reproductive number of an infectious disease. We compare social behavior across 12 species by applying the model to empirical human and animal social interaction data. For species that form strong social bonds, the model describes frequency-dependent transmission that is highly sensitive to changes in social fluidity. As social fluidity increases, animal-disease systems become increasingly density-dependent. Finally, based on a computational disease spread model on empirical social data, we find that social fluidity is a stronger predictor of disease outcomes than both group size and connectivity.
Social behavior is fundamental to the survival of many species such as ants, humans, and dolphins. It allows the formation of social groups providing fitness advantages from greater access to resources and better protection from predators [1]. Within these groups structure emerges from the interactions that occur when individuals communicate across space, cooperate in sexual or parental behavior, or clash in territorial or mating conflicts [2]. While many animal societies have been studied independently [3], some questions about the nature of social living can only be answered by comparing social behavior across a range of species [4]. This motivates the question: how can we compare the social behavior of one species to that of another?
Social animals typically have limited time and resources to invest in their relationships [5]. To compensate, the social effort of an individual tends to be distributed heterogeneously among the members of their group. Despite the growing evidence for this in human communication [6, 7, 8], attempts to quantify this aspect of sociality in animal systems are often challenged by unavoidable sampling biases [9]. Furthermore, while heterogeneous interaction frequencies and temporal dynamics such as circadian rhythms and bursty activity patterns have become common in social network models [10], realistic assumptions about how individuals distribute their social effort are rarely incorporated.
When social interaction requires shared physical space it can also be a conduit for the transmission of infectious disease [11]. It is generally thought that if transmission occurs through the environment then the risk of epidemic is driven by group size (density-dependence) [12], whereas if transmission requires close proximity encounters that only occur between bonded individuals then we expect social connectivity to determine the outcome (frequency-dependence) [13]. In reality, however, animal-disease systems are not so easy to categorize [14]. For example, social ties must be created to maintain cohesiveness in a growing social group [15], implying that transmission through direct contact may in fact depend on population density. On the other hand, as social effort is distributed heterogeneously, low levels of social mixing may constrain the spread of the disease [16].
Here, we introduce a mathematical model based on the concept of social fluidity which we define as heterogeneity in the distribution of social effort. Using empirical data from previous studies, we estimate the social fluidity of a number of human and animal social systems. Using analytical and computational models of disease spread we show that social fluidity predicts disease outcomes better than other social behavioral indicators and spans the distance between density-dependent and frequency-dependent disease systems.
Modeling social heterogeneity & disease transmission
Our objective is to measure social heterogeneity in a range of human and animal populations and provide an understanding of how social behavior influences the susceptibility of the group to infectious disease. We start by introducing a model that captures hidden elements of social dynamics (in particular, how individual group members distribute their social effort) and mathematically describe the relationships between social variables that are routinely found in studies of animal behavior (in particular, the number of social ties and the number of interactions observed). We then couple this social behavior model with a general model of infectious disease spread to expound the link between social behavior and disease outcomes.
Significance
The study of relationships within animal groups has provided many insights into the nature of social behavior. Despite this, finding a reliable measure of sociality that can be used to compare animal social systems has remained a challenge. We introduce social fluidity, a measure of heterogeneity in how individuals choose to distribute their social effort across the group. We demonstrate the use of this measure by applying it to 57 social networks from 12 animal species. Our results indicate that social fluidity is a better predictor of disease spread than measures typically used in social network analysis such as the mean number of social ties or the size of a social group.
Social behavior model
Consider a closed system of N individuals and a set of interactions between pairs of individuals that were recorded during some observation period. These observations can be represented as a network: an individual, i, is a node; if at least one interaction between nodes i and j has been observed then we say that an edge exists between them; the edge weight, wi,j, denotes the number of times this interaction was observed. The total number of times i was observed interacting is denoted by strength,  , and the number of nodes with whom i is observed interacting is its degree, ki.
, and the number of nodes with whom i is observed interacting is its degree, ki.
We focus on one individual in the system, which we name the focal node, i, and consider the si interactions in which it participated. We define xj|i to be the probability that an interaction involving i will also involve node j. Therefore the probability that at least one of these interactions is with j is 1 − (1 − xj|i)si.
The main assumption of the model is that the values of xj|i over all i, j pairs are distributed heterogeneously according to a probability distribution, ρ(x)1. Thus, after s observed interactions of the focal node, the probability that an edge exists between the focal node and any other individual in the population is

Our goal is to find a form of ρ that accurately reproduces network structure observed in real social systems. Motivated by our exploration of empirical interaction patterns from a variety of species (Figure S1), we propose that ρ has a power-law form:
 where φ (> 0) controls the heterogeneity in the values of x, and e simply truncates the distribution to avoid an asymptote at x = 0. Combining (1) and (2) we find that
where φ (> 0) controls the heterogeneity in the values of x, and e simply truncates the distribution to avoid an asymptote at x = 0. Combining (1) and (2) we find that
 where the notation 2F1 refers to the Gauss hypergeometric function [17]. The value of e is determined by
where the notation 2F1 refers to the Gauss hypergeometric function [17]. The value of e is determined by  and therefore depends on N and φ (Materials and Methods A.). It follows that the degree of the focal node is determined by its activity rate, the level of heterogeneity in partner choice, and the size of the population (Materials and Methods B.). More explicitly,
and therefore depends on N and φ (Materials and Methods A.). It follows that the degree of the focal node is determined by its activity rate, the level of heterogeneity in partner choice, and the size of the population (Materials and Methods B.). More explicitly,
 where 〈k〉 is the expected degree of the focal node.
where 〈k〉 is the expected degree of the focal node.
The parameter φ controls the heterogeneity in interaction frequencies and is therefore the main determinant of social mixing in the model. We use the term social fluidity to refer to this quantity. Figure 1 illustrates how the value of φ can create different types of social behavior. Low social fluidity (φ ≪ 1) would produce what we might describe as “allegiant” behavior: interactions with the same partner are frequently repeated at the expense of interactions with unfamiliar individuals. As φ increases, the model produces more “gregarious” behavior: interactions are repeated less frequently and the number of partners is larger. While this phenomena could be described as “social strategy” or “loyalty” [18, 19], we feel that “social fluidity” is most appropriate for this work as it conveys an intuitive notion relevant to disease propagation [20].

Left: Each individual can be represented as a single point on this plot. Dashed lines mark the boundary of the region where data points can feasibly be found. (4) is plotted for two values of φ representing two possible types of social behavior; as the number of observed interactions grows, the set of social contacts increases; the rate at which it increases influences how we categorize their social behavior. Middle: The weight of the edges between i and the other nodes represents the propensity of i to interact with each of the other individuals in the population. Right: Probability distributions that correspond to the different levels of heterogeneity in the contact propensities, both distributions are expressed by (2).
Disease transmission model
Building on the social behavior model introduced in the previous section, we consider a model of disease transmission. We focus on the basic reproductive number R0, defined as the mean number of secondary infections caused by a single infectious individual in an otherwise susceptible population. We first derive a formula for the individual reproductive number, r(si), in terms of the relative rate of activity of the individual, and define R0 to be the mean of {r(si)} over the population. By calibrating the disease parameters in a way that controls for varying time-scales of activity in different populations, we obtain a result that quantifies the relative significance of social fluidity across a range of social systems including those driven by group size (density-dependent transmission) and those driven by group connectivity (frequency-dependent transmission).
In our model, disease transmission requires an infected individual, i, who is social (i.e. has si interactions during an observation period of duration ∆t) and may interact with any other individual, j (with probability xj|i). When such an interaction occurs, i will infect j with probability β. The infectiousness of i continues for a period of duration τ, where τ is an exponentially distributed random variable with mean 1/γ (i.e. γ is the recovery rate).
Assuming the interactions of i are distributed randomly across the observation period, it follows that transmission events follow a Poisson process with rate  Thus the probability that infection transmits from i to any given j is
Thus the probability that infection transmits from i to any given j is

The reproductive number for i, r(si), is found by integrating (5) over all possible values of τ and xj|i then multiplying by the number of susceptible individuals, N − 1 (SI Text).
Instead of choosing infection parameter values that pertain to a specific disease or social system, we select values for each system separately in a way that exposes the effects of population size and social fluidity. We achieve this by setting the mean infectious period in such a way that would cause R0 to be equal to the constant R* if the population was large and homogeneously mixed, i.e every interaction is with a new partner (Materials and Methods D.). Consequently, social systems with a high interaction frequency are coupled with diseases that have relatively short mean infectious periods.
After calibrating the parameters we can derive the following result for the reproductive number of an individual that was observed interacting s times,
 where 〈s〉 is the mean of {si} over the population. In all the analysis presented we arbitrarily choose R* = 2.
where 〈s〉 is the mean of {si} over the population. In all the analysis presented we arbitrarily choose R* = 2.
To further expose the dependencies between population density, social fluidity, and disease transmission we evaluate N and R0 over a range of e and φ values (the formula for N (e, φ) is given in Materials and Methods A. while for R0 we assume s = 〈s〉 in (6)). At small population sizes, R0 increases with N and converges as N goes to ∞ (Figure 2A). The rate of this convergence increases with φ. When φ < 1, the limit of R0 is a function of φ (Figure 2B). At these values of φ, the individual will choose to repeat interactions despite having the choice of infinitely many potential interaction partners. When φ > 1 and the population is large the probability of a repeated interaction falls to zero and we have that R0 = R*.

A: Theoretical results from (6); the relationship between R0 and population size is shown to depend on the value of φ. Dashed lines show the limit for large N. B: In large populations R0 increases with φ up to φ = 1. Beyond this value, infections occur as frequently as they would in a homogeneously mixed population.
Social behavior & disease spread in empirical systems
The previous section introduced a model of social behavior in which social fluidity, φ, quantifies heterogeneity in the way individuals distribute their social effort among other members of the population. To understand the results of the model in the context of real systems we estimate φ in 57 networks from 19 studies of human and animal social behavior (Materials and Methods) [21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39].
We focus our attention to those interactions which are capable of disease transmission (i.e. those that, at the least, require close spatial proximity). Each dataset provides the number of interactions that were observed between pairs of individuals (SI Text). We assume that the group size, N, is equal to the number of individuals observed in at least one interaction. Figure S1 shows the data and the distribution fitted using maximum likelihood estimation.
The model provides a good fit to every dataset; the worst fitting animal social network agrees with the model better than synthetic data generated 92% from model simulation and 8% from random noise (SI Text). For comparison, the model was also applied to 9 networks generated from social media data [40], 3 of which showed less agreement with the model than any of the non-electronic networks (SI Text). Since agreement between the model and the data is therefore not a certainty, it is remarkable that the social fluidity model is applicable to such a wide range of animal social networks.
Characterizing social fluidity
Figure 3 shows the estimated values of φ for all our study populations. We organize the measurements of social fluidity by interaction type. Aggressive interactions have the highest fluidity (which implies that most interactions are rarely repeated with the same individuals), while grooming interactions have the lowest (which implies frequent repeated interactions with the same individuals). Social fluidity also appears to be related to species: ant systems cluster around φ = 1, voles around φ = 0.7, humans around φ = 0.6 (with the exception of lower values observed in the high school data and the last day of a conference). However, we do not find that social fluidity is highly correlated with sociality type [41]. This is illustrated by the sizable difference in social fluidity between the sheep, bison, and cattle versus the kangaroos and bats all of which are categorized as fission-fusion species.
There is no significant correlation between the mean number of observations per individual,  , and φ (Pearson R2 = 0.04, p = 0.14), which implies that sample size does not affect the estimate (Figure S2A). Larger populations tend to have smaller social fluidity values (Pearson R2 = 0.205, p < 0.001), however, this correlation is dependent on the presence of a few large populations in our data (N > 200) (Figure S2B). Larger values of φ correspond to higher mean degrees (Pearson R2 = 0.16, p = 0.002) and less heterogeneity in the distribution of edge weights (measured as the variance divided by the mean
, and φ (Pearson R2 = 0.04, p = 0.14), which implies that sample size does not affect the estimate (Figure S2A). Larger populations tend to have smaller social fluidity values (Pearson R2 = 0.205, p < 0.001), however, this correlation is dependent on the presence of a few large populations in our data (N > 200) (Figure S2B). Larger values of φ correspond to higher mean degrees (Pearson R2 = 0.16, p = 0.002) and less heterogeneity in the distribution of edge weights (measured as the variance divided by the mean  (Pearson R2 = 0.339, p = 0.001) (Figure S2C and D). Incidentally, weight heterogeneity and mean degree are uncorrelated in these data (Pearson R2 = 0.005, p = 0.568) implying that φ combines two distinct features of social behavior.
(Pearson R2 = 0.339, p = 0.001) (Figure S2C and D). Incidentally, weight heterogeneity and mean degree are uncorrelated in these data (Pearson R2 = 0.005, p = 0.568) implying that φ combines two distinct features of social behavior.

Each point represents a human or animal system for which social fluidity was estimated. Results are organized by interaction type: aggression includes fighting and displays of dominance, food sharing refers to mouth-to-mouth passing of food, antennation is when the antenna of one insect touches any part of another, space sharing interactions occur with spatial proximity during foraging, face-to-face refers to close proximity interactions that require individuals to be facing each other, association is defined as co-membership of the same social group.
Impact of social fluidity on disease transmission
To test the validity of the model and examine the utility of φ as an indicator of disease outcomes we simulated the spread of disease based on the interactions that occurred in the empirical data (Materials and Methods E.). We assume that all individuals are equally likely to introduce the infection to the group. In doing so we avoid biasing our choice of infection seed to those who are more socially active (our results are therefore not influenced by degree heterogeneity). Thus, the basic reproductive number, R0, is defined simply as the mean of the individual reproductive numbers over the entire population.
For each individual, i, we compared the simulated number of secondary infections to the prediction for r(si) given by (6). A small amount of error was observed (between 0.1 and 0.258 with one outlier at 0.344) and the prediction consistently overestimated R0 in human systems (Table S3), possibly because of the bursty nature of human contact [42]. Despite this, our overall conclusions from the disease simulation are consistent with the predicted results.
Figure 4 shows that φ correlates with (simulated) R0 better than other network metrics. Since R*(= 2) represents the expectation of R0 in a homogeneously mixed population of infinite size, the difference between R0 and R* can be attributed to the effects of social fluidity and population size. Because the association between φ and R0 is strong (shown in Figure 4A), the relationship between each of the other metrics and R0 is qualitatively the same as the their relationship with φ. Consequently, R0 tends to be smaller in the largest populations (Figure 4B), suggesting that population size is not an important variable at such low values of φ. For φ > 1, however, analytical results suggest that N plays a larger role in determining R0 (Figure S3).
The relative weakness of the correlation between mean degree and R0 (Figure 4C) suggests that the interaction dynamics taking place on each edge contribute significantly to the disease outcomes. For example, after transmission has occurred from one individual to another, repeats of the same interaction serve no advantage for the disease (most directly-transmitted infections are not dose-dependent). Since a large edge weight implies a high frequency of repeated interactions, networks with a higher mean weight tend to have lower values of R0 (Figure 4D). Furthermore, heterogeneity in the distribution of weights concentrates a yet larger proportion of interactions onto a small number of edges, thus causing more repeat interactions and reducing R0 (Figure 4E).
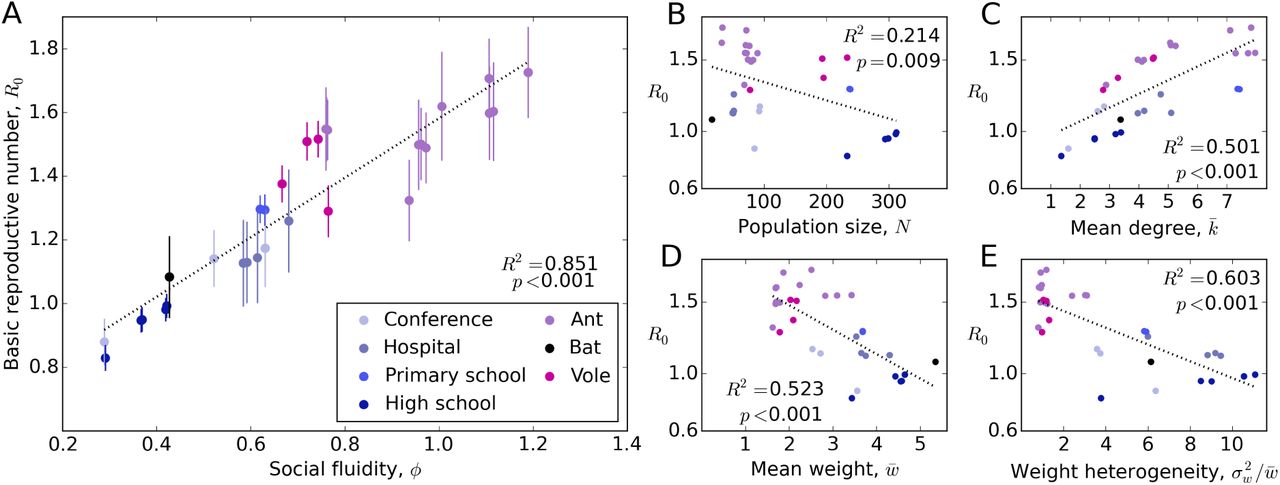
Each point represents a human or animal data-set for which the time of interactions appear in the data. For each individual, i, in a population, the mean number of secondary infections is obtained from simulation and the mean, R0 (± one standard error in part A), is plotted against metrics of social structure. Note that the parameters in the disease simulation have been calibrated with the rate of activity of each system to make these metrics comparable.
Discussion
We have defined a measure of fluidity in social behavior which quantifies how much mixing exists within the social relationships of a population. While social networks can be measured with a variety of metrics including size, connectivity, interaction heterogeneity and frequency, our methodology succeeds in reducing all such factors to a single quantity allowing comparisons across a range of human and animal social systems. Social fluidity correlates with both the density of social ties (mean degree) and the heterogeneity in the strength of those ties, yet they are not correlated with each other; this implies that social fluidity combines two distinct elements of social network analysis. We have also shown that this metric is a better predictor of R0 than these other network metrics.
By measuring social fluidity across a range of human and animal systems we are able to rank social behaviors. In particular, we identify aggressive interactions as the most socially fluid; this indicates a possible learning effect whereby each aggressive encounter is followed by a period for which individuals avoid further aggression with each other [43]. At the opposite end of the scale, we find interactions that strengthen bonds (and thus require repeated interactions) such as grooming in monkeys [44] and food-sharing in bats [26]. The fact that food-sharing ants are far more fluid than bats, despite performing the same kind of interaction, reflects their eusocial nature and the absence of any need to maintain long-lasting bonds with their kin [45].
Most studies that aim to describe and quantify social structure are met with a number of challenges. The degree of an individual, for example, is known to scale with the length of the observation period [46]. By focusing not on the absolute value of degree, and instead focusing on how degree scales with the number of observations, our analysis controls for this bias. As with other network measures, however, social fluidity estimates lose reliability when only a sample of the group has been observed [47]. Another hurdle in previous work has been the assumption that observed interactions will persist into the future [48]. Our method assumes only that the distribution of relationships remains constant through time, an assumption that is consistent with growing evidence [19, 49].
In trying to elucidate the connection between social behaviors and the spread of disease the first question to ask is whether the type of interactive behavior that the species participates in enables transmission of the infection. If it does, then the next important variable is the frequency of these interactions. Beyond this, other proposed influences include the number of social ties [50], which we have shown to be less significant than social fluidity; modularity, which has previously been exposed as an unreliable predictor of disease outcomes [51]; and group size [52], which we have shown to only be relevant in highly fluid populations.
The relative significance of social fluidity becomes apparent when we compare the largest human face-to-face interaction system (highschool_0 in Tables S2 and S3 N = 312, R0 = 0:99, φ = 0:422), to the smallest (hospital_1, N = 49, R0 = 1.129, φ = 0.592). Despite the former containing more than 6 times as many individuals as the latter, its lower social fluidity causes R0 to be a smaller. Similarly, the mean degree of the hospital data ( = 5.1) is more than double that of the first day of the conference (conference_0,
= 5.1) is more than double that of the first day of the conference (conference_0,  = 2.5, R0 = 0.173, φ = 0.631), yet the relatively small decrease in φ is enough to reduce the value of R0. Thus, the risks associated with minor changes in the way individuals choose to distribute their social effort. If the survival of a group depends on its size or its connectivity then this social adaptation can be made with little impact on the disease risks.
= 2.5, R0 = 0.173, φ = 0.631), yet the relatively small decrease in φ is enough to reduce the value of R0. Thus, the risks associated with minor changes in the way individuals choose to distribute their social effort. If the survival of a group depends on its size or its connectivity then this social adaptation can be made with little impact on the disease risks.
Although social fluidity predicts the basic reproductive number R0 better than alternative network-based metrics, this does not necessarily imply that it would be a good predictor of the final epidemic size in a population with higher-order social structure (e.g. clustering, degree heterogeneity) [53]. Even so, there are implications of this work that may improve the way epidemics are modeled. The growing evidence that human and animal interaction follows basic universal principals, such as constraints on the social capacity of an individual, ought to be encoded into infectious disease models that aim to achieve a coupling of social and disease dynamics [54, 55].
Unlike previous work that explores the disease consequences of population mixing [56, 20], our analysis allows us to compare its effect across a range of social systems. We see, for example, the relationship between mixing and how disease risks scale with population size. For social systems that have high values of social fluidity, R0 is highly sensitive to changes in N, whereas this sensitivity is not present at low values of φ. Thus, both density dependent and frequency dependent disease dynamics are realized through the same model. Since many empirical studies support a transmission function that is somewhere between these two modeling paradigms [57, 58, 59], the modeling approaches applied in this study may be useful in informing transmission relationships in future disease studies.
Materials and Methods
Extended methods are provided in the SI Text
A. Computing the lower bound in (2)
The value of ∈ is determined by the choice of φ and the value of N. Since interactions are pairwise, when i interacts exactly one other individual is involved. Thus, the sum of the xj|i’s over all other members of the population, j, is equal to 1. We choose to express this as a constraint in expectation, with (N– 1) 〈x〉 = 1, where 〈x〉 denotes the mean of the distribution ρ(x). This leads to

We can therefore find ∈ for any give N and φ by solving (C + 1)∈φ ∈ − C = 0, where C = (1 −φ)/(N− 1)φ, using the fsolve function from the scipy.optimize Python library (SI text).
B. Conditional degree distribution
The degree of i is determined by N − 1 independent Bernoulli trials, each with success probability Ψ(si). The probability that an individual will have degree k given that they have interacted s times, for any value of the global parameter φ is therefore given by

However, since this distribution gives non-zero probabilities for cases where k > s, which are invalid, we instead use
 when if 0 < s < N. To evaluate the hypergeometric function in (3) we used the hyp2f1 function from the scipy.special Python library.
when if 0 < s < N. To evaluate the hypergeometric function in (3) we used the hyp2f1 function from the scipy.special Python library.
C. Parameter estimation
For each individual in a study population we know the number of times they interacted, si, and the number of partners with whom they interacted, ki, in vector notation k = {k1, k2, …, kN} and s = {s1, s2, …, sN. The marginal log-likelihood function is

We then compute the maximum likely estimate φ = argmaxφ  . Our estimation is based on the marginal distribution of the degree of each node and does not take into account the interdependencies of the network structure. As such, we do not report standard errors or confidence intervals for our point estimates. For discussion of the use of marginal distributions in likelihood estimation see [60].
. Our estimation is based on the marginal distribution of the degree of each node and does not take into account the interdependencies of the network structure. As such, we do not report standard errors or confidence intervals for our point estimates. For discussion of the use of marginal distributions in likelihood estimation see [60].
The goodness-of-fit is calculated by comparing its likelihood to the likelihood of a null model in which the degree of each individual is a uniformly distributed random integer within the range of feasible values (SI Text).
D. Disease model calibration
We choose γ for every system such that R0 is equal to a fixed value, R∗, under the assumption of no effect from social fluidity and population size (i.e. in a large population with homogeneous mixing). Calibration is achieved when γ is chosen to be
 where ∆t is the duration of the time-frame of the data and 〈s〉 is the mean of si over the whole population. The effect of this calibration is that the recovery rate, γ, is proportional to the mean activity rate.
where ∆t is the duration of the time-frame of the data and 〈s〉 is the mean of si over the whole population. The effect of this calibration is that the recovery rate, γ, is proportional to the mean activity rate.
E. Disease simulation
Disease simulations were only performed on data for which the time of every interaction is recorded. Since the transmission probability, β, and the rate of recovery, γ, are calibrated through (11), the choice of β does not affect R0. We arbitrarily chose β = 1/4. We report mean absolute error |e|, which is the mean difference between the analytical and simulated values of r(si), computed across 103 simulations for each node. An extensive description is provided in the supplement (SI Text).
Acknowledgments
This work was supported by NSF grant number 1414296. We are grateful for insightful feedback from Pratha Sah. We also thank all the researchers who have made their behavioral data openly accessible, making this study possible.
Footnotes
↵* ec975{at}georgetown.edu
↵1 xj|i are subject to network interdependencies. Specifically, AX = XT A and X1 = 0, where X is a matrix whose i, j entry is 1 if i = j and xj|i otherwise, A is any diagonal matrix with positive entries, and 0 and 1 are column vectors of length N containing only 0 and 1, respectively. Thus, ρ(x) is the distribution of marginal xj|i values of the joint distribution P (X).
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵





{kind=link}
{kind=link}
{kind=link}
{kind=link}