

Abstract
The emergence of large-scale genomic, chemical and pharmacological data provides new opportunities for drug discovery and repositioning. Systematic integration of these heterogeneous data not only serves as a promising tool for identifying new drug-target interactions (DTIs), which is an important step in drug development, but also provides a more complete understanding of the molecular mechanisms of drug action. In this work, we integrate diverse drug-related information, including drugs, proteins, diseases and side-effects, together with their interactions, associations or similarities, to construct a heterogeneous network with 12,015 nodes and 1,895,445 edges. We then develop a new computational pipeline, called DTINet, to predict novel drug-target interactions from the constructed heterogeneous network. Specifically, DTINet focuses on learning a low-dimensional vector representation of features for each node, which accurately explains the topological properties of individual nodes in the heterogeneous network, and then predicts the likelihood of a new DTI based on these representations via a vector space projection scheme. DTINet achieves substantial performance improvement over other state-of-the-art methods for DTI prediction. Moreover, we have experimentally validated the novel interactions between three drugs and the cyclooxygenase (COX) protein family predicted by DTINet, and demonstrated the new potential applications of these identified COX inhibitors in preventing inflammatory diseases. These results indicate that DTINet can provide a practically useful tool for integrating heterogeneous information to predict new drug-target interactions and repurpose existing drugs. The source code of DTINet and the input heterogeneous network data can be downloaded from http://github.com/luoyunan/DTINet.
1 Introduction
Computational prediction of drug-target interactions (DTIs) has become an important step in the drug discovery or repositioning process, aiming to identify putative new drugs or novel targets for existing drugs. Compared to in vivo or biochemical experimental methods for identifying new DTIs, which can be extremely costly and time-consuming [73], in silico or computational approaches can efficiently identify potential DTI candidates for guiding in vivo validation, and thus significantly reduce the time and cost required for drug discovery or repositioning. Traditional computational methods mainly depend on two strategies, including the molecular docking-based approaches [11, 17, 42] and the ligand-based approaches [29, 30]. However, the performance of molecular docking is limited when the 3D structures of target proteins are not available, while the ligand-based approaches often lead to poor prediction results when a target has only a small number of known binding ligands.
In the past decade, much effort has been devoted to developing the machine learning based approaches for computational DTI prediction. A key idea behind these methods is the “guilt-by-association” assumption, that is, similar drugs may share similar targets and vice versa. Based on this intuition, the DTI prediction problem is often formulated as a binary classification task, which aims to predict whether a drug-target interaction is present or not. A straightforward classification based approach is to consider known DTIs as labels and incorporate chemical structures of drugs and primary sequences of targets as input features (or kernels). Most existing prediction methods mainly focus on exploiting information from homogeneous networks. For example, Bleakley and Yamanishi [5] applied a support vector machine (SVM) framework to predict DTIs based on a bipartite local model (BLM). Mei et al. [39] extended this framework by combining BLM with a neighbor-based interaction-profile inferring (NII) procedure (called BLMNII), which is able to learn the DTI features from neighbors and predict interactions for new drug or target candidates. Xia et al. [76] proposed a semi-supervised learning method for DTI prediction, called NetLapRLS, which applies Laplacian regularized least square and incorporates both similarity and interaction kernels into the prediction framework. van Laarhoven et al. introduced a Gaussian interaction profile (GIP) kernel based approach coupled with regularized least square (RLS) for DTI prediction [66, 65]. Rather than regarding a drug-target interaction as a binary indicator, Wang and Zeng [71] proposed a restricted Boltzmann machine (RBM) model to predict different types of DTIs (e.g., activation and inhibition) on a multidimensional network.
In addition to chemical and genomic data, previous works have incorporated pharmacological or phenotypic information, such as side-effect [7, 41], transcriptional response data [24], drug-disease associations [70], public gene expression data [18, 53] and functional data [77] for DTI prediction. Heterogeneous data sources provide diverse information and a multi-view perspective for predicting novel DTIs. For instance, the therapeutic effects of drugs on diseases can generally reflect their binding activities to the targets (proteins) that are related to these diseases and thus can also contribute to DTI prediction. Therefore, incorporating heterogeneous data sources, e.g., drug-disease associations, can potentially boost the accuracy of DTI prediction and provide new insights into drug repositioning. Despite the current availability of heterogeneous data, most existing methods for DTI prediction are limited to only homogeneous networks or a bipartite DTI models, and cannot be directly extended to take into account heterogeneous node or topological information and complex relations among different data sources.
Recently, several computational strategies have been introduced to integrate heterogeneous data sources to predict DTIs. A network-based approach for this purpose is to fuse heterogeneous information through a network diffusion process, and directly use the obtained diffusion distributions to derive the prediction scores of DTIs [70, 10]. A meta-path based approach has also been proposed to extract the semantic features of DTIs from heterogeneous networks [20]. A collaborative matrix factorization has been developed to project the heterogeneous networks into a common feature space, which enables one to use the aforementioned homogeneous network based methods to predict new DTIs from the resulting single integrated network [79]. However, these approaches generally fail to provide satisfactory integration paradigms. First, directly using the diffusion states as the features or prediction scores may easily suffer from the bias induced by the noise and high-dimensionality of biological data and thus possibly lead to inaccurate DTI predictions. In addition, the hand-engineered features, such as meta-paths, often require expert knowledge and intensive effort in feature engineering, and hence prevent the prediction methods from being scaled to large-scale datasets. Moreover, collapsing multiple individual networks into a single network may cause substantial loss of network-specific information, since edges from multiple data sources are mixed without distinction in such an integrated network.
In this paper, we present DTINet, a novel network integration pipeline for DTI prediction. DTINet not only integrates diverse information from heterogeneous data sources (e.g., drugs, proteins, diseases and side-effects), but also copes with the noisy, incomplete and high-dimensional nature of large-scale biological data by learning low-dimensional but informative vector representations of features for both drugs and proteins. The low-dimensional feature vectors learned by DTINet capture the context information of individual networks, as well as the topological properties of nodes (e.g., drugs or proteins) across multiple networks. Based on these low-dimensional feature vectors, DTINet then finds an optimal projection from drug space onto target space, which enables the prediction of new DTIs according to the geometric proximity of the mapped vectors in a unified space. We have demonstrated the integration capacity of DTINet by unifying multiple networks that are related to drugs and proteins, and shown that incorporating additional network information can significantly improve the prediction accuracy. In addition, through comprehensive tests, we have demonstrated that DTINet can achieve substantial performance improvement over other state-of-the-art prediction methods. Furthermore, we have experimentally validated the new interactions predicted by DTINet between three drugs and the cyclooxygenase (COX) protein family that have not been reported in the literature (to the best of our knowledge) and have demonstrated the potential novel applications of these drugs in preventing inflammatory diseases.
With superior prediction performance, DTINet offers a practically useful tool to predict unknown drug-target interactions from complex heterogeneous networks, which can provide new insights into drug discovery or repositioning and the understanding of mechanisms of drug action. Overall, we feature the following major advancements of DTINet: (i) the generalizability and scalability of integrating a variety of heterogeneous data sources; (ii) the ease of automated compact feature learning without any hand-engineered feature extraction or domain-specific expert knowledge; (iii) the ability of addressing the computational challenges in network integration arising from the high-dimensional, incomplete and noisy biological data; (iv) the high prediction accuracy and substantial performance improvement over previous methods; and (v) the novel predicted drug-target interactions that have been validated experimentally.
2 Methods
As an overview (Figure 1), DTINet integrates diverse information from heterogeneous network by first combining the network diffusion algorithm (random walk with restart, RWR [60]) and a dimensionality reduction scheme (diffusion component analysis, DCA [12]), to obtain informative, but low dimensional vector representations of nodes in the network. We call this process as compact feature learning. Intuitively, the low-dimensional feature vector obtained from this process encodes the relational properties (e.g., similarity), association information and topological context of each drug (or protein) node in the heterogeneous network. Next, DTINet finds the best projection from drug space onto protein space, such that the mapped feature vectors of drugs are geometrically close to their known interacting targets. After that, DTINet infers new interactions for a drug by ranking its target candidates according to their proximity to the projected feature vector of this drug. A key insight of our approach is that the drugs (or proteins) with similar topological properties in the heterogeneous network are more likely to be functionally correlated. For example, those drugs that are close in the directions of their feature vectors are more likely to act on the same target, and vice versa. This intuition allows us to predict unknown drug-target interactions by fully exploiting our previous knowledge about known drug-target interactions.

The flowchart of the DTINet pipeline. DTINet first integrates a variety of drug-related information sources to construct a heterogeneous network and applies a compact feature learning algorithm to obtain a low-dimensional vector representation of the features describing the topological properties for each node. DTINet then finds the best projection from drug space onto protein space, such that the projected feature vectors of drugs are geometrically close to the feature vectors of their known interacting proteins. After that, DTINet infers new interactions for a drug by sorting its target candidates based on their geometric proximity to the projected feature vector of this drug in the projected space. The predicted new drug-target interactions can be further analyzed and experimentally validated.
2.1 Compact feature learning for drugs and targets
Random walk with restart revisited
The first step of DTINet is to perform a network diffusion algorithm to jointly integrate heterogeneous information. Random walk with restart (RWR), a network diffusion algorithm, has been extensively applied to analyze the complex biological network data [8, 33, 44, 35, 10]. Different from conventional random walk methods, RWR introduces a pre-defined restart probability at the initial node for every iteration, which can take into consideration both local and global topological connectivity patterns within the network to fully exploit the underlying direct or indirect relations between nodes. Formally, let A denote the weighted adjacency matrix of a molecular interaction network with n drugs (or targets). We also define another matrix B, in which each element Bi,j describes the probability of a transition from node i to node j, that is, Bi,j=Ai,j/Σ j′ Ai,j′. Next, let sit be an n-dimensional distribution vector in which each element stores the probability of a node being visited from node i after t iterations in the random walk process. Then RWR from node i can be defined as:
 where ei stands for an n-dimensional standard basis vector with ei(i) = 1 and ei (j) = 0, ∀j ≠ i, and pr stands for the pre-defined restart probability, which actually controls the relative influence between local and global topological information in the diffusion process, with higher values emphasizing more on the local structures in the network. At some fixed point of the iterating process, we can obtain a stationary distribution si∞ of RWR, which we refer to as the “diffusion state” si for node i (i.e., si = si∞), being consistent with the notation of previous work [12]. Intuitively, the jth element of diffusion state, denoted by sij, represents the probability of RWR starting node i and ending up at node j in equilibrium. When two nodes have similar diffusion states, it generally implies that they have similar positions with respect to other nodes in the network, and thus probably share similar functions. This insight provides the basis for several previous works [70, 10] that aim to predict unknown DTIs based on diffusion states.
where ei stands for an n-dimensional standard basis vector with ei(i) = 1 and ei (j) = 0, ∀j ≠ i, and pr stands for the pre-defined restart probability, which actually controls the relative influence between local and global topological information in the diffusion process, with higher values emphasizing more on the local structures in the network. At some fixed point of the iterating process, we can obtain a stationary distribution si∞ of RWR, which we refer to as the “diffusion state” si for node i (i.e., si = si∞), being consistent with the notation of previous work [12]. Intuitively, the jth element of diffusion state, denoted by sij, represents the probability of RWR starting node i and ending up at node j in equilibrium. When two nodes have similar diffusion states, it generally implies that they have similar positions with respect to other nodes in the network, and thus probably share similar functions. This insight provides the basis for several previous works [70, 10] that aim to predict unknown DTIs based on diffusion states.
The dimensionality reduction framework
Although the diffusion states resulting from the aforementioned RWR process characterizes the underlying topological context and inherent connection profiles of each drug or protein node in the network, they may not be entirely accurate, partially due to the low-quality and high-dimensionality of biological data. For example, a small number of missing or fake interactions in the network can significantly affect the results of the diffusion process [31]. Moreover, it is generally inconvenient to directly use the high dimensional diffusion states as topological features in prediction tasks, especially in our heterogeneous network-based prediction task. To address this issue, DTINet employs a dimensionality reduction scheme, called diffusion component analysis (DCA), to reduce the dimensionality of feature space and capture those important topological features from the diffusion states. The key idea of DCA is to obtain informative but low dimensional vector representations, which encode the connectivity relations and topological properties of each node in the heterogeneous network. Akin to principal component analysis (PCA), which seeks the intrinsic low-dimensional linear structure of the data to best explain the variance, DCA learns a low-dimensional vector representation for all nodes such that their connectivity patterns in the heterogeneous network are best interpreted. We give a brief description of the DCA framework below.
With the goal of denoise and dimensionality reduction, DCA approximates the obtained diffusion state distribution si with a multinomial logistic model parameterized by a low-dimensional vector representation whose dimensionality is much lower than that of the original n-dimensional vector representing the diffusion states. Specifically, the probability assigned to node j in the diffusion state of node i is now modeled as
 where ∀i, xi, wi ∈ ℝd for d ≪ n. We refer to wi as the context feature and xi as the node feature for node i, both describing the topological properties of the network. If xi and wj point to a similar direction and thus have a large inner product, it is likely that node j is frequently visited in a random walk starting from node i. DCA takes a set of the observed diffusion states S = {s1,…, sn} as input and optimizes over w and x for all nodes, using the Kullback-Leibler (KL) divergence (also called relative entropy) to guide the optimization, that is,
where ∀i, xi, wi ∈ ℝd for d ≪ n. We refer to wi as the context feature and xi as the node feature for node i, both describing the topological properties of the network. If xi and wj point to a similar direction and thus have a large inner product, it is likely that node j is frequently visited in a random walk starting from node i. DCA takes a set of the observed diffusion states S = {s1,…, sn} as input and optimizes over w and x for all nodes, using the Kullback-Leibler (KL) divergence (also called relative entropy) to guide the optimization, that is,
 where DKL(· || ·) denotes the KL-divergence between two distributions. The DCA framework uses a standard quasi-Newton method L-BFGS [80] to solve this optimization problem.
where DKL(· || ·) denotes the KL-divergence between two distributions. The DCA framework uses a standard quasi-Newton method L-BFGS [80] to solve this optimization problem.
Integration of heterogeneous network information
The above dimensionality reduction framework can be naturally extended to integrate multiple network data from heterogeneous sources. Given K similarity networks in a heterogeneous framework constructed from diverse information (Supplementary Information), DCA first performs RWR on individual networks separately and then obtains the network-specific diffusion states si(k) for each node i in every network k. After that, it also constructs a multinomial logistic distribution to model the diffusion states:
 where each node i is assigned with a network-specific vector representation wi(k), which represents the context feature of node i in network k, and the node feature vectors xi are allowed to be shared globally across all K networks. Finally, DCA optimizes the following objective function,
where each node i is assigned with a network-specific vector representation wi(k), which represents the context feature of node i in network k, and the node feature vectors xi are allowed to be shared globally across all K networks. Finally, DCA optimizes the following objective function,
 which can also be solved by the quasi-Newton L-BFGS method [80]. Although the divergence terms of individual networks are given equal weights in the above objective function, it is possible to weight them differently to emphasize the relative importance of individual networks. To make the DCA framework more scalable to large biological networks, DTINet employs an extended version of DCA, called clusDCA [69], which uses an alternative objective function that can be optimized efficiently based on singular value decomposition (SVD) (Supplementary Information).
which can also be solved by the quasi-Newton L-BFGS method [80]. Although the divergence terms of individual networks are given equal weights in the above objective function, it is possible to weight them differently to emphasize the relative importance of individual networks. To make the DCA framework more scalable to large biological networks, DTINet employs an extended version of DCA, called clusDCA [69], which uses an alternative objective function that can be optimized efficiently based on singular value decomposition (SVD) (Supplementary Information).
2.2 Projection from drug space onto target space
We use the low-dimensional vector representations of both drug and protein features obtained from compact feature learning to predict new drug-target interactions. Based on the intuition that geometric proximity in the feature vector space may reflect the functional relevance, we apply a matrix completion approach [43] to obtain a projection matrix that maps the low-dimensional feature vectors from drug space onto protein space, such that the projected feature vectors of drugs are geometrically close to the vectors of their known interacting proteins. The insight behind this is that the drugs (or proteins) with similar topological properties in the heterogeneous network are more likely to be functionally correlated. For example, those drugs that are close in the directions of their feature vectors are more likely to share the same target, and vice versa. Based on this intuition, we can fully exploit previous knowledge of known DTIs to predict unknown DTIs.
Formally, we use X = [x1,…,xNd]T, xi ∈ ℝfd, i = 1, …,Nd to denote the matrix representation of the drug features (i.e., each row i represents the corresponding feature vector of drug i), and Y = [y1,…,yNt]T, yi ∈ ℝft, i = 1, …, Nt, to denote the matrix representation of the protein features (i.e., each row i represents the corresponding feature vector of protien i), where Nd and Nt stand for the numbers of drugs and proteins, respectively (Figure 1). Let P be a drug-target interaction matrix, where each entry Pij = 1 if drug i is known to interact with protein j, and Pij = 0 otherwise. We set up a bilinear function to learn the projection matrix Z between drug space and target space to predict the unknown drug-target interactions in P (i.e., those zero-valued entries). In particular, the bilinear function is formulated as XZYT ≈ P, where P ∈ ℝNd × Nt stands for the known drug-target interaction matrix, X ∈ ℝNd × fd, Y ∈ ℝNt × ft are obtained from the compact feature learning stage (i.e., the network diffusion and dimensionality reduction processes), and Z ∈ ℝfd × ft is the projection matrix to be learned. We then use the formula below to measure the likelihood of the pairwise interaction score between drug i and protein j:
 where a larger score(i, j) suggests that drug i is more likely to interact with protein j.
where a larger score(i, j) suggests that drug i is more likely to interact with protein j.
Although the projection matrix Z is of dimension fd × ft, there typically exist significant correlations between those feature vectors of drugs or proteins that are geometrically close in space, which can thus greatly reduce the number of effective parameters required in Z to model drug-target interactions. To take into account this issue, we impose a low-rank constraint on Z to learn only a small number of latent factors, by considering a low-rank decomposition of the form Z = GHT, where G ∈ ℝfd × fk and H ∈ ℝft × fk. This low-rank constraint not only alleviates the over fitting problem but also computationally benefits the optimization process [78]. The optimization problem with such a low-rank constraint on the original projection matrix Z is NP-hard to solve. A standard relaxation of the low-rank constraint is to minimizing the trace norm (i.e., sum of singular values) of the matrix Z = GHT, which is equivalent to minimize  . Therefore, factoring Z into G and H can be accomplished by solving the following optimization problem by alternating minimization [43]:
. Therefore, factoring Z into G and H can be accomplished by solving the following optimization problem by alternating minimization [43]:

3 Results
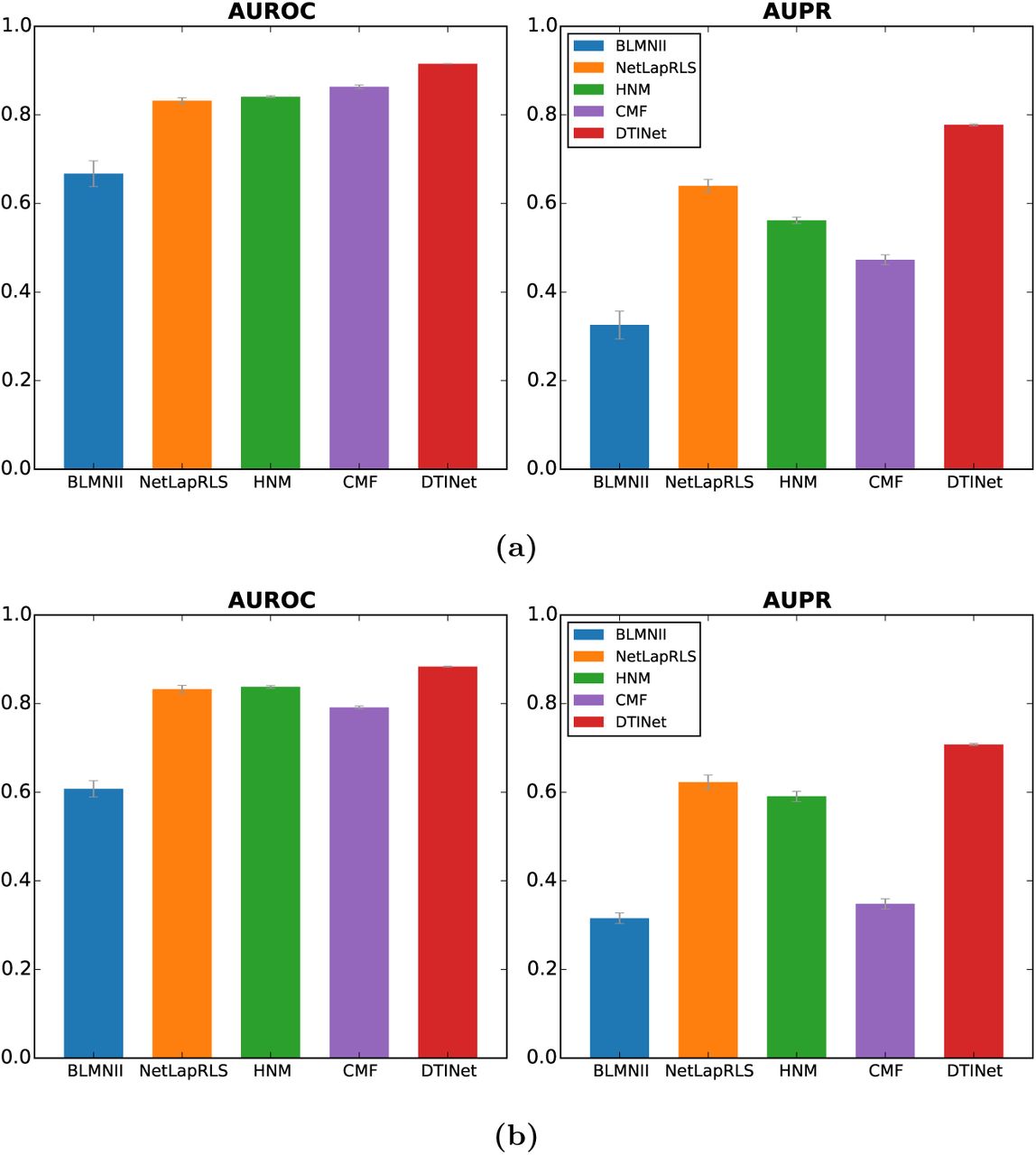
Compiling various curated public drug-related databases, we constructed a heterogeneous network, which includes 12,015 nodes and 1,895,445 edges in total, for predicting missing drug-target interactions (Figure 2a). The heterogeneous network integrates four types of nodes (i.e., drugs, proteins, diseases and side-effects) and six types of edges (i.e., drug-protein interactions, drug-drug interactions, drug-disease associations, drug-side-effect associations, protein-disease associations and protein-protein interactions). We compared DTINet with four state-of-the-art methods of DTI prediction methods, including BLMNII [39], NetLapRLS [76], HNM [70] and CMF [79]. The area under the receiver operating characteristic curve (AUROC) and the area under the precision recall curve (AUPR) were used to assess the performance of each DTI prediction method. A detailed description of the dataset and experimental settings can be found in Supplementary Information.

(a) Overview of the heterogeneous network constructed from diverse information to predict drug-target interactions. (b) DTINet outperforms other state-of-the-art methods for DTI prediction.
3.1 DTINet yields accurate drug-target interaction prediction
We first evaluated the prediction performance of DTINet using ten independent trials of ten-fold cross-validation procedure, in which a randomly chosen subset of 10% of the known interacting drug-target pairs and a matching number of randomly sampled non-interacting pairs were held out as the test set, and the remaining 90% known interactions and a matching number of randomly sampled non-interacting pairs were used to train the model. Our comparative results showed that DTINet consistently outperformed other existing methods in terms of both AUROC and AUPR scores (Figure 2b). For example, DTINet achieved an AUROC of 91.41% and an AUPR of 93.22%, which were 5.9% and 5.7% higher than the second best method, respectively. We found that DTINet had a clear improvement in prediction performance over the single network based approaches, i.e., BLMNII and NetLapRLS. Compared with other integrative methods, e.g., HNM, which predicts DTIs based on a modified version of random walk in a complete heterogeneous network, DTINet achieved 6.9% higher AUROC (85.51% for HNM) and 5.9% higher AUPR (87.98% for HNM), presumably due to the fact that HNM only uses the original diffusion states for prediction, which suffer from noise in the data and are not entirely accurate, while DTINet applies a novel dimensionality reduction on the diffusion states and thus is able to capture the underlying structural properties of the heterogeneous network.
To mimic a practical situation in which a drug-target interaction matrix is often sparsely labeled with only a few known DTIs, we also performed an additional ten-fold cross-validation test (Figure S3a), in which a much larger set of non-interacting drug-target pairs were included, such that the known drug-target interactions composed only 10% of the training or test dataset. This additional test showed that DTINet can still achieve decent performance and outperforms other prediction methods, even when only sparsely labeled DTIs are available to train the model. More specifically, DTINet achieved AUROC 91.52% and AUPR 77.72% on this skewed dataset, which were 6.0% and 21.5% higher than the second best baseline method, respectively. We also want to highlight the pronounced gap between DTINet and other prediction methods in terms of AUPR (138.7%, 21.5%, 38.4% and 64.4% higher than BLMNII, NetLapRLS, HNM and CMF, respectively). As studied in a previous work [15, 6, 66], AUROC is likely to be an overoptimistic metric to evaluate the performance of an algorithm in DTI prediction task, especially on highly-skewed data, while AUPR can provide a better assessment in this scenario. The noticeable performance improvement of DTINet in terms of AUPR over other prediction methods demonstrated its superior ability in predicting new drug-target interactions in the sparsely labeled networks.
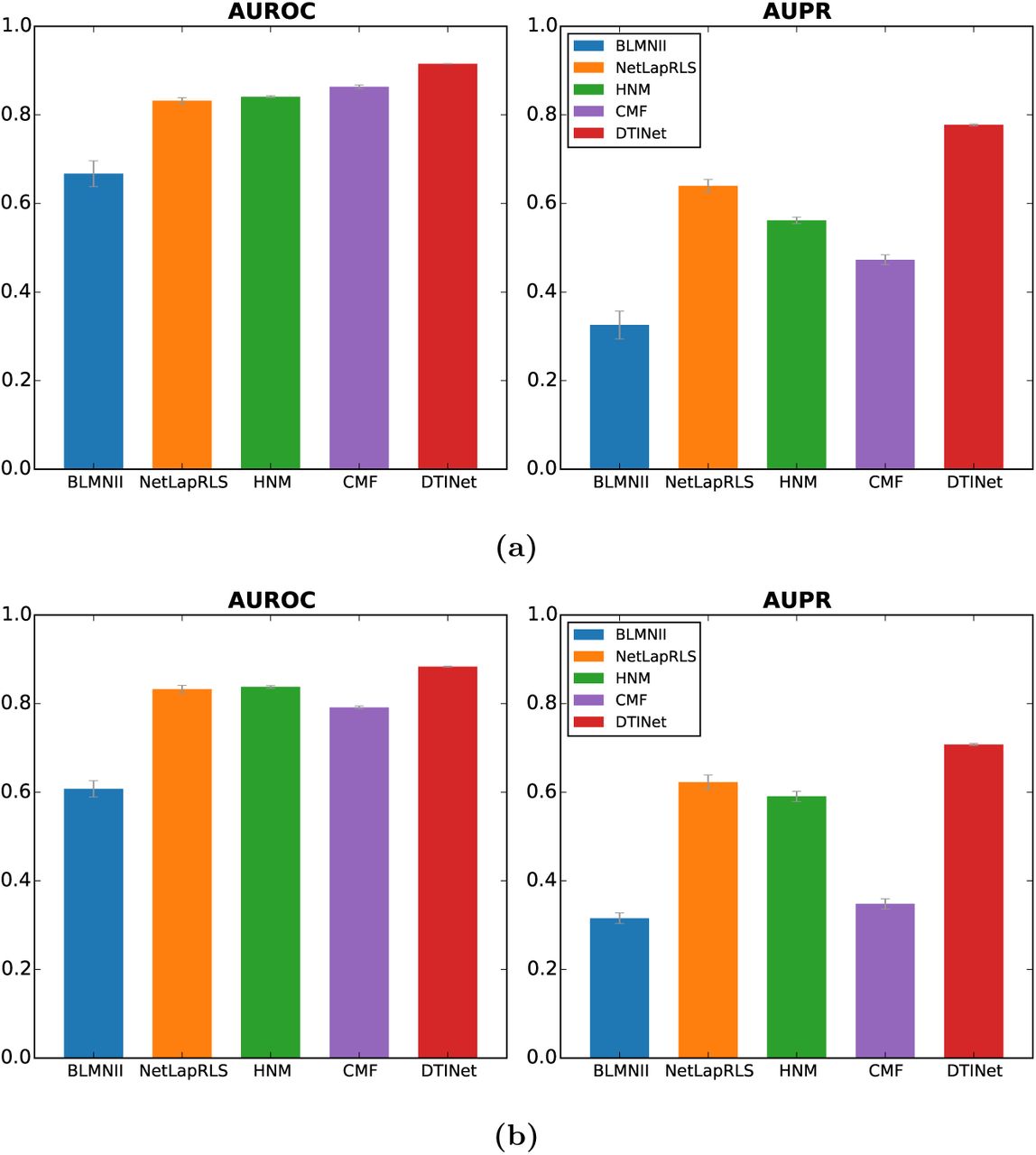
The original collected dataset (Figure 2a, Table S1) may contain homologous proteins with high sequence identity scores, which raised a potential concern that DTINet’s good performance might result from easy predictions, in which the predicted targets had high sequence identity scores with the corresponding homologous proteins in training data. To investigate this issue, as in [71], we performed an additional test, in which we only kept those DTIs in which proteins had sequence identity scores < 40% in both training and test data. More precisely, for each group of proteins that had pairwise sequence identity scores > 40%, we only retained the protein that had the largest number of interacting drugs and removed all other proteins in that group. The removal of homologous proteins reduced the number of known DTIs from 1,923 to 1,332 in the dataset. We then assessed the performance of DTINet and other prediction methods again on this resulting dataset (Figure S2). We found that DTINet was robust to the removal of homologous proteins in training data, and still consistently outperformed other methods on such a dataset. For example, DTINet yielded AUROC 88.22% and AUPR 90.45%, which were significantly higher than the second best method. We also removed homologous proteins in the skewed dataset and compared the performance of DTINet to that of other baseline methods, and still observed superior performance of DTINet over others under this setting (Figure S3b). Taken together, these results demonstrated the superiority of DTINet in predicting novel DTIs, allowing us to find new DTIs that were not present in the original dataset (see the next section).
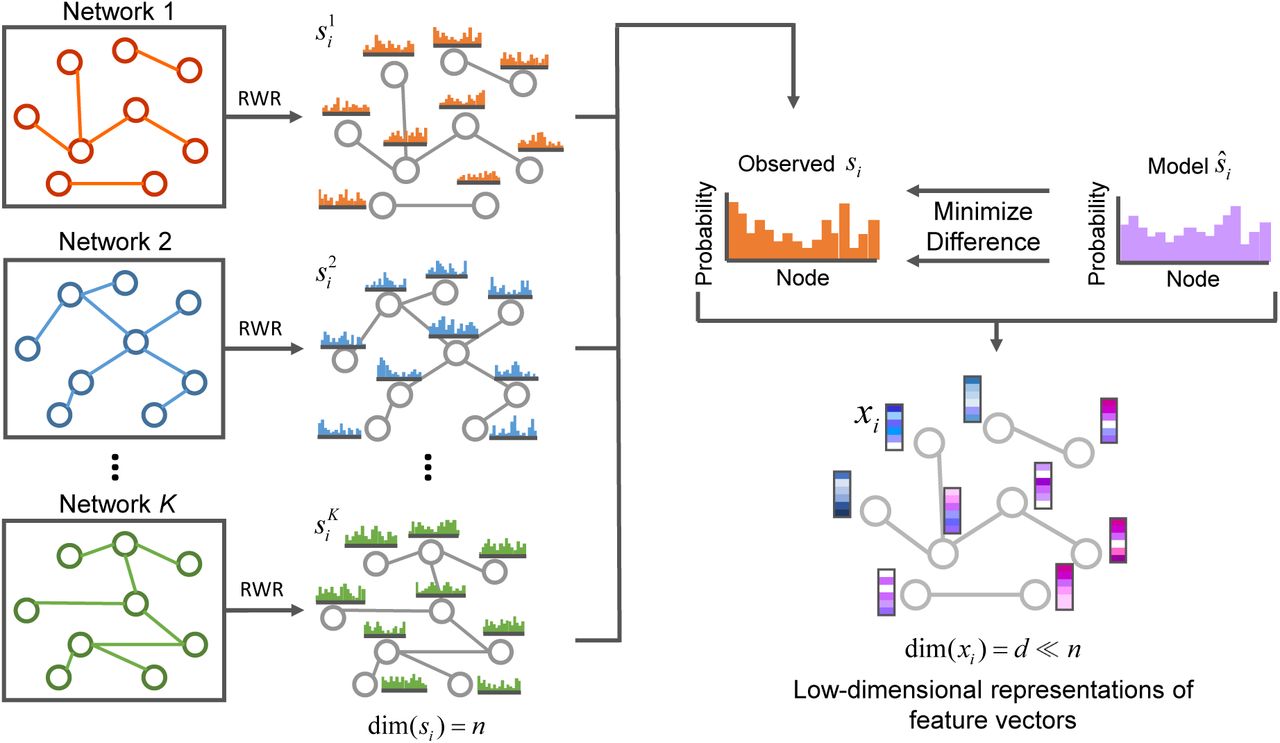
Schematic illustration of compact feature learning. The random walk with restart (RWR) algorithm is first used to compute the diffusion states of individual networks. Then the low-dimensional representations of feature vectors for individual nodes are obtained by minimizing the difference between the diffusion states si and the parameterized multinomial logistic models ŝi. The learned low-dimensional feature vectors encode the relational properties (e.g., similarity), association information and topological context of each node in the heterogeneous network. More details can be found in the main text.

DTINet outperforms other state-of-the-art methods for DTI prediction on a dataset in which homologous proteins were excluded. We performed a ten-fold cross-validation procedure to compare the prediction performance of DTINet to that of four state-of-the-art DTI prediction methods, i.e., HNM, CMF, and the extended versions of BLMNII and NetLapRLS. Performance of each method was assessed by both the area under ROC curve (AUROC) and the area under precision-recall curve (AUPRC). All results were summarized over 10 trials. A pair of two proteins are said to be homologous if their sequence identity score is above 40%.
Performance comparison between DTINet and other state-of-the-art methods on a skewed dataset. The number of randomly chosen non-interacting drug-target pairs (i.e., negative samples) was 10 times more than the number of known interacting drug-target pairs (i.e., positive samples). All results were summarized over 10 trials of ten-fold cross-validation. (a) All methods were trained and tested on the original collected dataset (see the main text), without removing any homologous proteins. (b) All methods were trained and tested on a modified dataset, in which homologous proteins were excluded. The cutoff of sequence similarity score 40% was used to define a pair of homologous proteins.
Our further comparative study showed that integrating multiple networks derived from the feature vectors of drugs or proteins by DTINet can greatly improve the prediction performance over individual single networks (Figure S4). Our comparison demonstrated that, even without multiple networks integration, DITNet still outperformed the state-of-the-art single network based method NetLapRLS on individual similarity networks. This result emphasised DTINet’s ability to fully exploit useful topological information from high-dimensional and noisy network data via a compact feature learning procedure, even only given a single network as input. In addition, we observed that DTINet achieved much better prediction performance than NetLapRLS, when integrating multiple networks into a heterogeneous one (Supplementary Information). These results indicated that integrating multiple networks into DTI prediction is not a trivial task, while the network integration procedure of DTINet can simultaneously and effectively capture the underlying topological structures of multiple networks, leading to the improved accuracy of DTI prediction.

A comparative study on the prediction performance of DTINet and NetLapRLS on individual networks and their integration. (a) The test results on individual similarity networks of drugs and their integration, where Sdrugd, Sdiseased, Ssed and Schemd represent the similarity networks in which the similarity score between a pair of drug nodes was computed based on the profiles of drug-drug interactions, drug-disease associations, drug-side-effect associations and chemical structures, respectively. (b) Tests on individual similarity networks of proteins and their integration, where Sproteinp, Sdiseasep and Sseqp represent the similarity networks in which the similarity score between a pair of protein nodes was computed based on the profiles of protein-protein interactions, protein-disease associations and primary sequences, respectively. An extended version of NetLapRLS (see Supplementary Information text) was used to combine all similarity networks to perform DTI prediction. All results were summarized over 10 trials of ten-fold cross-validation.
3.2 DTINet identifies novel drug-target interactions
Next, we analyzed the novel drug-target interactions predicted by DTInet, which have not been reported in existing databases or previous literatures (to the best of our knowledge). The DrugBank database [74] only indicates that clozapine, an antipsychotic drug for treating schizoaffective disorder, can interact with dopamine (DRD) receptors, 5-hydroxytryptamine (HTR) receptors, histamine receptors (HRH), alpha-adrenergic (ADRA) receptors and muscarinic acetylcholine receptors (CHRM1). Our new predictions showed that clozapine can also act on the gamma-aminobutyric acid (GABA) receptors, an essential family of channel proteins that modulate the cognitive functions (Figure 3b. This new prediction can be supported by the previous studies which showed that clozapine can have a direct interaction with the GABA B-subtype (GABA-B) receptors [75] and antagonize the GABA A-subtype (GABA-A) receptors in the cortex [72].

Network visualization of the drug-target interactions predicted by DTINet. (a) Visualization of the overall drug-target interaction network involving the top 150 predictions. Target and drugs are shown in purple circles and yellow boxes, respectively. (b) Network visualization of several examples of novel DTI predictions which can be supported by known experimental or clinical evidence in the literature. The drugs are shown in yellow boxes, while different families of their interacting targets are shown in circles with different colors. In both (a) and (b), known drug-target interactions are marked by grey edges, while the new predicted interactions are shown by red edges.
Chlordiazepoxide, nitrazepam, estazolam and flurazepam are benzodiazepines serving as a class of psychoactive drugs, which are believed to act on the GABA-A receptors [54]. The glycine receptors (GlyRs) are ligand-gated transmembrane ion channel proteins in the central nervous system that play important roles in a wide range of physiological functions, such as the inhibitory synaptic transmission in the brain stem and spinal cord [38]. Our new predictions implied that these benzodiazepine drugs can also interact with the glycine receptors subunit alpha-2 GLRA2 (Figure 3b). This finding agreed with the previous electrophysiological study [58] which indicated that benzodiazepines, such as chlordiazepoxide and nitrazepam, can block the alpha2-containing GlyRs in the embryonic mouse hippocampal neurons through a low-affinity binding manner. Our new predictions along with the previous experimental evidence in [58] may provide important clues for revealing the mechanisms of drug action for benzodiazepines in the central nervous system. In addition, the interaction between clozapine and GLRA2 predicted by DTINet (Figure 3b) was consistent with the previous known experimental results that clozapine is a non-competitive antagonist of GlyRs in the rat hippocampal neurons and thus may contribute to the side-effects associated with the clozapine treatment [37].
Thioridazine is an antipsychotic drug that was widely used to treat schizophrenia and psychosis [59]. The dopamine transporter (also known as the dopamine active transporter, DAT or SLC6A3) is a membrane-spanning protein that mediates the neurotransmission of dopamine from the synapse into neurons and has become an important target for a variety of pharmacologically-active drugs [9]. Our new prediction indicated that there exists an interaction between thioridazine and the dopamine transporter (Figure 3b). Although we did not find direct experimental evidence in the literature to verify this new predicted drug-target interaction, it may be supported from the following two facts. First, thioridazine has been known as a substrate and an inhibitor of the enzyme cytochrome P450 2D6 (CYP2D6) [74, 47]. Second, the enzyme CYP2D6 and the dopamine transporter share a large degree of structural and functional homogeneity [63, 23, 52]. Thus, we can speculate that thioridazine can also act on the dopamine transporter based on these two known evidences.
Chlorpropamide has been known as a first generation sulfonylurea drug that is mainly used to treat the type 2 diabetes mellitus [74]. The subunit Kir6.2 of the ATP-sensitive inward rectifier potassium channel (KCNJ11) is an integral membrane protein that plays important roles in a wide range of physiologic responses, and its mutations are related to many diseases, such as congenital hyperinsulinism [55]. Our prediction showed that chlorpropamide can interact with the KCNJ11 protein (Figure 3b). This predicted drug-target interaction may be supported by the known clinical evidence that sulfonylureas are usually effective drugs for treating most diabetes patients associated with the KCNJ11 mutations [45, 3].
Next, we focused on those novel drug-target interactions among the list of top 150 predictions from DTINet, for which we rarely found known experimental support in the literature. Among the list of these top 150 predictions, most of the new predicted DTIs were relevant (i.e., connected) to the previous known interactions except the interactions between three drugs, including telmisartan, chlorpropamide and alendronate, and the prostaglandin-endoperoxide synthase (PTGS) proteins, which are also called cyclooxygenase (COX) proteins (Figure 3a). COX is a family of enzymes responsible for prostaglandin biosynthesis [64], and mainly includes COX-1 and COX-2 in human, both of which can be inhibited by nonsteroidal anti-inflammatory drugs (NSAIDs) [48]. Apparently, it was difficult to use the correlations between nodes within the DTI network to explain the predicted interactions between these three drugs and the COX proteins. On the other hand, these new DTIs had relatively high prediction scores in the list of the top 150 predictions (Supplementary File 1). In addition, the COX proteins provide a class of important targets in a wide range of inflammatory diseases [40]. Despite the existence of numerous known NSAIDs used as COX inhibitors, many of them are associated with the cardiovascular side-effects [28, 61]. Thus, it is always important to identify alternative COX inhibitors from existing drugs with less side-effects. Given these facts, it would be interesting to see whether the predicted interactions between these three drugs and the COX proteins can be further validated.
Among the aforementioned three drugs, telmisartan has been known as an angiotensin II receptor antagonist that can be used to treat hypertension [21], chlorpropamide has been known as a sulfonylurea drug that acts by increasing insulin to treat type 2 diabetes mellitus [13], and alendronate has been known as a bisphosphonate drug mainly used for treating bone disease, such as osteoporosis and osteogenesis imperfect [4, 16]. Despite our current understanding about the functions of COX-1 and COX-2 proteins and the known indications of telmisartan, chlorpropamide and alendronate, it still remains largely unknown whether these three drugs can also interact with the COX proteins. According to the top 150 predictions by DTINet (Figure 3a and Supplementary File 1), these three drugs can act on the COX proteins. We will further present our validation results on the predicted interactions between these three drugs and COX proteins in the next sections.
3.3 Computational docking suggests the binding modes for the predicted drug-target interactions
We preformed both computational docking and experimental assays to validate the new predict interactions between COX proteins and three drugs, including telmisartan, alendronate and chlorpropamide. Here, we mainly present the docking results, and will provide the experimental validation results in the next section. In our structure-based modeling studies, we used the docking program Autodock [42] to infer the possible binding modes of the new predicted interactions between three drugs (i.e., telmisartan, chlorpropamide and alendronate) and the COX proteins.
Our docking results showed that these three drugs were able to dock to the structures of both COX-1 (PDB ID: 3kk6) and COX-2 (PDB ID: 3qmo), and displayed different binding patterns (Figure 4). In particular, all three drugs were fitted into the active sites of both COX-1 and COX-2. More specifically, chlorpropamide displayed similar configurations when binding to COX-1 and COX-2 (Figures 4a and 4b), by forming hydrogen bonds with both residues R120 and Y355, which created a conserved pocket as in those for common NSAIDs [49, 67]. On the other hand, the substitution of V119 in COX-1 by S119 in COX-2 allowed the formation of a different hydrogen bond network in the binding pocket. Moreover, telmisartan and alendronate interacted with residue S530 in addition to residues R120 and Y355 when docked to COX-1 (Figures 4c and 4e), while they were both able to bind to residue S119 when docked to COX-2 (Figures 4d and 4f). Thus, a subtle difference between the binding pockets of those two enzymes may result in different binding modes even for the same drug. These docking results may provide important hints for understanding the structural basis of the predicted drug-target interactions and thus help reveal the underlying molecular mechanisms of drug action.

The docked poses for the predicted interactions between three drugs (i.e., chlorpropamide, alendronate and telmisartan) and the COX proteins (i.e., COX-1 and COX-2). (a) Chlorpromamide vs. COX-1; (b) Chlorpromamide vs. COX-2; (c) Alendronnate vs. COX-1; (d) Alendronnate vs. COX-2; (e) Telmisartan vs. COX-1; (f) Telmisartan vs. COX-2. The protein structures of COX-1 and COX-2 were downloaded from the Protein Data Bank (PDB IDs 3kk6 and 3qmo for COX-1 and COX-2, respectively). The structures of the small molecules were obtained from the ZINC [25]. Hydrogen bonds were computed by PyMOL [51] and represented by the red and yellow dashed lines in COX-1 and COX-2, respectively.
3.4 Experimental validation of the top-ranked drug-target interactions predicted by DTINet
We further conducted experimental assays to validate the new predicted interactions between the above three drugs, including telmisartan, alendronate and chlorpropamide, and the COX-1 and COX-2 proteins, for which we rarely found other known experimental support in the literature. In the above section, we had performed computational docking to demonstrate that these three drugs can bind to the COX proteins. Here, we further carried out the COX inhibition assays and examined the changes in the gene expressions of the proinflammatory factors after drug treatment (Supplementary Information) to validate these predicted drug-target interactions and demonstrate the new potential applications of these drugs in preventing inflammatory diseases.
We sought to experimentally validate the bioactivities and selectivities of the COX inhibitors predicted by DTINet. First, we tested their inhibitory potencies on the mouse kidney lysates. Similar dose-dependent repression of COX activity was observed for the three drugs (Figures 5a-5c). The IC50 values of telmisartan, alendronate and chlorpropamide for COX activity were measured at 56.14μM 160.2μ and 289.5 μM, respectively. The measured IC50 values of the three drugs especially telmisartan were comparable to those of many common NSAIDs, such as celecoxib (COX-1: 82 μM; COX-2: 6.8 μM), ibuprofen (COX-1: 12 μM, COX-2: 80 μM) and rofecoxib (COX-1: >100 μM; COX-2: 25 μM) [26, 27]. Probably alendronate and chlorpropamide were relatively weak inhibitors of COX. It is worth noting that the order of the experimentally measured IC50 values of IC50s of these three drugs was consistent with the ranking of prediction scores in DTINet (Supplementary File 1).

Inhibitory effects of telmisartan, chlorpropamide and alendronate on COX activity in mouse kidney and macrophage lysates. (a)-(c) Inhibition rates of telmisartan, chlorpropamide and alendronate using the mouse kidney lysate. (d) and (e) The relative COX activity inhibition rates of telmisartan, chlorpropamide and alendronate on COX-1 and COX-2, using the tissue extracts from both kidney (d) and macrophage (e) lysates. Here, data show the mean with the standard deviation of three independent experiments, each of which was performed with triplicates.
Next, the tissue extracts from the mouse kidney and the peritoneal macrophages were used for COX selective inhibition assays. Relative inhibition of COX-1 and COX-2 activities was distinguished using SC-560, a potent and selective COX-1 inhibitor, and Dup-697, a potent and time-dependent of COX-2 inhibitor, respectively. Overall, the tests on the tissue extracts from mouse kidney showed that telmisartan and alen dronate preferably inhibited COX-1 (68% and 64%, respectively) over COX-2 (32% and 36%, respectively), while chlorpropamide had a slightly higher inhibition rate on COX-2 (54%) than on COX-1 (46%) (Figure 5d). Similar patterns of COX inhibition selectivity with these drugs were also observed in the peritoneal macrophages (Figure 5e). Overall, the above inhibition assays showed that these three drugs identified by DTINet had a certain level of inhibition affinity and binding selectivity on the family of COX proteins.
The COX inhibitors have been extensively used as nonsteroidal anti-inflammatory drugs (NSAIDs), thus we further tested the effects of the above three drugs on inflammatory responses and thus examined their potential applications in treating inflammatory diseases. Lipopolysaccharide (LPS) was used to stimulate the cultured peritoneal macrophages for the cellular inflammation model. In addition to those three drugs (i.e., telmisartan, chlorpropamide and alendronate) predicted by DTINet, we also considered the potent COX-2 inhibitor Dup-697 and the well-known NSAID ibuprofen for comparison.
A large amount of proinflammatory factors can be generated during the inflammation process [2]. We consequently tested whether the three drugs can suppress the expression of various inflammatory factors in response to LPS stimulation (Figure S7). For TNF-α and IL-6, telmisartan exhibited strong inhibitory effect on the LPS induced expression (Figures S7a and S7b). Meanwhile, the induction of the important cytokine IL-1,β was also attenuated by each of the three drugs in the peritoneal macrophages (Figure S7c). In particular, telmisartan displayed the strongest suppression effect on IL-1,β among all COX inhibitors. For IL-12p35, although both alendronate and telmisartan significantly inhibited its production induced by LPS, telmisartan had much stronger suppression effect than other COX inhibitors (Figure S7d). The LPS-induced production of the immunological defensive factors such as CXCL-1 and iNOS were significantly restrained by the treatment of any of these three drugs (Figures S7e and S7f), which was similar to the results of both Dup-697 and ibuprofen. In summary, these results showed that telmisartan, chlorpropamide and alendronate can reduce the expressions proinflammatory factors in mouse peritoneal macrophages. The observed anti-inflammation effects of these three drugs further extended the above inhibition assay studies and demonstrated their potential applications in preventing inflammatory disease.

Robustness of DTINet with respect to the number of dimensions of feature vectors. We evaluated the sensitivity of the prediction performance of DTINet with respect to different numbers of dimensions of the feature vectors of drugs (a) and proteins (b). We tested the dimensions of the feature vectors of drugs (fd) and proteins (ft) in a range that are roughly equal to 10%-30% of the dimensionality of the original vectors describing the diffusion states. DTINet had stable prediction performance over a wide range the dimensions of the feature vectors. Prediction performance was evaluated in terms of both the area under the receiver operating characteristic curve (ROC) and the area under the precision recall (PR) curve. All results were summarized over 10 trials of ten-fold cross-validation.

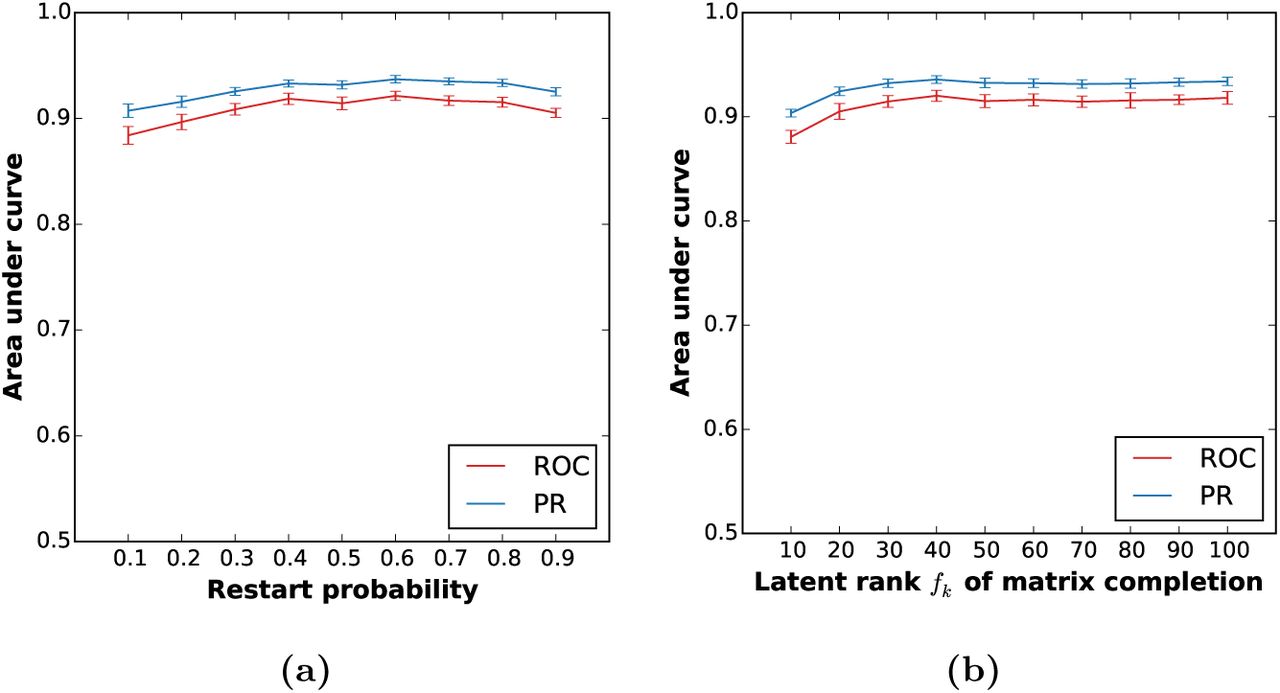
Robustness of the prediction performance of DTINet with respect to the restart probability and the latent rank of matrix completion. We tested the prediction performance of DTINet with respect to different values of the restart probability (a) and the latent rank of matrix completion (b). DTINet was robust to different choices of the restart probability and the latent rank parameter. Prediction performance was evaluated in terms of both the area under the receiver operating characteristic curve (ROC) and the area under the precision recall (PR) curve. All results were summarized over 10 trials of ten-fold cross-validation.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The real-time PCR (RT-PCR) analysis of the proinflammatory factors on the LPS-stimulated macrophages. (a)–(f) The RT-PCR analysis of mRNA expressions of TNFα, IL-6, IL-1,β, IL-12p35, CXCL-1 and iNOS normalized relative to that of GAPDH, respectively. Control, macrophages without LPS treatment. *: P < 0.05; **: P < 0.01; ***: P < 0.001, compared to the samples without LPS treatment. ##: P < 0.01; ###: P < 0.001, compared to the samples treated with LPS. n=3. Tukey’s multiple comparison test was used. Here, data show the mean with the standard deviation of three independent experiments, each of which was performed with triplicates. The concentrations of the COX inhibitors were determined according to the indications of the assay kits and the previous binding studies in the literature (see Supplementary Information text).
Taken together, the above experimental assays validated the novel interactions between the three drugs (i.e., telmisartan, alendronate and chlorpropamide) and the COX proteins predicted by DTINet, which further demonstrated the accuracy of its prediction results and thus provided strong evidence to support its excellent predictive power. In addition, the experimentally validated interactions between these three drugs and the COX proteins can provide great opportunities for drug repositioning, i.e., finding the new functions (i.e., anti-inflammatory effects) of these drugs, and offer new insights into the understanding of their molecular mechanisms of drug action or side-effects of these drugs.
4 Discussion
The challenge in network integration mainly stems from the complexity and heterogeneity of datasets. The high-dimensional, incomplete and noisy nature of high-throughput biological data further exacerbates the difficulty. To address this issue, DTINet takes a novel dimensionality reduction technique, which first characterizes the topology of each individual network by applying a network diffusion algorithm (e.g., random walk with restart), and then computes a low-dimensional feature vector representation for each node in the networks to approximate the diffusion information. These low-dimensional feature vectors encode both global and local topological properties for all drug or protein nodes in the networks and are readily incor-porable for the downstream predictive models (e.g., matrix completion in this work). We have demonstrated that DTINet can display excellent ability in network integration for accurate DTI prediction and achieve substantial improvement over the previous DTI prediction approaches. Moreover, three novel drug-target pairs predicted by DTINet were also validated by wet-lab experiments, which can provide new insights into the understanding of drug action and drug repositioning.
A future direction of our work is to include more heterogeneous network data in our framework. While we used only four domains (i.e., drugs, proteins, diseases and side-effects) of information in this work, we highlight that DTINet is a scalable framework in that more additional networks can be easily incorporated into the current prediction pipeline. Other biological entities of different types, such as gene expression, pathways, symptoms and Gene Ontology (GO) annotations, can also be integrated into the heterogeneous network for DTI prediction. Although it was only applied to predict missing DTIs in this work, DTINet is a versatile approach and definitely can also be applied to various link prediction problems, e.g., predictions of drug-side-effect associations, drug-drug interactions and protein-disease associations.
Author contributions
Y.L., J.P., L.C. and J.Zeng conceived the research project. J.Z. supervised the research project. Y.L., J.P. and J.Zeng designed the computational pipeline. Y.L. implemented DTINet and performed the model training and prediction validation tasks. X.Z. and L.C. performed the experimental validation task and analyzed the validation results. J. Zhou carried out the computational docking and data analysis tasks. Y.L., X.Z., J.Zhou, J.Y., Y.Z., W.K., L.C. and J.Zeng analyzed the novel prediction results. Y.L. and J.Zeng wrote the manuscript with support from all authors.
Acknowledgments
This work was supported in part by the National Basic Research Program of China (Grant 2011CBA00300 and 2011CBA00301), the National Natural Science Foundation of China (Grant 61033001, 61361136003, 61472205 and 81470839), the China’s Youth 1000-Talent Program, the Beijing Advanced Innovation Center for Structural Biology, and the Tsinghua University Initiative Scientific Research Program (Grant. 20161080086). J.P. received support as an Alfred P. Sloan Research Fellow. We acknowledge the support of NVIDIA Corporation with the donation of the Titan X GPU used for this research.
Footnotes
This paper was selected for oral presentation at RECOMB 2017 and an abstract is published in the conference proceedings.
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].↵
- [72].↵
- [73].↵
- [74].↵
- [75].↵
- [76].↵
- [77].↵
- [78].↵
- [79].↵
- [80].↵




