

Abstract
Throughout history, the life sciences have been revolutionised by technological advances; in our era this is manifested by advances in instrumentation for data generation, and consequently researchers now routinely handle large amounts of heterogeneous data in digital formats. The simultaneous transitions towards biology as a data science and towards a ‘life cycle’ view of research data pose new challenges. Researchers face a bewildering landscape of data management requirements, recommendations and regulations, without necessarily being able to access data management training or possessing a clear understanding of practical approaches that can assist in data management in their particular research domain.
Here we provide an overview of best practice data life cycle approaches for researchers in the life sciences/bioinformatics space with a particular focus on ‘omics’ datasets and computer-based data processing and analysis. We discuss the different stages of the data life cycle and provide practical suggestions for useful tools and resources to improve data management practices.
Introduction
Technological data production capacity is revolutionising biology [1] but is not necessarily correlated with the ability to efficiently analyse and integrate data, or with enabling long-term data sharing and reuse. There are selfish as well as altruistic benefits to making research data reusable [2]: it allows one to find and reuse one’s own previously-generated data easily; it is associated with higher citation rates [3,4]; and it ensures eligibility for funding from and publication in venues that mandate data sharing, an increasingly common requirement [e.g. 5,6,7]. Currently we are losing data at a rapid rate, with up to 80% unavailable after 20 years [8]. This affects reproducibility - assessing the robustness of scientific conclusions by ensuring experiments and findings can be reproduced - which underpins the scientific method. Once access to the underlying data is lost, replicability, reproducibility and extensibility [9] are reduced.
At a broader societal level, the full value of research data may go beyond the initial use case in unforeseen ways [10,11], so ensuring data quality and reusability is crucial to realising its potential value [12–15]. The recent publication of the FAIR principles [12,16] identifies four key criteria for high-quality research data: the data should be Findable, Accessible, Interoperable and Reusable. Whereas a traditional view of data focuses on collecting, processing, analysing data and publishing results only, a life cycle view reveals the additional importance of finding, storing and sharing data [14]. Throughout this article we present a researcher-focused data life cycle framework that has commonalities with other published frameworks [14,17–20] but is aimed at life science researchers specifically (Fig. 1).
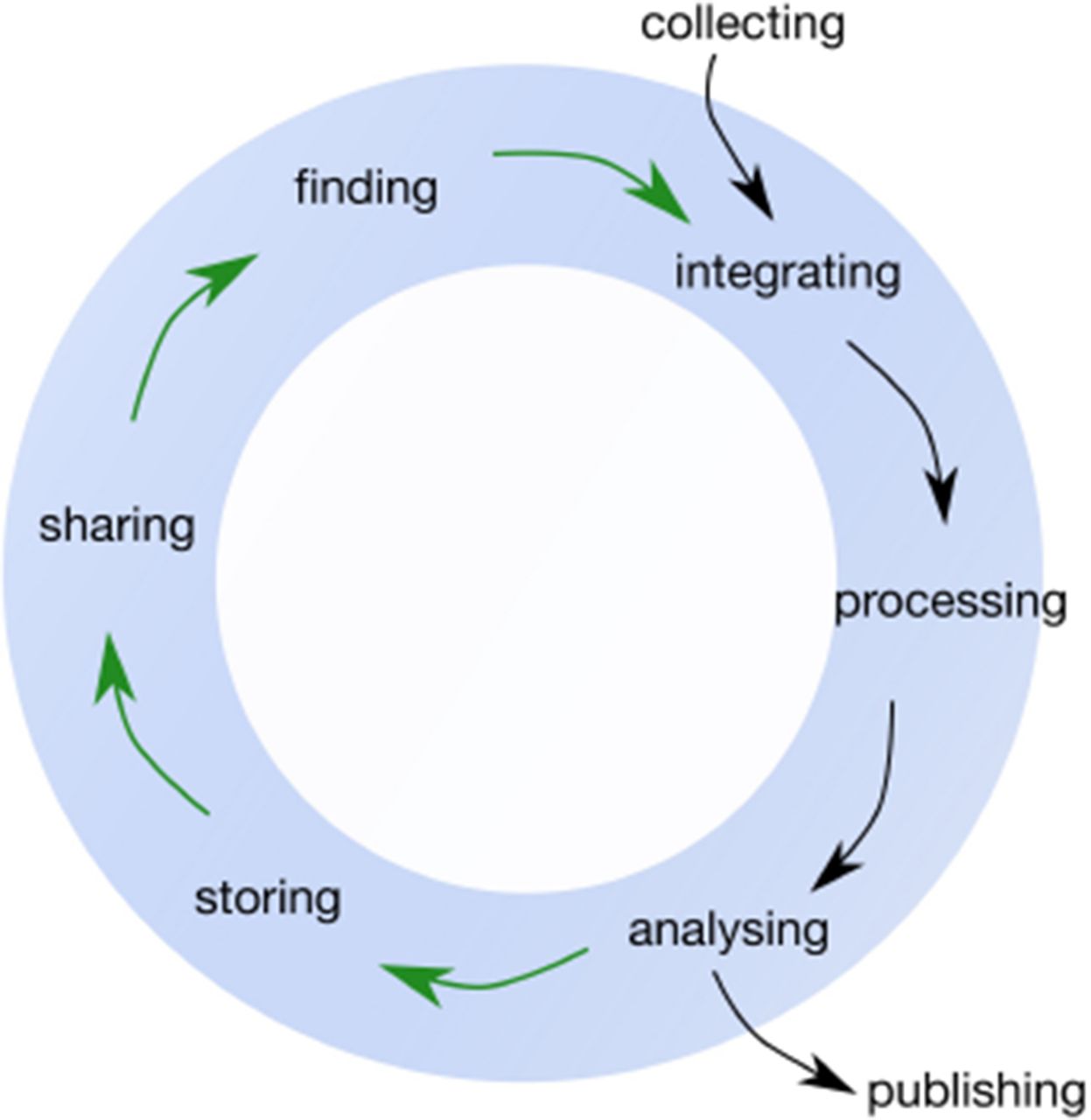
The Data Life Cycle framework for bioscience, biomedical and bioinformatics data that is discussed throughout this article. Black arrows indicate the ‘traditional’, linear view of research data; the green arrows show the steps necessary for data reusability. This framework is likely to be a simplified representation of any given research project, and in practice there would be numerous ‘feedback loops’ and revisiting of previous stages. In addition, the publishing stage can occur at several points in the data life cycle.
Learning how to find, store and share research data is not typically an explicit part of undergraduate or postgraduate training in the biological sciences [21–23]. The scope, size and complexity of datasets in many fields has increased dramatically over the last 10-20 years but the knowledge of how to manage this data is currently limited to specific cohorts of ‘information managers’ (e.g. research data managers, research librarians, database curators and IT professionals with expertise in databases and data schemas [23]). In response to institutional and funding requirements around data availability, a number of tools and educational programs have been developed to help researchers create Data Management Plans to address elements of the data lifecycle [24]; however, even when a plan is mandated, there is often a gap between the plan and the actions of the researcher [13].
During the week of 24-28 October 2016, EMBL Australia Bioinformatics Resource (EMBL- ABR) [25] led workshops on the data life cycle for life science researchers working in the plant, animal, microbial and medical domains. The workshops provided opportunities to (i) map the current approaches to the data life cycle in biology and bioinformatics, and (ii) present and discuss best practice approaches and standards for key international projects with Australian life scientists and bioinformaticians. Discussions during these workshops have informed this publication, which targets life science researchers wanting to improve their data management practice; throughout we highlight some specific data management challenges mentioned by participants.
Finding Data
In biology, research data is frequently published as supplementary material to articles, on personal or institutional websites, or in non-discipline-specific repositories like Figshare [26] and Dryad [27,28]. In such cases, data may exist behind a paywall, there is no guarantee it will remain extant, and, unless one already knows it exists and its exact location, it may remain undiscovered [29]. It is only when a dataset is added to public data repositories, along with accompanying standardized descriptive metadata (see Collecting Data), that it can be indexed and made publicly available [30]. Data repositories also provide unique identifiers that increase findability by enabling persistent linking from other locations and permanent association between data and its metadata.
In the field of molecular biology, a number of bioinformatics-relevant organisations host public data repositories. National and international-level organisations of this kind include the European Bioinformatics Institute (EMBL-EBI) [31], the National Centre for Biotechnology Information (NCBI) [32], the DNA Data Bank of Japan (DDBJ) [33], the Swiss Institute of Bioinformatics (SIB) [34], and the four data center members of the worldwide Protein Data Bank [35], which mirror their shared data with regular, frequent updates. This shared central infrastructure is hugely valuable to research and development. For example, EMBL-EBI resources have been valued at over £270 million per year and contribute to ~£1 billion in research efficiencies; a 20-fold return on investment [36].
Numerous repositories are available for biological data (see Table 1 for an overview), though repositories are still lacking for some data types and sub-domains [37]. Many specialised data repositories exist outside of the shared central infrastructure mentioned, often run voluntarily or with minimal funding. Support for biocuration, hosting and maintenance of these smaller-scale but key resources is a pressing problem [38–40]. The quality of the user-submitted data in public repositories [41,42] can mean that public datasets require extra curation before reuse. Unfortunately, due to low uptake of established methods [43–45] to correct the data [42], the results of extra curation may not find their way back into the repositories. Repositories are often not easily searched by generic web search engines [37]. Registries, which form a secondary layer linking multiple, primary repositories, may offer a more convenient way to search across multiple repositories for data relevant to a researcher’s topics of interest [46].
Overview of some representative databases, registries and other tools to find life science data
Collecting Data
The most useful data has associated information about its creation, its content and its context - called metadata [47]. If metadata is well structured, uses consistent element names and contains element values with specific descriptions from agreed-upon vocabularies, it enables machine readability, aggregation, integration and tracking across datasets: allowing for Findability, Interoperability and Reusability [12,37]. One key approach in best-practice metadata collection is to use controlled vocabularies built from ontology terms. Biological ontologies are tools that provide machine-interpretable representations of some aspect of biological reality [37,48]. They are a way of organising and defining objects (i.e. physical entities or processes), and the relationships between them. Sourcing metadata element values from ontologies ensures that the terms used in metadata are consistent and clearly defined. There are several user-friendly tools available to assist researchers in accessing, using and contributing to ontologies (Table 2).
Useful ontology tools to assist in metadata collection
Adopting standard data and metadata formats and syntax is critical for compliance with FAIR principles [12,30,37,46,49]. Biological and biomedical research has been considered an especially challenging research field in this regard, as datatypes are extremely heterogeneous and not all have defined data standards [49,50]; many existing data standards are complex and therefore difficult to use [50], or only informally defined, and therefore subject to variation, misrepresentation, and divergence over time [49]. Nevertheless, well-established standards exist for a variety of biological data types (Table 3). BioSharing [51] is a useful registry of data standards and policies that also indicates the current status of standards for different data types and those recommended by databases and research organisations [46].
Overview of common standard data formats for ‘omics data
Most public repositories for biological data (see Table 1 and Storing Data section) require that minimum metadata be submitted accompanying each dataset (Table 4). This minimum metadata specification typically has broad community input [54]. Minimum metadata standards may not include the crucial metadata fields that give the full context of the particular research project [54], so it is important to gather metadata early, understand how to extend a minimum metadata template to include additional fields in a structured way, and think carefully about all the relevant pieces of metadata information that might be required for reuse.
Some community-designed minimum information criteria for metadata specifications in life sciences
Processing & Analysing Data
Recording and reporting how research data is processed and analysed computationally is crucial for reproducibility and assessment of research quality [1,55]. Full reproducibility requires access to the software, software versions, dependencies and operating system used as well as the data and software code itself [56]. Therefore, although computational work is often seen as enabling reproducibility in the short term, in the long term it is fragile and reproducibility is limited [57–59]. Best-practice approaches for preserving data processing and analysis code involve hosting source code in a repository where it receives a unique identifier and is under version control; where it is open, accessible, interoperable and reusable - broadly mapping to the FAIR principles for data. Github [60] and Bitbucket [61], for example, fulfil these criteria, and Zenodo additionally generates Digital Object Identifiers (DOIs) for submissions and guarantees long-term archiving [62]. Several recent publications have suggested ways to improve current practice in research software development [20,63–65].
The same points hold for wet-lab data production: for full reproducibility, it is important to capture and enable access to specimen cell lines, tissue samples and/or DNA as well as reagents. Wet-lab methods can be captured in electronic laboratory notebooks and reported in the Biosamples database [66], protocols.io [67] or OpenWetWare [68]; specimens can be lodged in biobanks, culture or museum collections [69–73]; but the effort involved in enabling full reproducibility remains extensive. Electronic laboratory notebooks are frequently suggested as a sensible way to make this information openly available and archived [74]. Some partial solutions exist [e.g. 75,76–78], including tools for specific domains such as the Scratchpad Virtual Research Environment for natural history research [79]. Other tools can act as or be combined to produce notebooks for small standalone code-based projects [80,81], including Jupyter Notebook [e.g. 82], Rmarkdown [83], and Docker [84]. However, it remains a challenge to implement online laboratory notebooks to cover both field/lab work and computer-based work, especially when computer work is extensive, involved and non-modular [55]. Currently, no best-practice guidelines or minimum information standards exist for use of electronic laboratory notebooks [9]. We suggest that appropriate minimum information to be recorded for most computer-based tasks should include date, task name and brief description, aim, actual command(s) used, software names and versions used, input/output file names and locations, script names and locations.
During the EMBL-ABR workshop series, participants identified the data processing and analysis stage as one of the most challenging for openness. A few participants had put intensive individual effort into developing custom online lab (and code) notebook approaches but the majority had little awareness of this as a useful goal. This suggests a gap between modern biological research as a field of data science, and biology as it is still mostly taught in undergraduate courses, with little or no focus on computational analysis, or project or data management. As reported elsewhere [21–23], this gap has left researchers lacking key knowledge and skills required to implement best practices in dealing with the life cycle of their data.
Publishing Data
Traditionally, scientific publications included raw research data, but in recent times datasets have grown beyond the scope of practical inclusion in a manuscript [14,55]. Selected data outputs are often included without sharing or publishing the underlying raw data [19]. Journals increasingly recommend or require deposition of raw data in a public repository [e.g. 85], although exceptions have been made for publications containing commercially-relevant data [86]. The current data-sharing mandate is somewhat field-dependent [8,87] and also varies within fields [88]. For example, in the field of bioinformatics, the UPSIDE principle [89] is referred to by some journals (e.g. Bioinformatics [90]), while others have journal- or publisher-specific policies (e.g. BMC Bioinformatics [91]).
The vast majority of scientific journals require inclusion of processing and analysis methods in ‘sufficient detail for reproduction’ [e.g. 92,93–97], though journal requirements are diverse and complex [98], and the level of detail authors provide can vary greatly in practice [99,100]. More recently, many authors have highlighted that full reproducibility requires sharing data and resources at all stages of the scientific process, from raw data (including biological samples) to full methods and analysis workflows [1,9,72,100]. This remains a challenge however [101,102], as discussed in the Processing and Analysing Data section. To our knowledge, strategies for enabling computational reproducibility are currently not mandated by any scientific journal.
A recent development in the field of scientific publishing is the establishment of ‘data journals’: scientific journals that publish papers describing datasets. This gives authors a vehicle to accrue citations (still a dominant metric of academic impact) for data production alone, which can often be labour-intensive and expensive yet is typically not well recognised under the traditional publishing model. Examples of this article type include the Data Descriptor in Scientific Data [103] and the Data Note in GigaScience [104], which do not include detailed new analysis but rather focus on describing and enabling reuse of datasets.
The movement towards sharing research publications themselves (‘Open Access Publishing’) has been discussed extensively elsewhere [e.g. 29,105,106]. Publications have associated metadata [creator, date, title etc.; 107] and unique identifiers (PubMed ID for biomedical and some life science journals, DOIs for the vast majority of journals; see Table 5). The ORCID system [108] enables researchers to claim their own unique identifier, which can be linked to their publications. The use of unique identifiers within publications referring to repository records (e.g. genes, proteins, chemical entities) is not generally mandated by journals [e.g. 109], although it would ensure a common vocabulary is used and so make scientific results more interoperable and reusable [110]. Some efforts are underway to make this easier for researchers: for example, Genetics and other Genetics Society of America journals assist authors in linking gene names to model organism database entries [111].
Identifiers throughout the data life cycle
Storing Data
While primary data archives are the best location for raw data and some downstream data outputs (Table 1), researchers also need local data storage solutions during the processing and analysis stages. Data storage requirements vary among research domains, with major challenges often evident for groups working on taxa with large genomes (e.g. crop plants), which require large storage resources, or on human data, where privacy regulations may require local data storage, access controls and conversion to non-identifiable data if data is to be shared [112–114]. In addition, long-term preservation of research data should consider threats such as storage failure, mistaken erasure, bit rot, outdated media, outdated formats, loss of context and organisational failure [115].
Sharing Data
The best-practice approach to sharing biological data is to deposit it (with associated metadata) in a primary archive suitable for that datatype [11] that complies with FAIR principles. As highlighted in the Storing Data section, these archives assure both data storage and public sharing as their core mission, making them the most reliable location for long-term data storage. Alternative data sharing venues (e.g. FigShare, Dryad) do not require or implement specific metadata or data standards. This means that while these venues have a low barrier to entry for submitters, the data is not FAIR unless submitters have independently decided to comply with more stringent criteria. If available, an institutional repository may be a good option if there is no suitable archive for that datatype. Importantly, plans for data sharing should be made at the start of a research project and reviewed during the project, to ensure ethical approval is in place and that the resources and metadata needed for effective sharing are available at earlier stages of the data life cycle [3].
During the EMBL-ABR workshop series, the majority of participants were familiar with at least some public primary data repositories, and many had submitted data to them previously. A common complaint was around usability of current data submission tools and a lack of transparency around metadata requirements and the rationale for them. A few workshop participants raised specific issues about the potential limitations of public data repositories where their data departed from the assumptions of the repository (e.g. unusual gene models supported by experimental evidence that were rejected by the automated NCBI curation system). Most workshop participants were unaware they could provide feedback to the repositories to deal with such situations, and this could also be made clearer on the repository websites. Again, this points in part to existing limitations in the undergraduate and postgraduate training received by researchers, where the concepts presented in this article are presented as afterthoughts, if at all. On the repository side, while there is a lot of useful information and training material available to guide researchers through the submission process [e.g. the EMBL-EBI Train Online webinars and online training modules, 116], it is not always linked clearly from the database portals or submission pages themselves. Similarly, while there are specifications and standards available for many kinds of metadata [Table 4; also see 51], many do not have example templates available, which would assist researchers in implementing the standards in practice.
What can the research community do to encourage best-practice?
We believe that the biological/biomedical community and individual researchers have a responsibility to the public to help advance knowledge by making research data FAIR for reuse [12], especially if the data were generated using public funding. There are several steps that can assist in this mission:
Senior scientists should lead by example and ensure all the data generated by their laboratories is well-managed, fully annotated with the appropriate metadata and made publicly available in an appropriate repository.
The importance of data management and benefits of data reuse should be taught at the undergraduate and postgraduate levels [23]. Computational biology and bioinformatics courses in particular should include material about data repositories, data and metadata standards, data discovery and access strategies. Material should be domain-specific enough for students to attain learning outcomes directly relevant to their research field.
Funding bodies are already taking a lead role in this area by requiring the incorporation of a data management plan into grant applications. A next step would be for a formal check, at the end of the grant period, that this plan has been adhered to and data is available in an appropriate format for reuse [13].
Funding bodies and research institutions should judge quality dataset generation as a valued metric when evaluating grant or promotion applications.
Similarly, leadership and participation in community efforts in data and metadata standards, and open software and workflow development should be recognised as academic outputs.
Data repositories should ensure that the data deposition and third-party annotation processes are as FAIR and painless as possible to the naive researcher, without the need for extensive bioinformatics support [42].
Journals should require editors and reviewers to check manuscripts to ensure that all data, including research software code and samples where appropriate, have been made publicly available in an appropriate repository, and that methods have been described in enough detail to allow re-use and meaningful reanalysis [11].
Finally, researchers reusing any data should openly acknowledge this fact and fully cite the dataset, including unique identifiers [11,13,37].
Conclusions
While the concept of a life cycle for research data is appealing from an Open Science perspective, challenges remain for life science researchers to put this into practice. During the EMBL-ABR Data Life Cycle workshop series, we noted limited awareness among attendees of the resources available to researchers that assist in finding, collecting, processing, analysis, publishing, storing and sharing FAIR data. We believe this manuscript provides a useful overview of the relevant concepts and an introduction to key organisations, resources and guidelines to help researchers improve their data management practices.
Furthermore, we note that data management in the era of biology as a data science is a complex and evolving topic and both best practices and challenges are highly domain-specific, even within the life sciences. This factor may not always be appreciated at the organisational level, but has major practical implications for the quality and interoperability of shared life science data. Finally, domain-specific education and training in data management would be of great value to the life science research workforce, and we note an existing gap at the undergraduate, postgraduate and short course level in this area.
Competing Interests
No competing interests were identified.
Acknowledgements
The authors thank Dan Bolser for his involvement in the EMBL-ABR Data Life Cycle workshops, and all workshop participants for sharing their experiences and useful discussions.
References
- 1.↵
- 2.↵
- 3.↵
- 4.↵
- 5.↵
- 6.↵
- 7.↵
- 8.↵
- 9.↵
- 10.↵
- 11.↵
- 12.↵
- 13.↵
- 14.↵
- 15.↵
- 16.↵
- 17.↵
- 18.
- 19.↵
- 20.↵
- 21.↵
- 22.
- 23.↵
- 24.↵
- 25.↵
- 26.↵
- 27.↵
- 28.↵
- 29.↵
- 30.↵
- 31.↵
- 32.↵
- 33.↵
- 34.↵
- 35.↵
- 36.↵
- 37.↵
- 38.↵
- 39.
- 40.↵
- 41.↵
- 42.↵
- 43.↵
- 44.
- 45.↵
- 46.↵
- 47.↵
- 48.↵
- 49.↵
- 50.↵
- 51.↵
- 52.
- 53.
- 54.↵
- 55.↵
- 56.↵
- 57.↵
- 58.
- 59.↵
- 60.↵
- 61.↵
- 62.↵
- 63.↵
- 64.
- 65.↵
- 66.↵
- 67.↵
- 68.↵
- 69.↵
- 70.
- 71.
- 72.↵
- 73.↵
- 74.↵
- 75.↵
- 76.↵
- 77.
- 78.↵
- 79.↵
- 80.↵
- 81.↵
- 82.↵
- 83.↵
- 84.↵
- 85.↵
- 86.↵
- 87.↵
- 88.↵
- 89.↵
- 90.↵
- 91.↵
- 92.↵
- 93.↵
- 94.
- 95.
- 96.
- 97.↵
- 98.↵
- 99.↵
- 100.↵
- 101.↵
- 102.↵
- 103.↵
- 104.↵
- 105.↵
- 106.↵
- 107.↵
- 108.↵
- 109.↵
- 110.↵
- 111.↵
- 112.↵
- 113.
- 114.↵
- 115.↵
- 116.↵





{kind=link}